 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALARB: An Arabic Legal Argument Reasoning Benchmark
Oct 01, 2025We introduce ALARB, a dataset and suite of tasks designed to evaluate the reasoning capabilities of large language models (LLMs) within the Arabic legal domain. While existing Arabic benchmarks cover some knowledge-intensive tasks such as retrieval and understanding, substantial datasets focusing specifically on multistep reasoning for Arabic LLMs, especially in open-ended contexts, are lacking. The dataset comprises over 13K commercial court cases from Saudi Arabia, with each case including the facts presented, the reasoning of the court, the verdict, as well as the cited clauses extracted from the regulatory documents. We define a set of challenging tasks leveraging this dataset and reflecting the complexity of real-world legal reasoning, including verdict prediction, completion of reasoning chains in multistep legal arguments, and identification of relevant regulations based on case facts. We benchmark a representative selection of current open and closed Arabic LLMs on these tasks and demonstrate the dataset's utility for instruction tuning. Notably, we show that instruction-tuning a modest 12B parameter model using ALARB significantly enhances its performance in verdict prediction and Arabic verdict generation, reaching a level comparable to that of GPT-4o.
Turning the Spell Around: Lightweight Alignment Amplification via Rank-One Safety Injection
Aug 28, 2025Safety alignment in Large Language Models (LLMs) often involves mediating internal representations to refuse harmful requests. Recent research has demonstrated that these safety mechanisms can be bypassed by ablating or removing specific representational directions within the model. In this paper, we propose the opposite approach: Rank-One Safety Injection (ROSI), a white-box method that amplifies a model's safety alignment by permanently steering its activations toward the refusal-mediating subspace. ROSI operates as a simple, fine-tuning-free rank-one weight modification applied to all residual stream write matrices. The required safety direction can be computed from a small set of harmful and harmless instruction pairs. We show that ROSI consistently increases safety refusal rates - as evaluated by Llama Guard 3 - while preserving the utility of the model on standard benchmarks such as MMLU, HellaSwag, and Arc. Furthermore, we show that ROSI can also re-align 'uncensored' models by amplifying their own latent safety directions, demonstrating its utility as an effective last-mile safety procedure. Our results suggest that targeted, interpretable weight steering is a cheap and potent mechanism to improve LLM safety, complementing more resource-intensive fine-tuning paradigms.
An Embarrassingly Simple Defense Against LLM Abliteration Attacks
May 25, 2025Large language models (LLMs) are typically aligned to comply with safety guidelines by refusing harmful instructions. A recent attack, termed abliteration, isolates and suppresses the single latent direction most responsible for refusal behavior, enabling the model to generate unethical content. We propose a defense that modifies how models generate refusals. We construct an extended-refusal dataset that contains harmful prompts with a full response that justifies the reason for refusal. We then fine-tune Llama-2-7B-Chat and Qwen2.5-Instruct (1.5B and 3B parameters) on our extended-refusal dataset, and evaluate the resulting systems on a set of harmful prompts. In our experiments, extended-refusal models maintain high refusal rates, dropping at most by 10%, whereas baseline models' refusal rates drop by 70-80% after abliteration. A broad evaluation of safety and utility shows that extended-refusal fine-tuning neutralizes the abliteration attack while preserving general performance.
ArabLegalEval: A Multitask Benchmark for Assessing Arabic Legal Knowledge in Large Language Models
Aug 15, 2024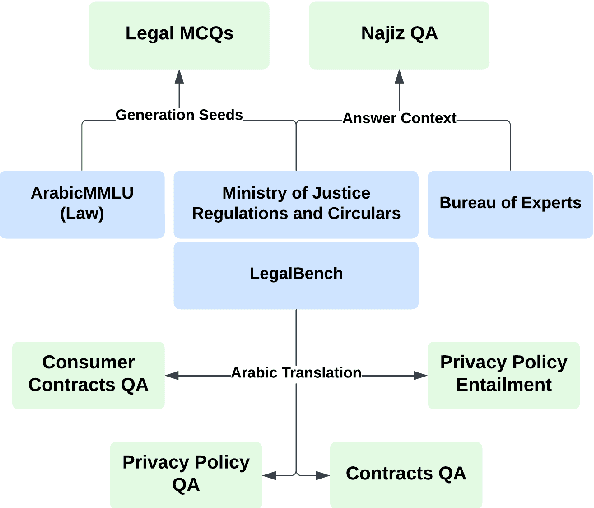

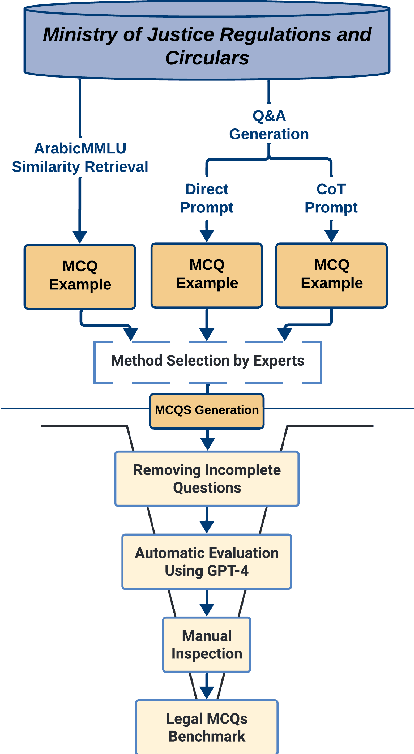

The rapid advancements in Large Language Models (LLMs) have led to significant improvements in various natural language processing tasks. However, the evaluation of LLMs' legal knowledge, particularly in non-English languages such as Arabic, remains under-explored. To address this gap, we introduce ArabLegalEval, a multitask benchmark dataset for assessing the Arabic legal knowledge of LLMs. Inspired by the MMLU and LegalBench datasets, ArabLegalEval consists of multiple tasks sourced from Saudi legal documents and synthesized questions. In this work, we aim to analyze the capabilities required to solve legal problems in Arabic and benchmark the performance of state-of-the-art LLMs. We explore the impact of in-context learning and investigate various evaluation methods. Additionally, we explore workflows for generating questions with automatic validation to enhance the dataset's quality. We benchmark multilingual and Arabic-centric LLMs, such as GPT-4 and Jais, respectively. We also share our methodology for creating the dataset and validation, which can be generalized to other domains. We hope to accelerate AI research in the Arabic Legal domain by releasing the ArabLegalEval dataset and code: https://github.com/Thiqah/ArabLegalEval