 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabLegalEval: A Multitask Benchmark for Assessing Arabic Legal Knowledge in Large Language Models
Paper and Code
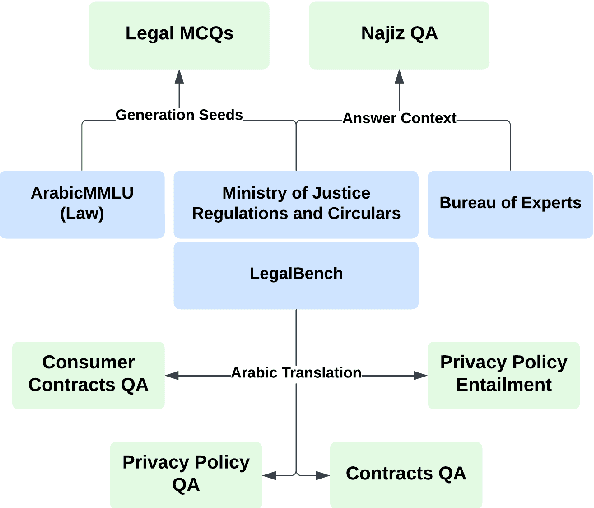

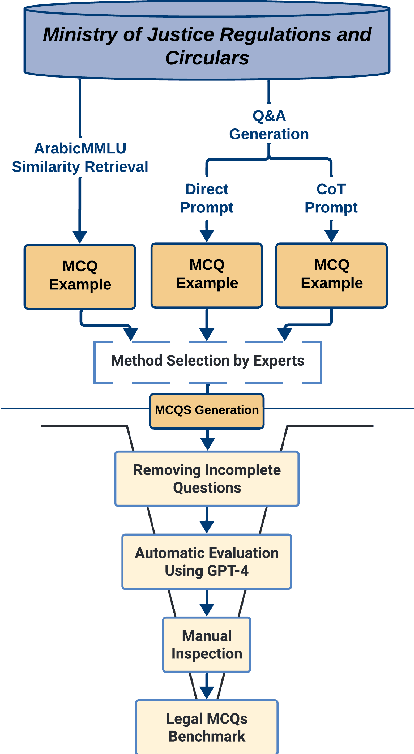

The rapid advancements in Large Language Models (LLMs) have led to significant improvements in various natural language processing tasks. However, the evaluation of LLMs' legal knowledge, particularly in non-English languages such as Arabic, remains under-explored. To address this gap, we introduce ArabLegalEval, a multitask benchmark dataset for assessing the Arabic legal knowledge of LLMs. Inspired by the MMLU and LegalBench datasets, ArabLegalEval consists of multiple tasks sourced from Saudi legal documents and synthesized questions. In this work, we aim to analyze the capabilities required to solve legal problems in Arabic and benchmark the performance of state-of-the-art LLMs. We explore the impact of in-context learning and investigate various evaluation methods. Additionally, we explore workflows for generating questions with automatic validation to enhance the dataset's quality. We benchmark multilingual and Arabic-centric LLMs, such as GPT-4 and Jais, respectively. We also share our methodology for creating the dataset and validation, which can be generalized to other domains. We hope to accelerate AI research in the Arabic Legal domain by releasing the ArabLegalEval dataset and code: https://github.com/Thiqah/ArabLegalEval