 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALARB: An Arabic Legal Argument Reasoning Benchmark
Oct 01, 2025We introduce ALARB, a dataset and suite of tasks designed to evaluate the reasoning capabilities of large language models (LLMs) within the Arabic legal domain. While existing Arabic benchmarks cover some knowledge-intensive tasks such as retrieval and understanding, substantial datasets focusing specifically on multistep reasoning for Arabic LLMs, especially in open-ended contexts, are lacking. The dataset comprises over 13K commercial court cases from Saudi Arabia, with each case including the facts presented, the reasoning of the court, the verdict, as well as the cited clauses extracted from the regulatory documents. We define a set of challenging tasks leveraging this dataset and reflecting the complexity of real-world legal reasoning, including verdict prediction, completion of reasoning chains in multistep legal arguments, and identification of relevant regulations based on case facts. We benchmark a representative selection of current open and closed Arabic LLMs on these tasks and demonstrate the dataset's utility for instruction tuning. Notably, we show that instruction-tuning a modest 12B parameter model using ALARB significantly enhances its performance in verdict prediction and Arabic verdict generation, reaching a level comparable to that of GPT-4o.
Integrated Learning and Optimization for Congestion Management and Profit Maximization in Real-Time Electricity Market
Dec 23, 2024We develop novel integrated learning and optimization (ILO) methodologies to solve economic dispatch (ED) and DC optimal power flow (DCOPF) problems for better economic operation. The optimization problem for ED is formulated with load being an unknown parameter while DCOPF consists of load and power transfer distribution factor (PTDF) matrix as unknown parameters. PTDF represents the incremental variations of real power on transmission lines which occur due to real power transfers between two regions. These values represent a linearized approximation of power flows over the transmission lines. We develop novel ILO formulations to solve post-hoc penalties in electricity market and line congestion problems using ED and DCOPF optimization formulations. Our proposed methodologies capture the real-time electricity market and line congestion behavior to train the regret function which eventually train unknown loads at different buses and line PTDF matrix to achieve the afore-mentioned post-hoc goals. The proposed methodology is compared to sequential learning and optimization (SLO) which train load and PTDF forecasts for accuracy rather than economic operation. Our experimentation prove the superiority of ILO in minimizing the post-hoc penalties in electricity markets and minimizing the line congestion thereby improving the economic operation with noticeable amount.
ArabLegalEval: A Multitask Benchmark for Assessing Arabic Legal Knowledge in Large Language Models
Aug 15, 2024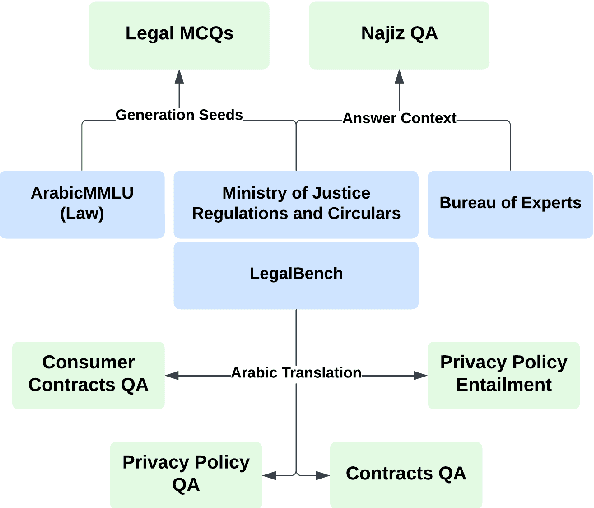

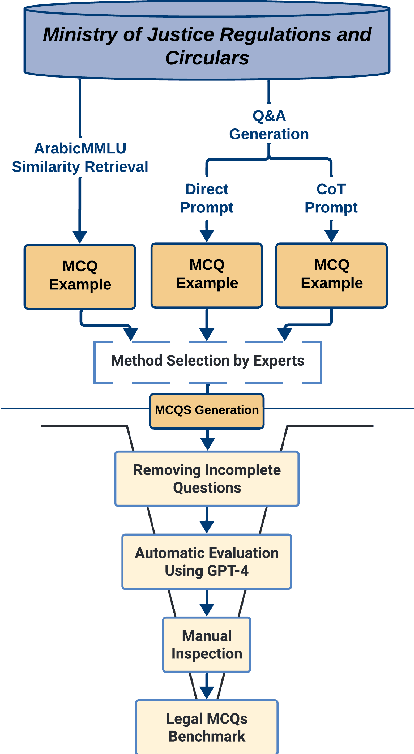

The rapid advancements in Large Language Models (LLMs) have led to significant improvements in various natural language processing tasks. However, the evaluation of LLMs' legal knowledge, particularly in non-English languages such as Arabic, remains under-explored. To address this gap, we introduce ArabLegalEval, a multitask benchmark dataset for assessing the Arabic legal knowledge of LLMs. Inspired by the MMLU and LegalBench datasets, ArabLegalEval consists of multiple tasks sourced from Saudi legal documents and synthesized questions. In this work, we aim to analyze the capabilities required to solve legal problems in Arabic and benchmark the performance of state-of-the-art LLMs. We explore the impact of in-context learning and investigate various evaluation methods. Additionally, we explore workflows for generating questions with automatic validation to enhance the dataset's quality. We benchmark multilingual and Arabic-centric LLMs, such as GPT-4 and Jais, respectively. We also share our methodology for creating the dataset and validation, which can be generalized to other domains. We hope to accelerate AI research in the Arabic Legal domain by releasing the ArabLegalEval dataset and code: https://github.com/Thiqah/ArabLegalEval
Data Assimilation in Chaotic Systems Using Deep Reinforcement Learning
Jan 01, 2024Data assimilation (DA) plays a pivotal role in diverse applications, ranging from climate predictions and weather forecasts to trajectory planning for autonomous vehicles. A prime example is the widely used ensemble Kalman filter (EnKF), which relies on linear updates to minimize variance among the ensemble of forecast states. Recent advancements have seen the emergence of deep learning approaches in this domain, primarily within a supervised learning framework. However, the adaptability of such models to untrained scenarios remains a challenge. In this study, we introduce a novel DA strategy that utilizes reinforcement learning (RL) to apply state corrections using full or partial observations of the state variables. Our investigation focuses on demonstrating this approach to the chaotic Lorenz '63 system, where the agent's objective is to minimize the root-mean-squared error between the observations and corresponding forecast states. Consequently, the agent develops a correction strategy, enhancing model forecasts based on available system state observations. Our strategy employs a stochastic action policy, enabling a Monte Carlo-based DA framework that relies on randomly sampling the policy to generate an ensemble of assimilated realizations. Results demonstrate that the developed RL algorithm performs favorably when compared to the EnKF. Additionally, we illustrate the agent's capability to assimilate non-Gaussian data, addressing a significant limitation of the EnKF.