 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAP: KV-Cache Compression via RoPE-Aligned Pruning
Feb 01, 2026Long-context inference in large language models is increasingly bottlenecked by the memory and compute cost of the KV-Cache. Low-rank factorization compresses KV projections by writing $W \approx A * B$, where A produces latent KV states and B can be absorbed into downstream weights. In modern RoPE-based LLMs, this absorption fails: RoPE forces latent KV states to be reconstructed to full dimension, reintroducing substantial memory and compute overhead. We propose RoPE-Aligned Pruning (RAP), which prunes entire RoPE-aligned column pairs to preserve RoPE's 2x2 rotation structure, restore B absorption, and eliminate reconstruction. Our evaluation on LLaMA-3-8B and Mistral-7B shows that RAP enables joint reduction of KV-Cache, attention parameters, and FLOPs by 20-30%, all at once, while maintaining strong accuracy. Notably, RAP reduces attention latency to 83% (prefill) and 77% (decode) of baseline.
Synthetic Geology -- Structural Geology Meets Deep Learning
Jun 11, 2025

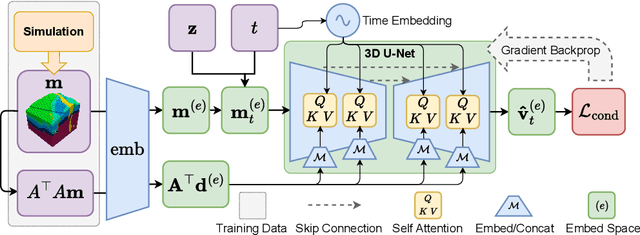
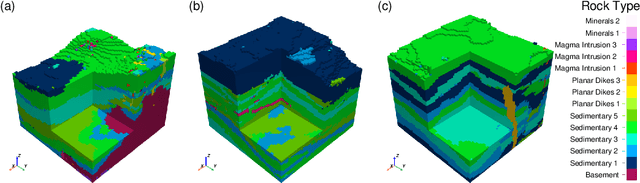
Visualizing the first few kilometers of the Earth's subsurface, a long-standing challenge gating a virtually inexhaustible list of important applications, is coming within reach through deep learning. Building on techniques of generative artificial intelligence applied to voxelated images, we demonstrate a method that extends surface geological data supplemented by boreholes to a three-dimensional subsurface region by training a neural network. The Earth's land area having been extensively mapped for geological features, the bottleneck of this or any related technique is the availability of data below the surface. We close this data gap in the development of subsurface deep learning by designing a synthetic data-generator process that mimics eons of geological activity such as sediment compaction, volcanic intrusion, and tectonic dynamics to produce a virtually limitless number of samples of the near lithosphere. A foundation model trained on such synthetic data is able to generate a 3D image of the subsurface from a previously unseen map of surface topography and geology, showing increasing fidelity with increasing access to borehole data, depicting such structures as layers, faults, folds, dikes, and sills. We illustrate the early promise of the combination of a synthetic lithospheric generator with a trained neural network model using generative flow matching. Ultimately, such models will be fine-tuned on data from applicable campaigns, such as mineral prospecting in a given region. Though useful in itself, a regionally fine-tuned models may be employed not as an end but as a means: as an AI-based regularizer in a more traditional inverse problem application, in which the objective function represents the mismatch of additional data with physical models with applications in resource exploration, hazard assessment, and geotechnical engineering.
Constructing artificial life and materials scientists with accelerated AI using Deep AndersoNN
Jul 29, 2024Deep AndersoNN accelerates AI by exploiting the continuum limit as the number of explicit layers in a neural network approaches infinity and can be taken as a single implicit layer, known as a deep equilibrium model. Solving for deep equilibrium model parameters reduces to a nonlinear fixed point iteration problem, enabling the use of vector-to-vector iterative solvers and windowing techniques, such as Anderson extrapolation, for accelerating convergence to the fixed point deep equilibrium. Here we show that Deep AndersoNN achieves up to an order of magnitude of speed-up in training and inference. The method is demonstrated on density functional theory results for industrial applications by constructing artificial life and materials `scientists' capable of classifying drugs as strongly or weakly polar, metal-organic frameworks by pore size, and crystalline materials as metals, semiconductors, and insulators, using graph images of node-neighbor representations transformed from atom-bond networks. Results exhibit accuracy up to 98\% and showcase synergy between Deep AndersoNN and machine learning capabilities of modern computing architectures, such as GPUs, for accelerated computational life and materials science by quickly identifying structure-property relationships. This paves the way for saving up to 90\% of compute required for AI, reducing its carbon footprint by up to 60 gigatons per year by 2030, and scaling above memory limits of explicit neural networks in life and materials science, and beyond.
PETScML: Second-order solvers for training regression problems in Scientific Machine Learning
Mar 18, 2024In recent years, we have witnessed the emergence of scientific machine learning as a data-driven tool for the analysis, by means of deep-learning techniques, of data produced by computational science and engineering applications. At the core of these methods is the supervised training algorithm to learn the neural network realization, a highly non-convex optimization problem that is usually solved using stochastic gradient methods. However, distinct from deep-learning practice, scientific machine-learning training problems feature a much larger volume of smooth data and better characterizations of the empirical risk functions, which make them suited for conventional solvers for unconstrained optimization. We introduce a lightweight software framework built on top of the Portable and Extensible Toolkit for Scientific computation to bridge the gap between deep-learning software and conventional solvers for unconstrained minimization. We empirically demonstrate the superior efficacy of a trust region method based on the Gauss-Newton approximation of the Hessian in improving the generalization errors arising from regression tasks when learning surrogate models for a wide range of scientific machine-learning techniques and test cases. All the conventional second-order solvers tested, including L-BFGS and inexact Newton with line-search, compare favorably, either in terms of cost or accuracy, with the adaptive first-order methods used to validate the surrogate models.