 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RBF Value Functions for Continuous Control
Feb 05, 2020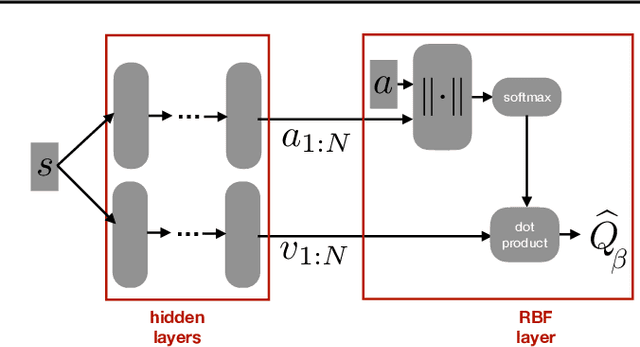
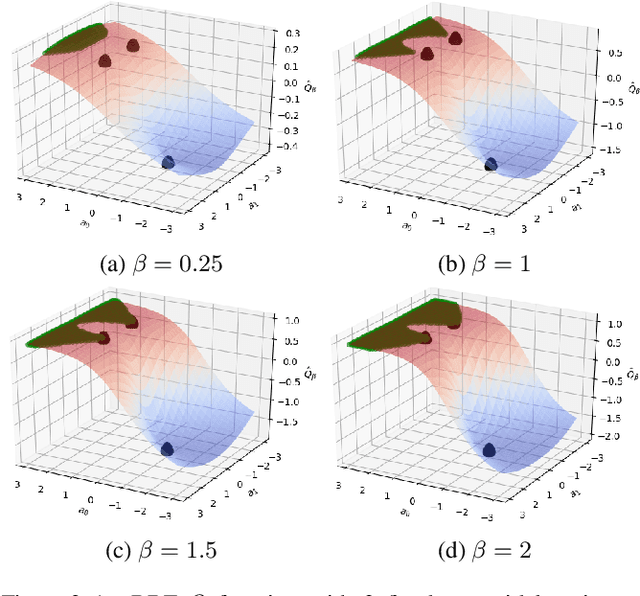
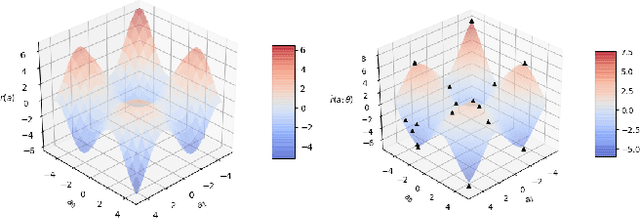
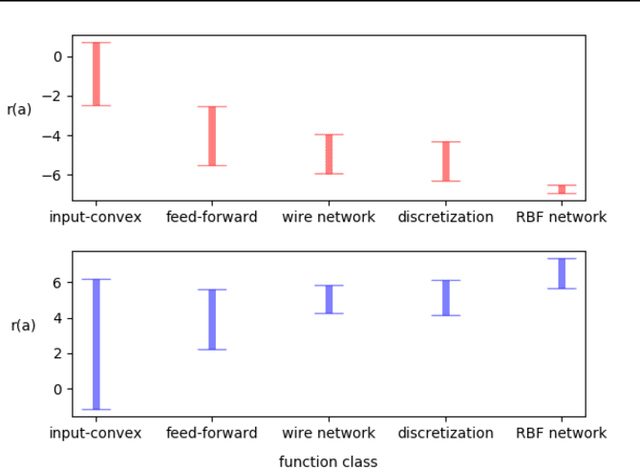
A core operation in reinforcement learning (RL) is finding an action that is optimal with respect to a learned state-action value function. This operation is often challenging when the learned value function takes continuous actions as input. We introduce deep RBF value functions: state-action value functions learned using a deep neural network with a radial-basis function (RBF) output layer. We show that the optimal action with respect to a deep RBF value function can be easily approximated up to any desired accuracy. Moreover, deep RBF value functions can represent any true value function up to any desired accuracy owing to their support for universal function approximation. By learning a deep RBF value function, we extend the standard DQN algorithm to continuous control, and demonstrate that the resultant agent, RBF-DQN, outperforms standard baselines on a set of continuous-action RL problems.
Multi-Pass Q-Networks for Deep Reinforcement Learning with Parameterised Action Spaces
May 10, 2019



Parameterised actions in reinforcement learning are composed of discrete actions with continuous action-parameters. This provides a framework for solving complex domains that require combining high-level actions with flexible control. The recent P-DQN algorithm extends deep Q-networks to learn over such action spaces. However, it treats all action-parameters as a single joint input to the Q-network, invalidating its theoretical foundations. We analyse the issues with this approach and propose a novel method, multi-pass deep Q-networks, or MP-DQN, to address them. We empirically demonstrate that MP-DQN significantly outperforms P-DQN and other previous algorithms in terms of data efficiency and converged policy performance on the Platform, Robot Soccer Goal, and Half Field Offense domains.
Planning for Decentralized Control of Multiple Robots Under Uncertainty
Feb 12, 2014
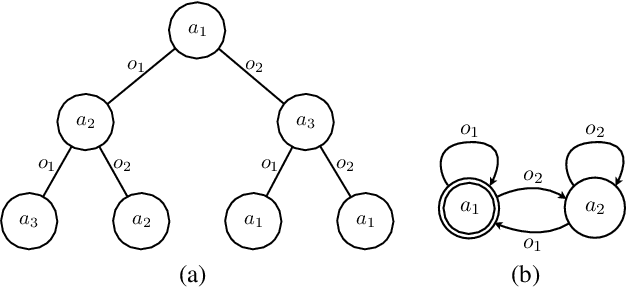
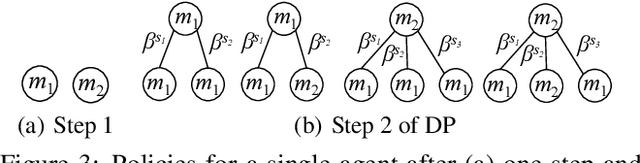

We describe a probabilistic framework for synthesizing control policies for general multi-robot systems, given environment and sensor models and a cost function. Decentralized, partially observable Markov decision processes (Dec-POMDPs) are a general model of decision processes where a team of agents must cooperate to optimize some objective (specified by a shared reward or cost function) in the presence of uncertainty, but where communication limitations mean that the agents cannot share their state, so execution must proceed in a decentralized fashion. While Dec-POMDPs are typically intractable to solve for real-world problems, recent research on the use of macro-actions in Dec-POMDPs has significantly increased the size of problem that can be practically solved as a Dec-POMDP. We describe this general model, and show how, in contrast to most existing methods that are specialized to a particular problem class, it can synthesize control policies that use whatever opportunities for coordination are present in the problem, while balancing off uncertainty in outcomes, sensor information, and information about other agents. We use three variations on a warehouse task to show that a single planner of this type can generate cooperative behavior using task allocation, direct communication, and signaling, as appropriate.