 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RBF Value Functions for Continuous Control
Paper and Code
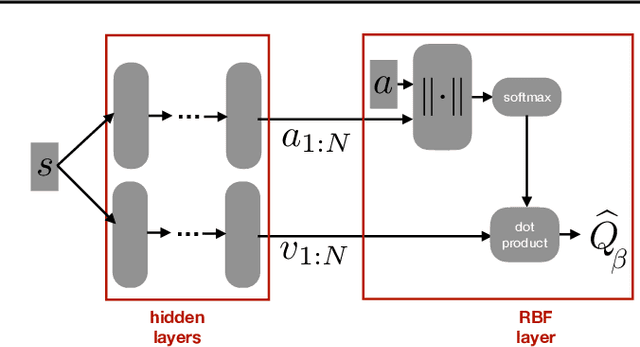
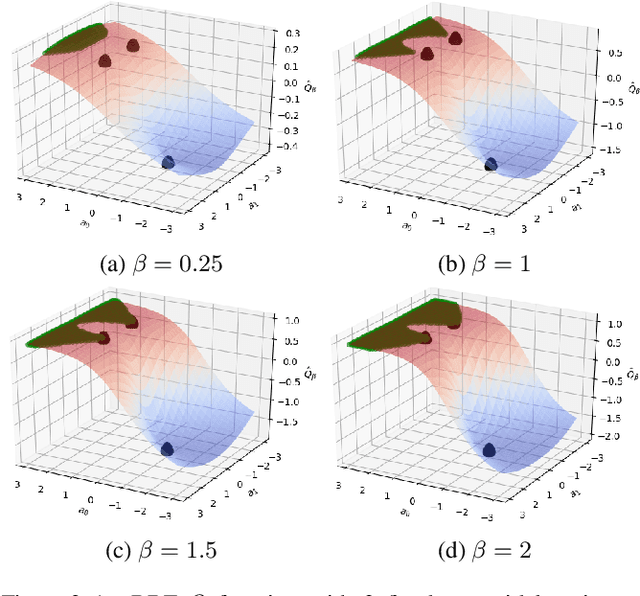
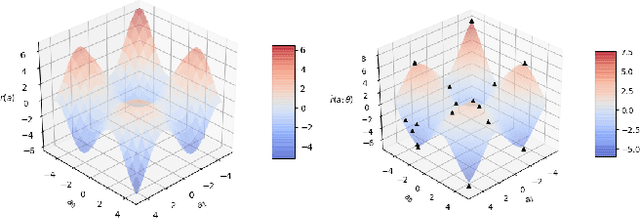
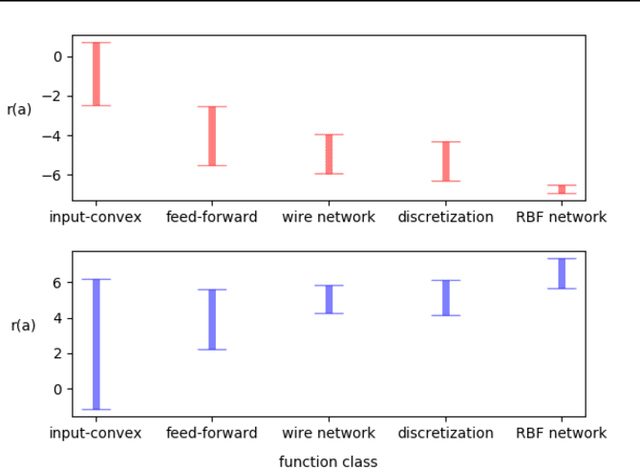
A core operation in reinforcement learning (RL) is finding an action that is optimal with respect to a learned state-action value function. This operation is often challenging when the learned value function takes continuous actions as input. We introduce deep RBF value functions: state-action value functions learned using a deep neural network with a radial-basis function (RBF) output layer. We show that the optimal action with respect to a deep RBF value function can be easily approximated up to any desired accuracy. Moreover, deep RBF value functions can represent any true value function up to any desired accuracy owing to their support for universal function approximation. By learning a deep RBF value function, we extend the standard DQN algorithm to continuous control, and demonstrate that the resultant agent, RBF-DQN, outperforms standard baselines on a set of continuous-action RL problems.