 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RBF Value Functions for Continuous Control
Feb 05, 2020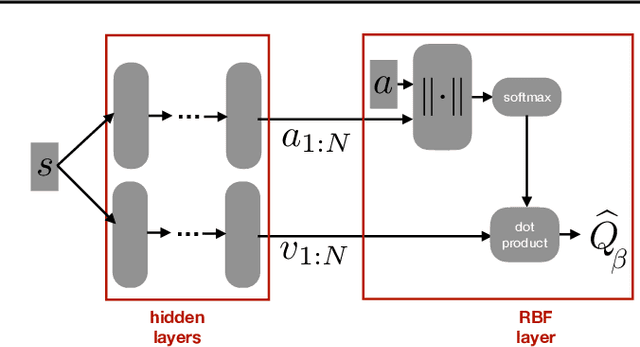
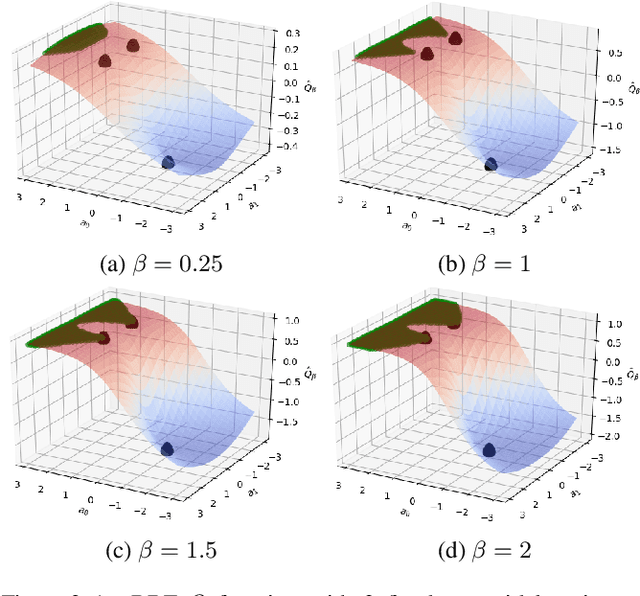
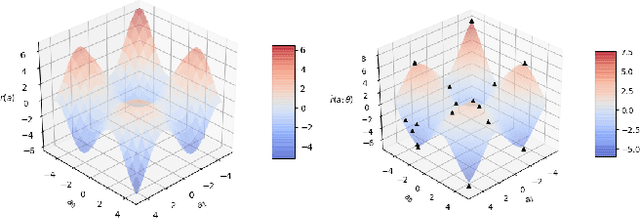
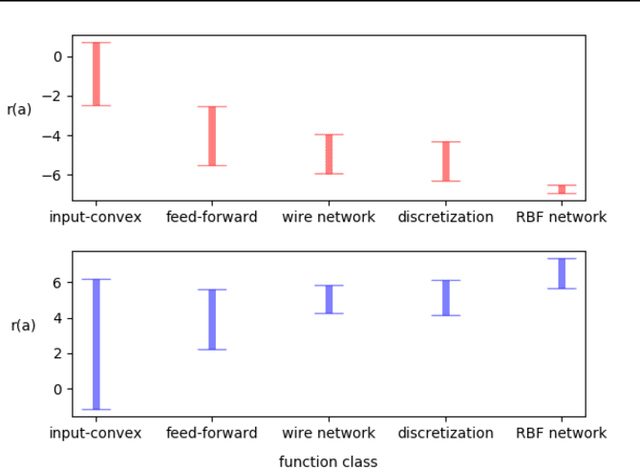
A core operation in reinforcement learning (RL) is finding an action that is optimal with respect to a learned state-action value function. This operation is often challenging when the learned value function takes continuous actions as input. We introduce deep RBF value functions: state-action value functions learned using a deep neural network with a radial-basis function (RBF) output layer. We show that the optimal action with respect to a deep RBF value function can be easily approximated up to any desired accuracy. Moreover, deep RBF value functions can represent any true value function up to any desired accuracy owing to their support for universal function approximation. By learning a deep RBF value function, we extend the standard DQN algorithm to continuous control, and demonstrate that the resultant agent, RBF-DQN, outperforms standard baselines on a set of continuous-action RL problems.
Revisiting the Softmax Bellman Operator: Theoretical Properties and Practical Benefits
Dec 02, 2018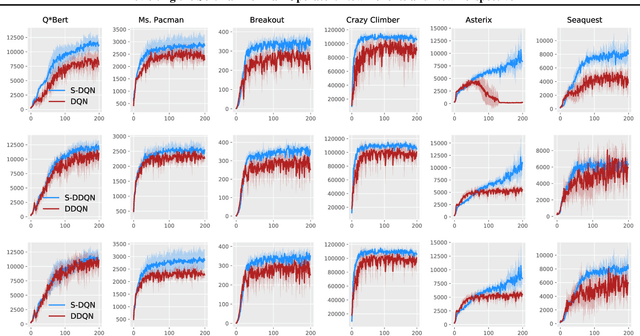
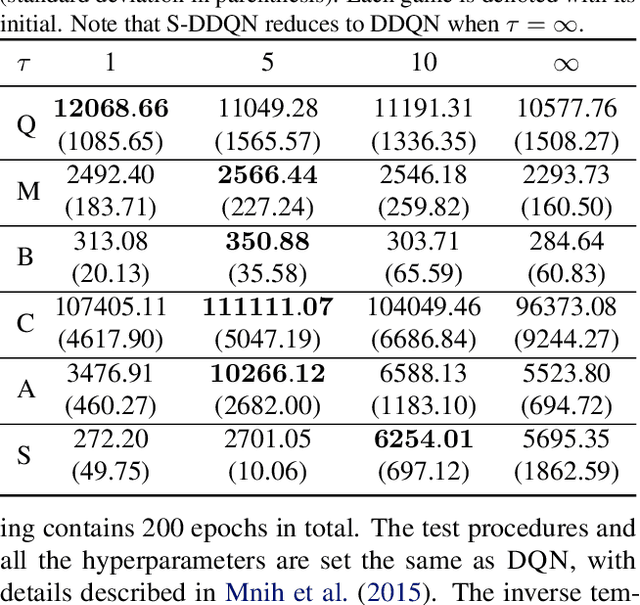
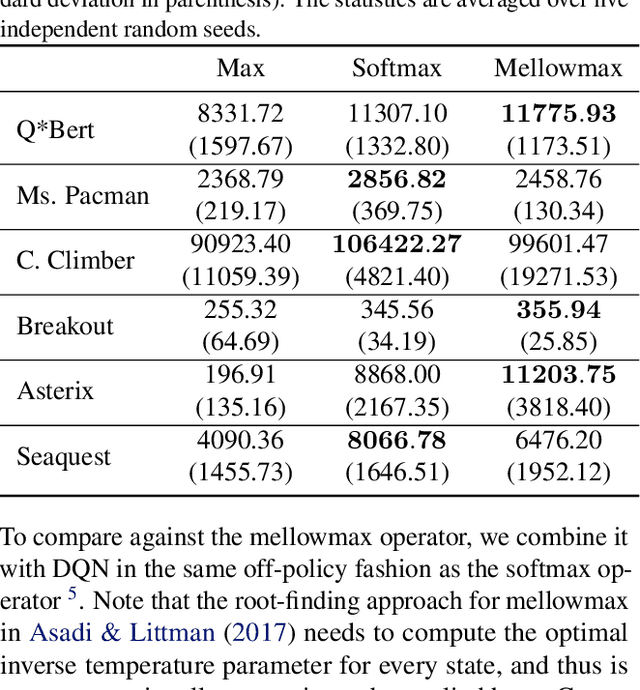
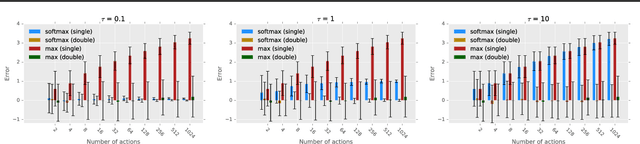
The softmax function has been primarily employed in reinforcement learning (RL) to improve exploration and provide a differentiable approximation to the max function, as also observed in the mellowmax paper by Asadi and Littman. This paper instead focuses on using the softmax function in the Bellman updates, independent of the exploration strategy. Our main theory provides a performance bound for the softmax Bellman operator, and shows it converges to the standard Bellman operator exponentially fast in the inverse temperature parameter. We also prove that under certain conditions, the softmax operator can reduce the overestimation error and the gradient noise. A detailed comparison among different Bellman operators is then presented to show the trade-off when selecting them. We apply the softmax operator to deep RL by combining it with the deep Q-network (DQN) and double DQN algorithms in an off-policy fashion, and demonstrate that these variants can often achieve better performance in several Atari games, and compare favorably to their mellowmax counterpart.