 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocCogCom at SemEval-2020 Task 11: Characterizing and Detecting Propaganda using Sentence-Level Emotional Salience Features
Aug 29, 2020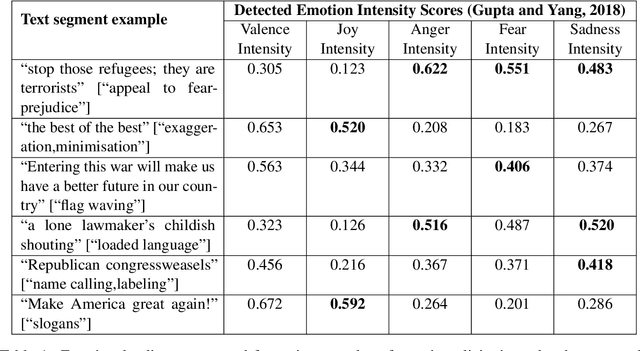
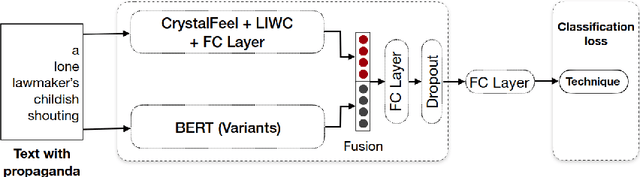
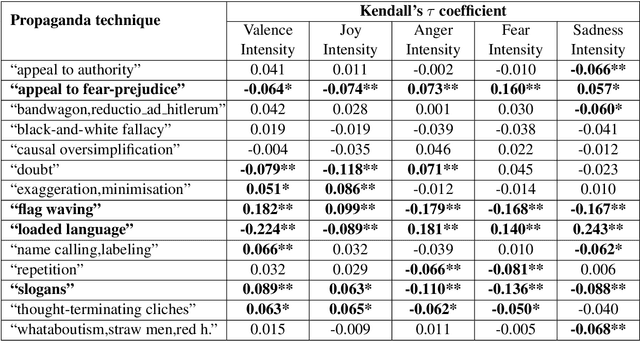
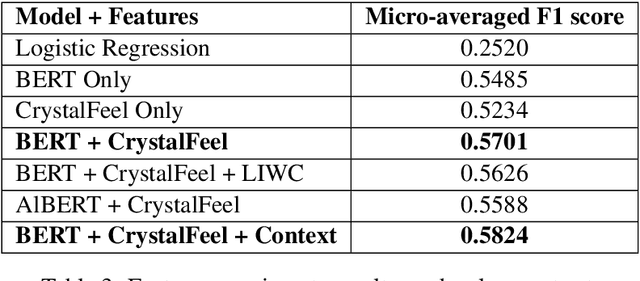
This paper describes a system developed for detecting propaganda techniques from news articles. We focus on examining how emotional salience features extracted from a news segment can help to characterize and predict the presence of propaganda techniques. Correlation analyses surfaced interesting patterns that, for instance, the "loaded language" and "slogan" techniques are negatively associated with valence and joy intensity but are positively associated with anger, fear and sadness intensity. In contrast, "flag waving" and "appeal to fear-prejudice" have the exact opposite pattern. Through predictive experiments, results further indicate that whereas BERT-only features obtained F1-score of 0.548, emotion intensity features and BERT hybrid features were able to obtain F1-score of 0.570, when a simple feedforward network was used as the classifier in both settings. On gold test data, our system obtained micro-averaged F1-score of 0.558 on overall detection efficacy over fourteen propaganda techniques. It performed relatively well in detecting "loaded language" (F1 = 0.772), "name calling and labeling" (F1 = 0.673), "doubt" (F1 = 0.604) and "flag waving" (F1 = 0.543).
Variational Fusion for Multimodal Sentiment Analysis
Aug 13, 2019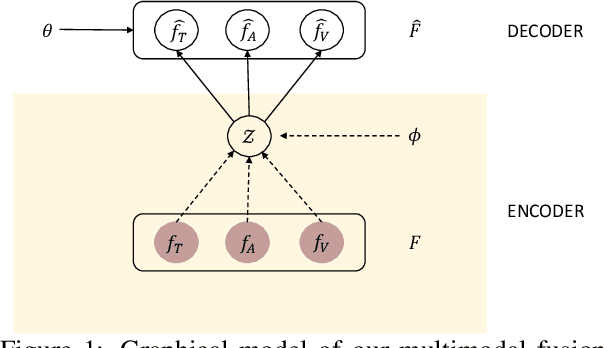

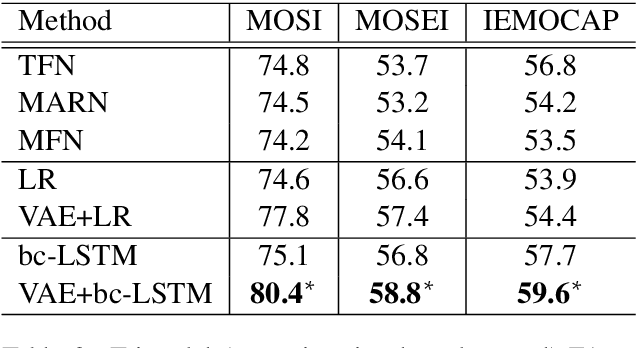
Multimodal fusion is considered a key step in multimodal tasks such as sentiment analysis, emotion detection, question answering, and others. Most of the recent work on multimodal fusion does not guarantee the fidelity of the multimodal representation with respect to the unimodal representations. In this paper, we propose a variational autoencoder-based approach for modality fusion that minimizes information loss between unimodal and multimodal representations. We empirically show that this method outperforms the state-of-the-art methods by a significant margin on several popular datasets.
Towards Verifying Semantic Roles Co-occurrence
Oct 09, 2018

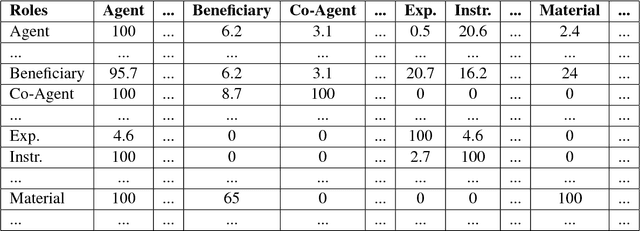
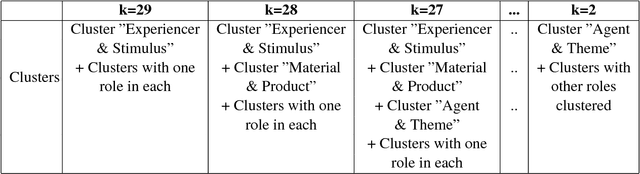
Semantic role theory considers roles as a small universal set of unanalyzed entities. It means that formally there are no restrictions on role combinations. We argue that the semantic roles co-occur in verb representations. It means that there are hidden restrictions on role combinations. To demonstrate that a practical and evidence-based approach has been built on in-depth analysis of the largest verb database VerbNet. The consequences of this approach are considered.
A Deep Learning Approach for Multimodal Deception Detection
Mar 01, 2018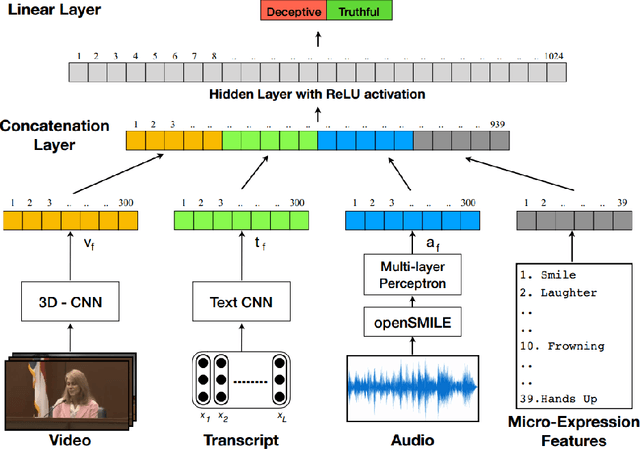
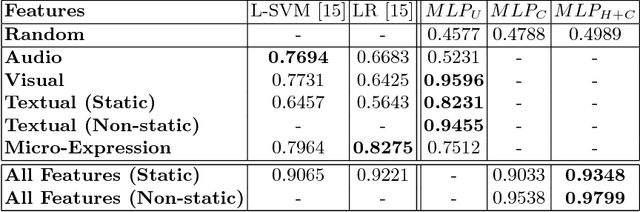
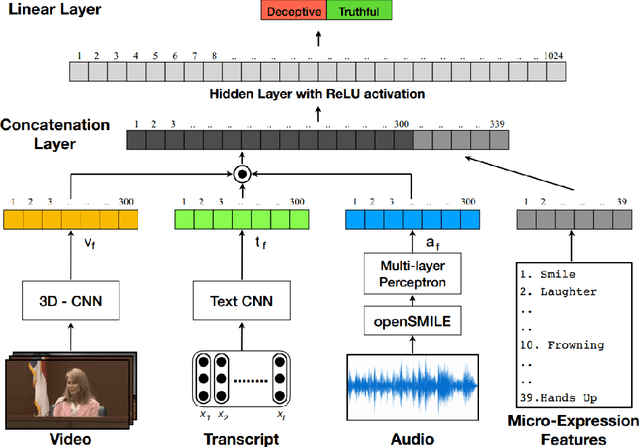

Automatic deception detection is an important task that has gained momentum in computational linguistics due to its potential applications. In this paper, we propose a simple yet tough to beat multi-modal neural model for deception detection. By combining features from different modalities such as video, audio, and text along with Micro-Expression features, we show that detecting deception in real life videos can be more accurate. Experimental results on a dataset of real-life deception videos show that our model outperforms existing techniques for deception detection with an accuracy of 96.14% and ROC-AUC of 0.9799.