 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow People Respond to the COVID-19 Pandemic on Twitter: A Comparative Analysis of Emotional Expressions from US and India
Mar 19, 2023The COVID-19 pandemic has claimed millions of lives worldwide and elicited heightened emotions. This study examines the expression of various emotions pertaining to COVID-19 in the United States and India as manifested in over 54 million tweets, covering the fifteen-month period from February 2020 through April 2021, a period which includes the beginnings of the huge and disastrous increase in COVID-19 cases that started to ravage India in March 2021. Employing pre-trained emotion analysis and topic modeling algorithms, four distinct types of emotions (fear, anger, happiness, and sadness) and their time- and location-associated variations were examined. Results revealed significant country differences and temporal changes in the relative proportions of fear, anger, and happiness, with fear declining and anger and happiness fluctuating in 2020 until new situations over the first four months of 2021 reversed the trends. Detected differences are discussed briefly in terms of the latent topics revealed and through the lens of appraisal theories of emotions, and the implications of the findings are discussed.
SocCogCom at SemEval-2020 Task 11: Characterizing and Detecting Propaganda using Sentence-Level Emotional Salience Features
Aug 29, 2020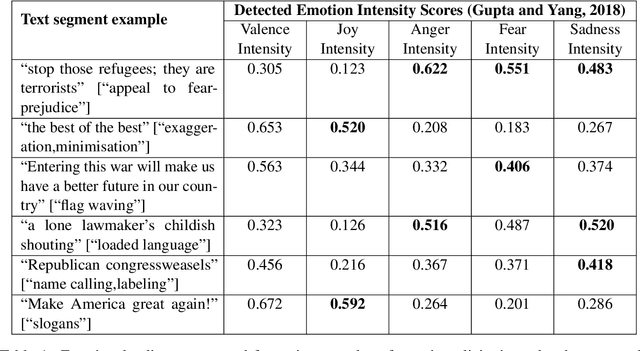
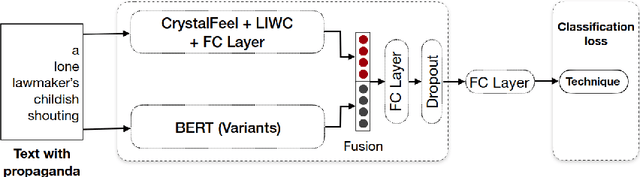
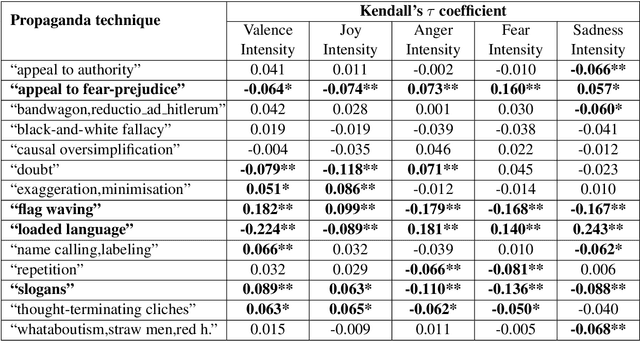
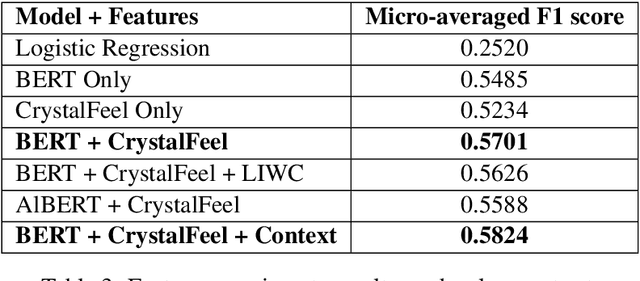
This paper describes a system developed for detecting propaganda techniques from news articles. We focus on examining how emotional salience features extracted from a news segment can help to characterize and predict the presence of propaganda techniques. Correlation analyses surfaced interesting patterns that, for instance, the "loaded language" and "slogan" techniques are negatively associated with valence and joy intensity but are positively associated with anger, fear and sadness intensity. In contrast, "flag waving" and "appeal to fear-prejudice" have the exact opposite pattern. Through predictive experiments, results further indicate that whereas BERT-only features obtained F1-score of 0.548, emotion intensity features and BERT hybrid features were able to obtain F1-score of 0.570, when a simple feedforward network was used as the classifier in both settings. On gold test data, our system obtained micro-averaged F1-score of 0.558 on overall detection efficacy over fourteen propaganda techniques. It performed relatively well in detecting "loaded language" (F1 = 0.772), "name calling and labeling" (F1 = 0.673), "doubt" (F1 = 0.604) and "flag waving" (F1 = 0.543).
COVID-19 Twitter Dataset with Latent Topics, Sentiments and Emotions Attributes
Aug 07, 2020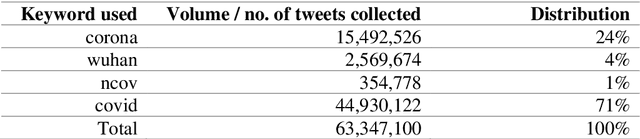
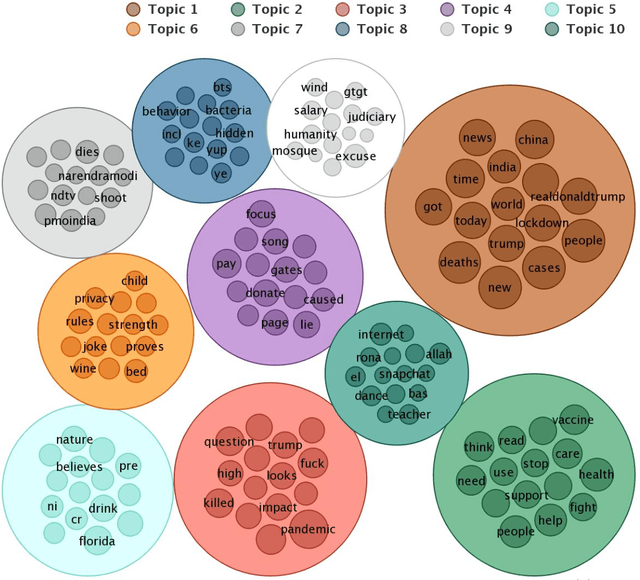
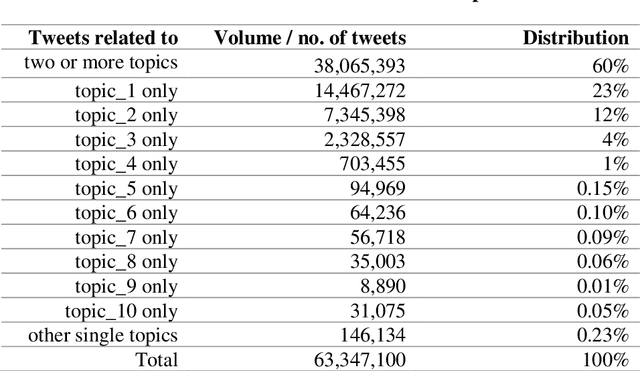
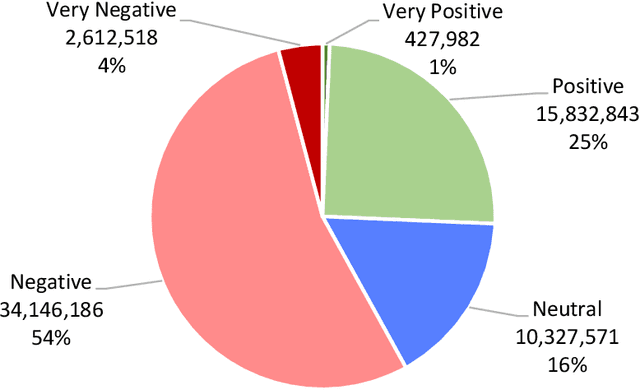
This paper presents a large annotated dataset on public expressions related to the COVID-19 pandemic. Through Twitter's standard search application programming interface, we retrieved over 63 million coronavirus-related public posts from more than 13 million unique users since 28 January to 1 July 2020. Using natural language processing techniques and machine learning based algorithms, we annotated each public tweet with seventeen latent semantic attributes, including: 1) ten binary attributes indicating the tweet's relevance or irrelevance to ten detected topics, 2) five quantitative attributes indicating the degree of intensity of the valence or sentiment (from extremely negative to extremely positive), and the degree of intensity of fear, of anger, of sadness and of joy emotions (from extremely low intensity to extremely high intensity), and 3) two qualitative attributes indicating the sentiment category and the dominant emotion category, respectively. We report basic descriptive statistics around the topics, sentiments and emotions attributes and their temporal distributions, and discuss its possible usage in communication, psychology, public health, economics and epidemiology research.