 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 Twitter Dataset with Latent Topics, Sentiments and Emotions Attributes
Paper and Code
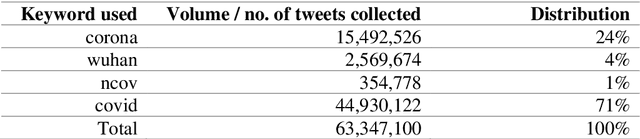
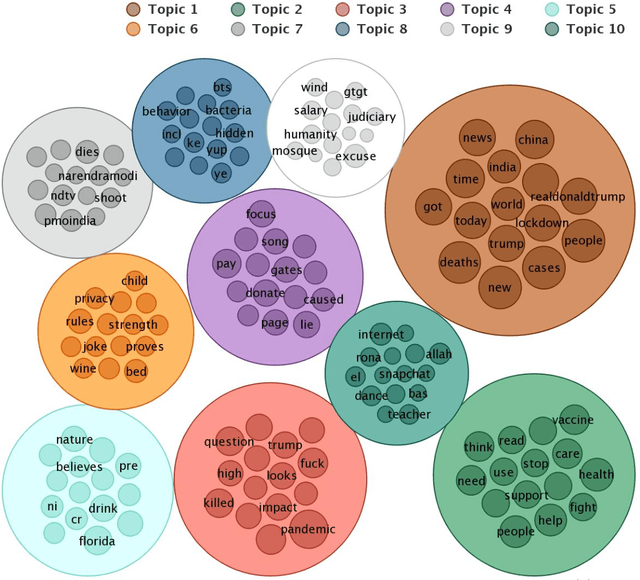
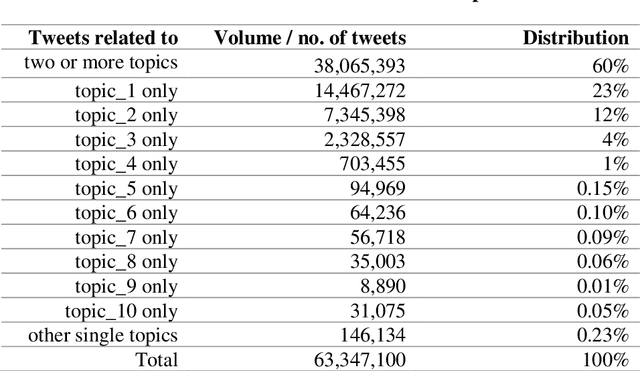
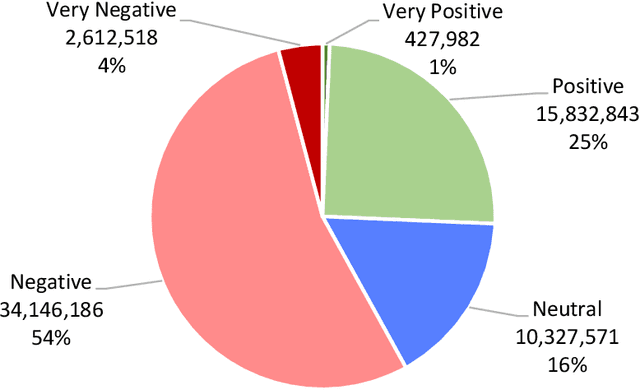
This paper presents a large annotated dataset on public expressions related to the COVID-19 pandemic. Through Twitter's standard search application programming interface, we retrieved over 63 million coronavirus-related public posts from more than 13 million unique users since 28 January to 1 July 2020. Using natural language processing techniques and machine learning based algorithms, we annotated each public tweet with seventeen latent semantic attributes, including: 1) ten binary attributes indicating the tweet's relevance or irrelevance to ten detected topics, 2) five quantitative attributes indicating the degree of intensity of the valence or sentiment (from extremely negative to extremely positive), and the degree of intensity of fear, of anger, of sadness and of joy emotions (from extremely low intensity to extremely high intensity), and 3) two qualitative attributes indicating the sentiment category and the dominant emotion category, respectively. We report basic descriptive statistics around the topics, sentiments and emotions attributes and their temporal distributions, and discuss its possible usage in communication, psychology, public health, economics and epidemiology research.