 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022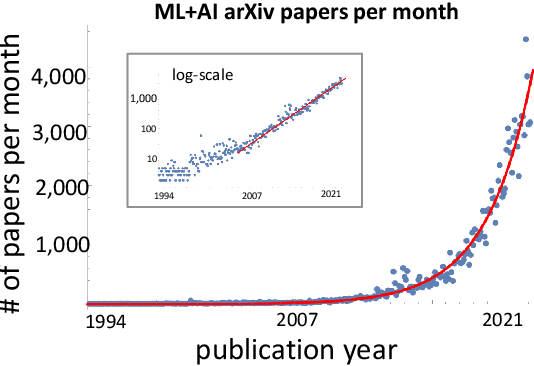
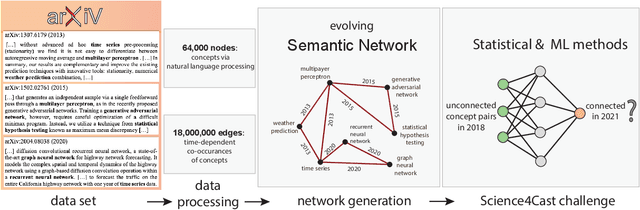
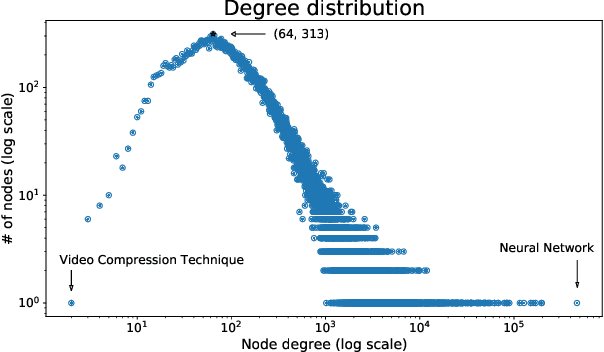
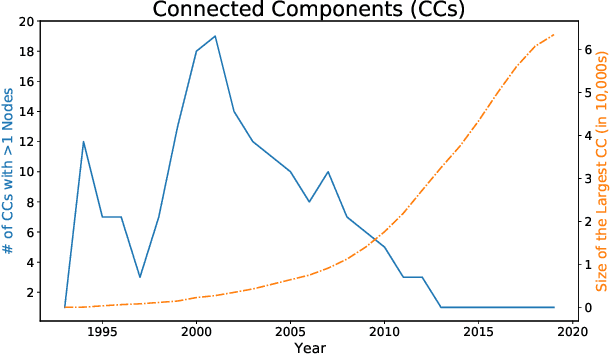
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Link Prediction of Artificial Intelligence Concepts using Low Computational Power
Feb 07, 2022This paper presents an approach proposed for the Science4cast 2021 competition, organized by the Institute of Advanced Research in Artificial Intelligence, whose main goal was to predict the likelihood of future associations between machine learning concepts in a semantic network. The developed methodology corresponds to a solution for a scenario of availability of low computational power only, exploiting the extraction of low order topological features and its incorporation in an optimized classifier to estimate the degree of future connections between the nodes. The reasons that motivated the developed methodologies will be discussed, as well as some results, limitations and suggestions of improvements.
* Solution awarded a special prize in the Science4cast 2021 competition. Presented and published in the IEEE Big Data 2021 conference. Minor text improvements and typos corrected from the published version
A New Approach for Interpretability and Reliability in Clinical Risk Prediction: Acute Coronary Syndrome Scenario
Oct 15, 2021

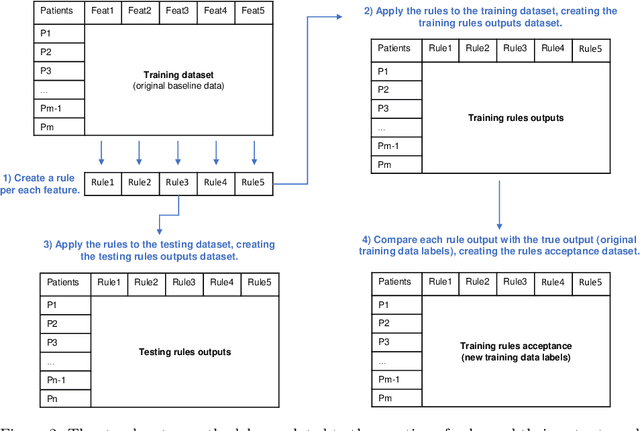
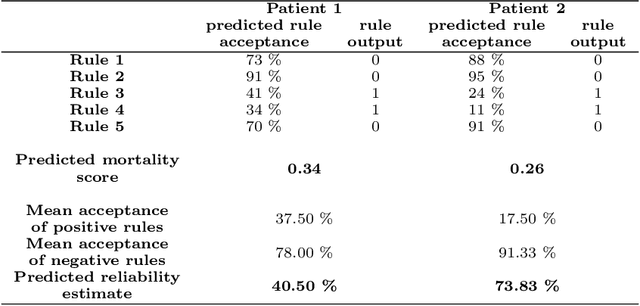
We intend to create a new risk assessment methodology that combines the best characteristics of both risk score and machine learning models. More specifically, we aim to develop a method that, besides having a good performance, offers a personalized model and outcome for each patient, presents high interpretability, and incorporates an estimation of the prediction reliability which is not usually available. By combining these features in the same approach we expect that it can boost the confidence of physicians to use such a tool in their daily activity. In order to achieve the mentioned goals, a three-step methodology was developed: several rules were created by dichotomizing risk factors; such rules were trained with a machine learning classifier to predict the acceptance degree of each rule (the probability that the rule is correct) for each patient; that information was combined and used to compute the risk of mortality and the reliability of such prediction. The methodology was applied to a dataset of patients admitted with any type of acute coronary syndromes (ACS), to assess the 30-days all-cause mortality risk. The performance was compared with state-of-the-art approaches: logistic regression (LR), artificial neural network (ANN), and clinical risk score model (Global Registry of Acute Coronary Events - GRACE). The proposed approach achieved testing results identical to the standard LR, but offers superior interpretability and personalization; it also significantly outperforms the GRACE risk model and the standard ANN model. The calibration curve also suggests a very good generalization ability of the obtained model as it approaches the ideal curve. Finally, the reliability estimation of individual predictions presented a great correlation with the misclassifications rate. Those properties may have a beneficial application in other clinical scenarios as well. [abridged]
* Accepted for publication in the Artificial Intelligence in Medicine journal. Abstract abridged to respect the arXiv's characters limit
Personalized and Reliable Decision Sets: Enhancing Interpretability in Clinical Decision Support Systems
Jul 15, 2021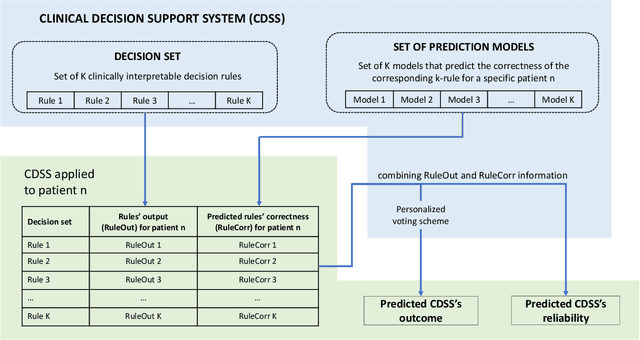

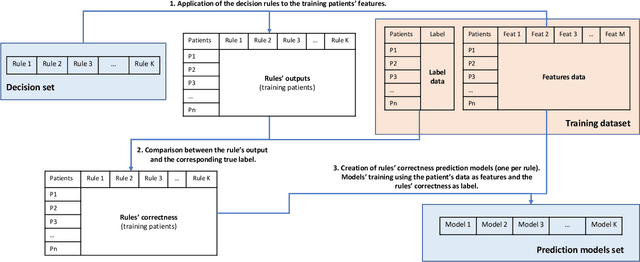
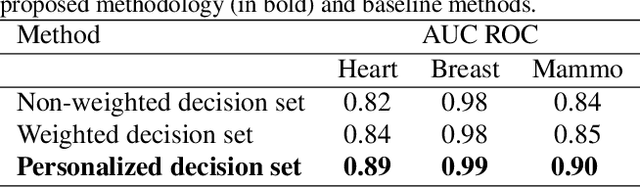
In this study, we present a novel clinical decision support system and discuss its interpretability-related properties. It combines a decision set of rules with a machine learning scheme to offer global and local interpretability. More specifically, machine learning is used to predict the likelihood of each of those rules to be correct for a particular patient, which may also contribute to better predictive performances. Moreover, the reliability analysis of individual predictions is also addressed, contributing to further personalized interpretability. The combination of these several elements may be crucial to obtain the clinical stakeholders' trust, leading to a better assessment of patients' conditions and improvement of the physicians' decision-making.
Improving the compromise between accuracy, interpretability and personalization of rule-based machine learning in medical problems
Jun 15, 2021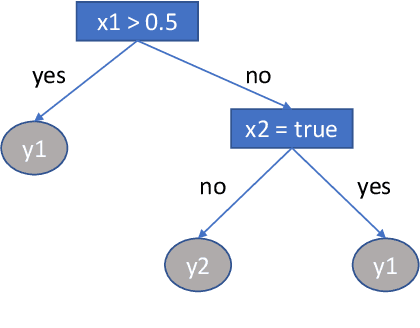
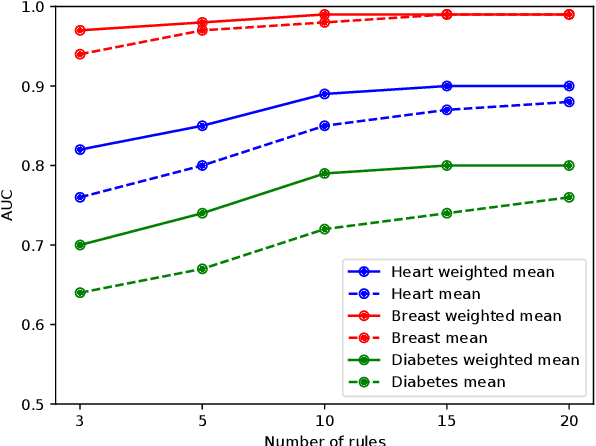
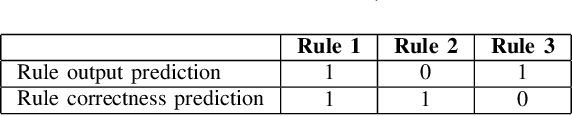
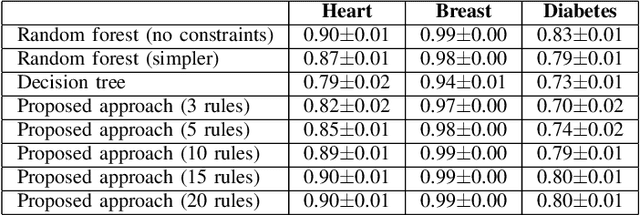
One of the key challenges when developing a predictive model is the capability to describe the domain knowledge and the cause-effect relationships in a simple way. Decision rules are a useful and important methodology in this context, justifying their application in several areas, in particular in clinical practice. Several machine-learning classifiers have exploited the advantageous properties of decision rules to build intelligent prediction models, namely decision trees and ensembles of trees (ETs). However, such methodologies usually suffer from a trade-off between interpretability and predictive performance. Some procedures consider a simplification of ETs, using heuristic approaches to select an optimal reduced set of decision rules. In this paper, we introduce a novel step to those methodologies. We create a new component to predict if a given rule will be correct or not for a particular patient, which introduces personalization into the procedure. Furthermore, the validation results using three public clinical datasets show that it also allows to increase the predictive performance of the selected set of rules, improving the mentioned trade-off.