 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Nomination: Deep Learning for Decentralized CSI Feedback Reduction in MU-MIMO Systems
Apr 23, 2025



This paper introduces a novel deep learning-based user-side feedback reduction framework, termed self-nomination. The goal of self-nomination is to reduce the number of users (UEs) feeding back channel state information (CSI) to the base station (BS), by letting each UE decide whether to feed back based on its estimated likelihood of being scheduled and its potential contribution to precoding in a multiuser MIMO (MU-MIMO) downlink. Unlike SNR- or SINR-based thresholding methods, the proposed approach uses rich spatial channel statistics and learns nontrivial correlation effects that affect eventual MU-MIMO scheduling decisions. To train the self-nomination network under an average feedback constraint, we propose two different strategies: one based on direct optimization with gradient approximations, and another using policy gradient-based optimization with a stochastic Bernoulli policy to handle non-differentiable scheduling. The framework also supports proportional-fair scheduling by incorporating dynamic user weights. Numerical results confirm that the proposed self-nomination method significantly reduces CSI feedback overhead. Compared to baseline feedback methods, self-nomination can reduce feedback by as much as 65%, saving not only bandwidth but also allowing many UEs to avoid feedback altogether (and thus, potentially enter a sleep mode). Self-nomination achieves this significant savings with negligible reduction in sum-rate or fairness.
End-to-End Deep Learning for TDD MIMO Systems in the 6G Upper Midbands
Feb 01, 2024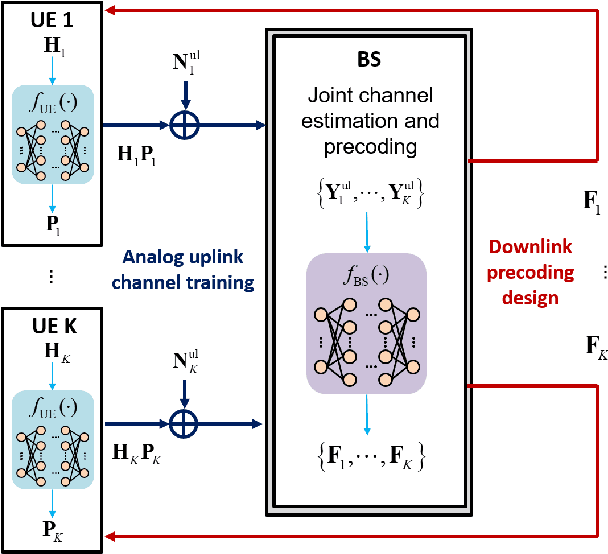
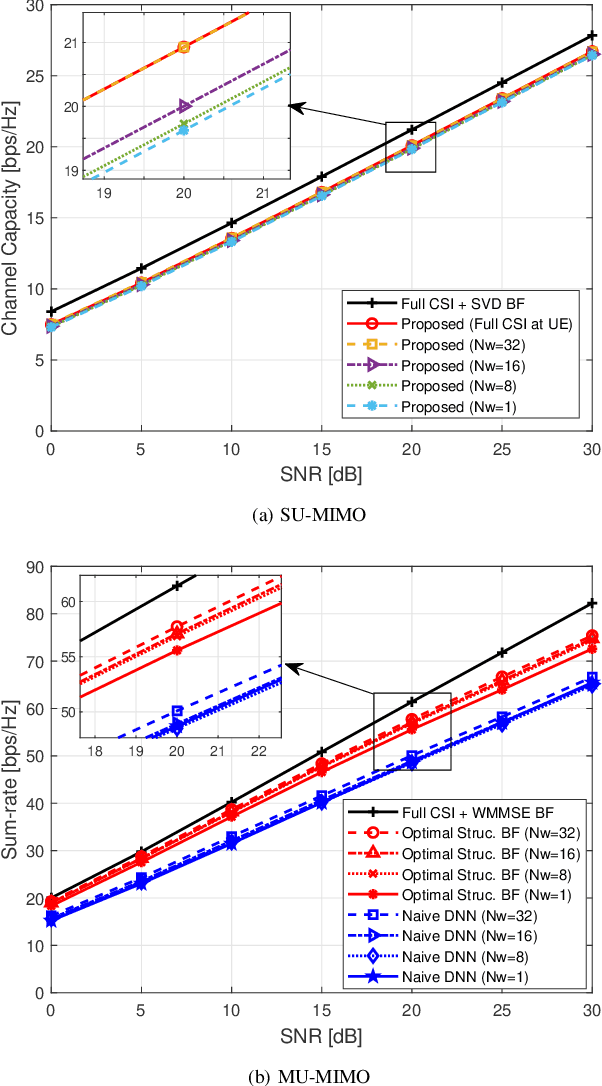
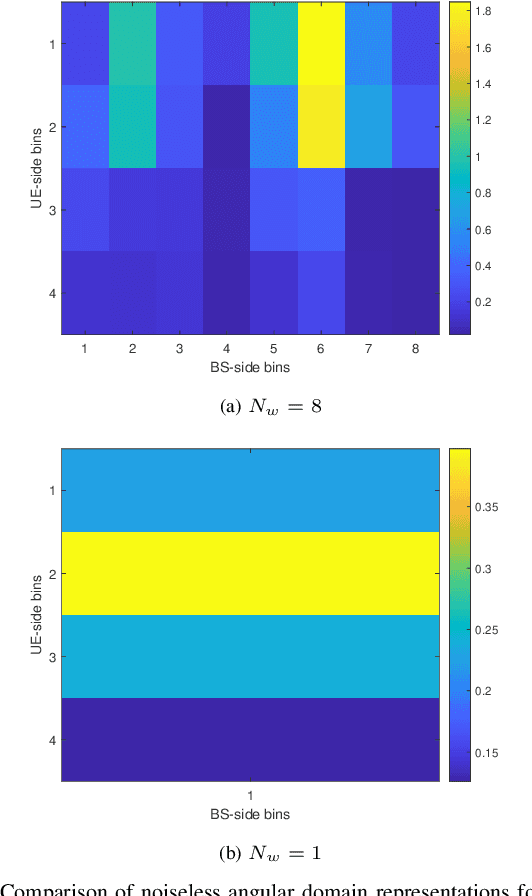
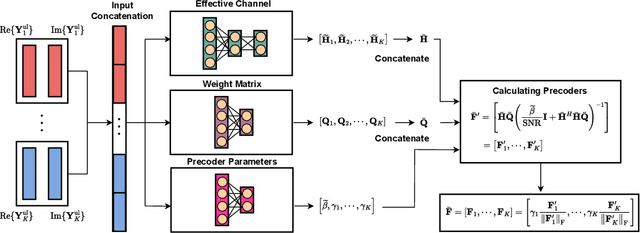
This paper proposes and analyzes novel deep learning methods for downlink (DL) single-user multiple-input multiple-output (SU-MIMO) and multi-user MIMO (MU-MIMO) systems operating in time division duplex (TDD) mode. A motivating application is the 6G upper midbands (7-24 GHz), where the base station (BS) antenna arrays are large, user equipment (UE) array sizes are moderate, and theoretically optimal approaches are practically infeasible for several reasons. To deal with uplink (UL) pilot overhead and low signal power issues, we introduce the channel-adaptive pilot, as part of an analog channel state information feedback mechanism. Deep neural network (DNN)-generated pilots are used to linearly transform the UL channel matrix into lower-dimensional latent vectors. Meanwhile, the BS employs a second DNN that processes the received UL pilots to directly generate near-optimal DL precoders. The training is end-to-end which exploits synergies between the two DNNs. For MU-MIMO precoding, we propose a DNN structure inspired by theoretically optimum linear precoding. The proposed methods are evaluated against genie-aided upper bounds and conventional approaches, using realistic upper midband datasets. Numerical results demonstrate the potential of our approach to achieve significantly increased sum-rate, particularly at moderate to high signal-to-noise ratio (SNR) and when UL pilot overhead is constrained.
Active Sensing for Two-Sided Beam Alignment and Reflection Design Using Ping-Pong Pilots
May 11, 2023Beam alignment is an important task for millimeter-wave (mmWave) communication, because constructing aligned narrow beams both at the transmitter (Tx) and the receiver (Rx) is crucial in terms of compensating the significant path loss in very high-frequency bands. However, beam alignment is also a highly nontrivial task because large antenna arrays typically have a limited number of radio-frequency chains, allowing only low-dimensional measurements of the high-dimensional channel. This paper considers a two-sided beam alignment problem based on an alternating ping-pong pilot scheme between Tx and Rx over multiple rounds without explicit feedback. We propose a deep active sensing framework in which two long short-term memory (LSTM) based neural networks are employed to learn the adaptive sensing strategies (i.e., measurement vectors) and to produce the final aligned beamformers at both sides. In the proposed ping-pong protocol, the Tx and the Rx alternately send pilots so that both sides can leverage local observations to sequentially design their respective sensing and data transmission beamformers. The proposed strategy can be extended to scenarios with a reconfigurable intelligent surface (RIS) for designing, in addition, the reflection coefficients at the RIS for both sensing and communications. Numerical experiments demonstrate significant and interpretable performance improvement. The proposed strategy works well even for the challenging multipath channel environments.
Role of Deep Learning in Wireless Communications
Oct 05, 2022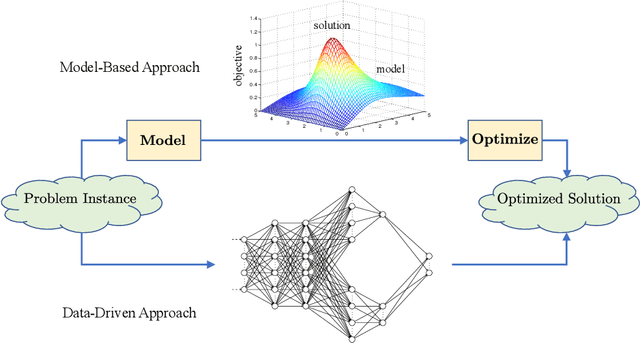
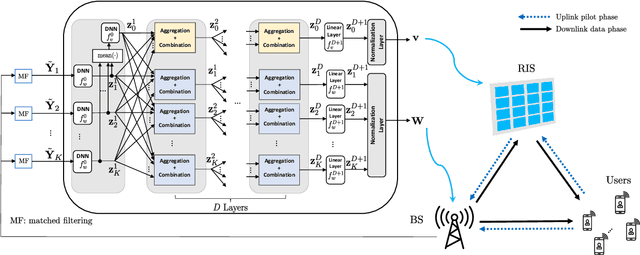
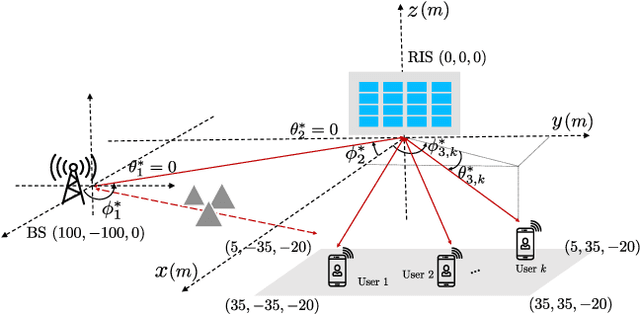
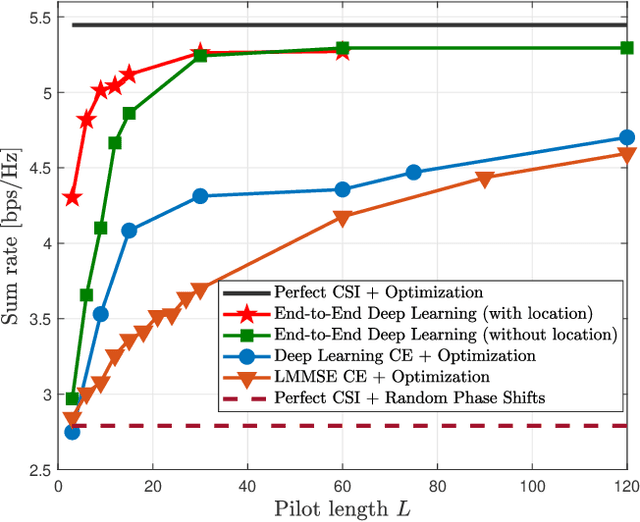
Traditional communication system design has always been based on the paradigm of first establishing a mathematical model of the communication channel, then designing and optimizing the system according to the model. The advent of modern machine learning techniques, specifically deep neural networks, has opened up opportunities for data-driven system design and optimization. This article draws examples from the optimization of reconfigurable intelligent surface, distributed channel estimation and feedback for multiuser beamforming, and active sensing for millimeter wave (mmWave) initial alignment to illustrate that a data-driven design that bypasses explicit channel modelling can often discover excellent solutions to communication system design and optimization problems that are otherwise computationally difficult to solve. We show that by performing an end-to-end training of a deep neural network using a large number of channel samples, a machine learning based approach can potentially provide significant system-level improvements as compared to the traditional model-based approach for solving optimization problems. The key to the successful applications of machine learning techniques is in choosing the appropriate neural network architecture to match the underlying problem structure.
Active Sensing for Communications by Learning
Dec 08, 2021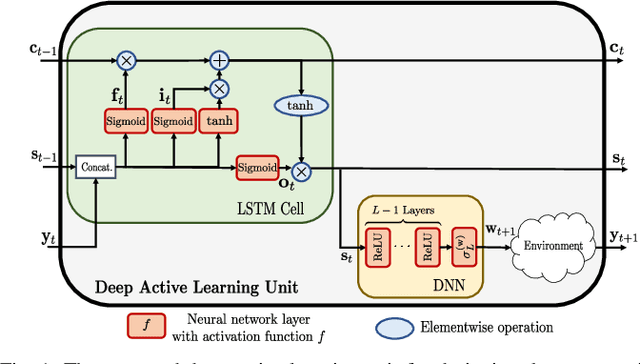
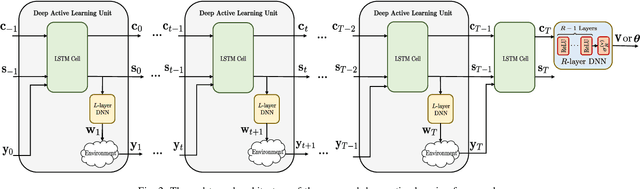
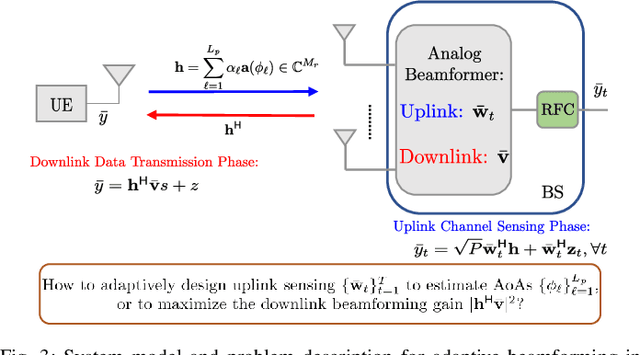
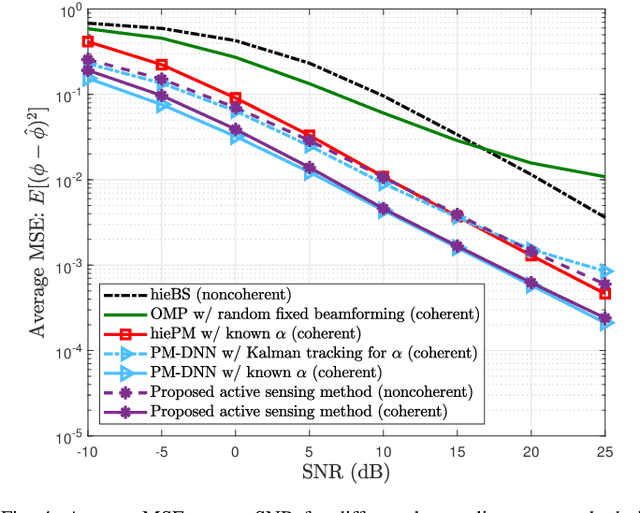
This paper proposes a deep learning approach to a class of active sensing problems in wireless communications in which an agent sequentially interacts with an environment over a predetermined number of time frames to gather information in order to perform a sensing or actuation task for maximizing some utility function. In such an active learning setting, the agent needs to design an adaptive sensing strategy sequentially based on the observations made so far. To tackle such a challenging problem in which the dimension of historical observations increases over time, we propose to use a long short-term memory (LSTM) network to exploit the temporal correlations in the sequence of observations and to map each observation to a fixed-size state information vector. We then use a deep neural network (DNN) to map the LSTM state at each time frame to the design of the next measurement step. Finally, we employ another DNN to map the final LSTM state to the desired solution. We investigate the performance of the proposed framework for adaptive channel sensing problems in wireless communications. In particular, we consider the adaptive beamforming problem for mmWave beam alignment and the adaptive reconfigurable intelligent surface sensing problem for reflection alignment. Numerical results demonstrate that the proposed deep active sensing strategy outperforms the existing adaptive or nonadaptive sensing schemes.
Hybrid Analog and Digital Beamforming Design for Channel Estimation in Correlated Massive MIMO Systems
Jul 15, 2021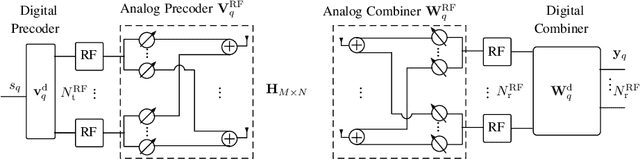
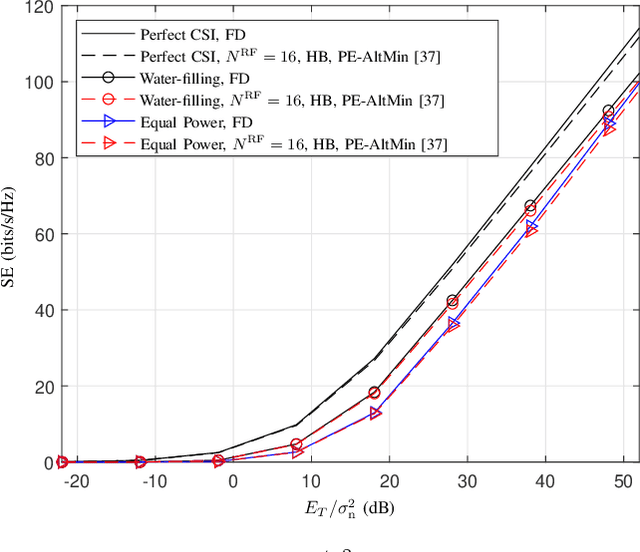
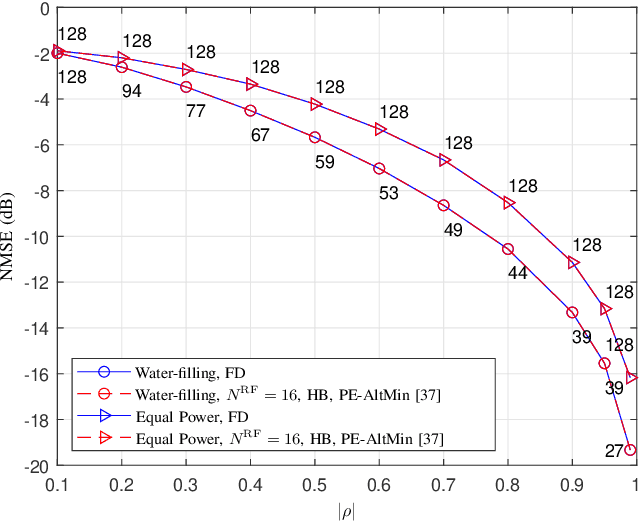
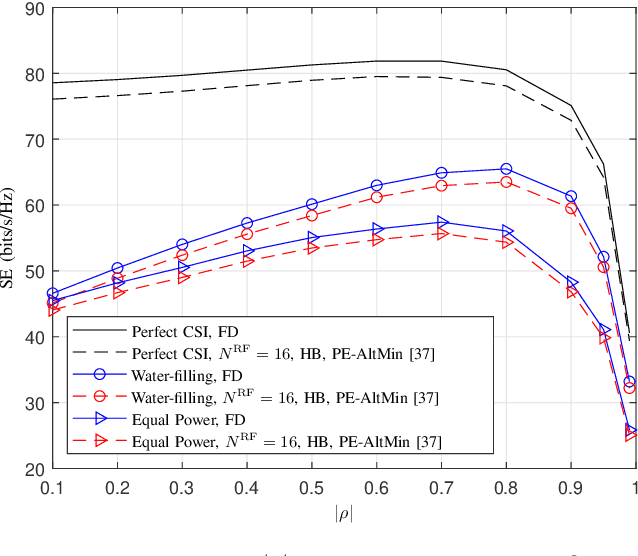
In this paper, we study the channel estimation problem in correlated massive multiple-input-multiple-output (MIMO) systems with a reduced number of radio-frequency (RF) chains. Importantly, other than the knowledge of channel correlation matrices, we make no assumption as to the structure of the channel. To address the limitation in the number of RF chains, we employ hybrid beamforming, comprising a low dimensional digital beamformer followed by an analog beamformer implemented using phase shifters. Since there is no dedicated RF chain per transmitter/receiver antenna, the conventional channel estimation techniques for fully-digital systems are impractical. By exploiting the fact that the channel entries are uncorrelated in its eigen-domain, we seek to estimate the channel entries in this domain. Due to the limited number of RF chains, channel estimation is typically performed in multiple time slots. Under a total energy budget, we aim to design the hybrid transmit beamformer (precoder) and the receive beamformer (combiner) in each training time slot, in order to estimate the channel using the minimum mean squared error criterion. To this end, we choose the precoder and combiner in each time slot such that they are aligned to transmitter and receiver eigen-directions, respectively. Further, we derive a water-filling-type expression for the optimal energy allocation at each time slot. This expression illustrates that, with a low training energy budget, only significant components of the channel need to be estimated. In contrast, with a large training energy budget, the energy is almost equally distributed among all eigen-directions. Simulation results show that the proposed channel estimation scheme can efficiently estimate correlated massive MIMO channels within a few training time slots.
An Efficient Active Set Algorithm for Covariance Based Joint Data and Activity Detection for Massive Random Access with Massive MIMO
Feb 06, 2021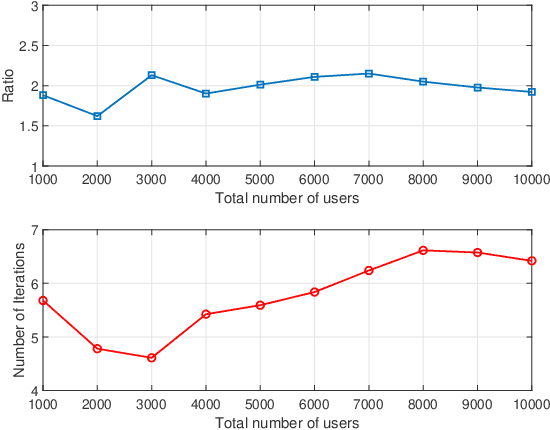
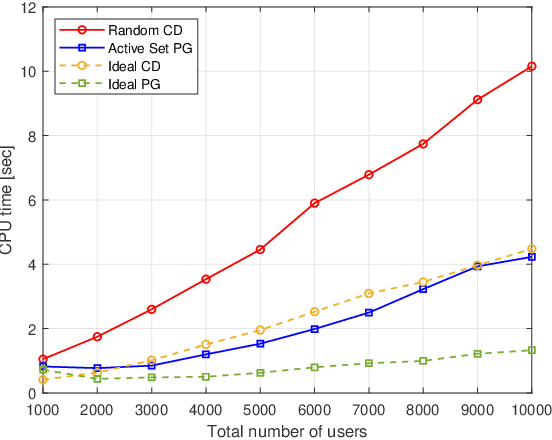
This paper proposes a computationally efficient algorithm to solve the joint data and activity detection problem for massive random access with massive multiple-input multiple-output (MIMO). The BS acquires the active devices and their data by detecting the transmitted preassigned nonorthogonal signature sequences. This paper employs a covariance based approach that formulates the detection problem as a maximum likelihood estimation (MLE) problem. To efficiently solve the problem, this paper designs a novel iterative algorithm with low complexity in the regime where the device activity pattern is sparse $\unicode{x2013}$ a key feature that existing algorithmic designs have not previously exploited for reducing complexity. Specifically, at each iteration, the proposed algorithm focuses on only a small subset of all potential sequences, namely the active set, which contains a few most likely active sequences (i.e., transmitted sequences by all active devices), and performs the detection for the sequences in the active set. The active set is carefully selected at each iteration based on the current detection result and the first-order optimality condition of the MLE problem. Simulation results show that the proposed active set algorithm enjoys significantly better computational efficiency (in terms of the CPU time) than the state-of-the-art algorithms.