 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteady-State Behavior of Constant-Stepsize Stochastic Approximation: Gaussian Approximation and Tail Bounds
Feb 15, 2026Constant-stepsize stochastic approximation (SA) is widely used in learning for computational efficiency. For a fixed stepsize, the iterates typically admit a stationary distribution that is rarely tractable. Prior work shows that as the stepsize $α\downarrow 0$, the centered-and-scaled steady state converges weakly to a Gaussian random vector. However, for fixed $α$, this weak convergence offers no usable error bound for approximating the steady-state by its Gaussian limit. This paper provides explicit, non-asymptotic error bounds for fixed $α$. We first prove general-purpose theorems that bound the Wasserstein distance between the centered-scaled steady state and an appropriate Gaussian distribution, under regularity conditions for drift and moment conditions for noise. To ensure broad applicability, we cover both i.i.d. and Markovian noise models. We then instantiate these theorems for three representative SA settings: (1) stochastic gradient descent (SGD) for smooth strongly convex objectives, (2) linear SA, and (3) contractive nonlinear SA. We obtain dimension- and stepsize-dependent, explicit bounds in Wasserstein distance of order $α^{1/2}\log(1/α)$ for small $α$. Building on the Wasserstein approximation error, we further derive non-uniform Berry--Esseen-type tail bounds that compare the steady-state tail probability to Gaussian tails. We achieve an explicit error term that decays in both the deviation level and stepsize $α$. We adapt the same analysis for SGD beyond strongly convexity and study general convex objectives. We identify a non-Gaussian (Gibbs) limiting law under the correct scaling, which is validated numerically, and provide a corresponding pre-limit Wasserstein error bound.
AnoVox: A Benchmark for Multimodal Anomaly Detection in Autonomous Driving
May 13, 2024
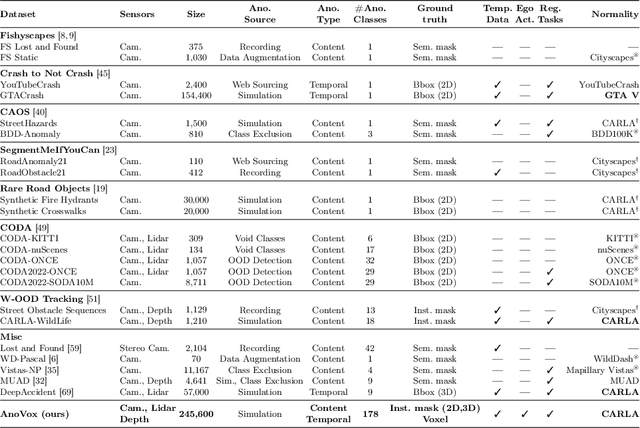
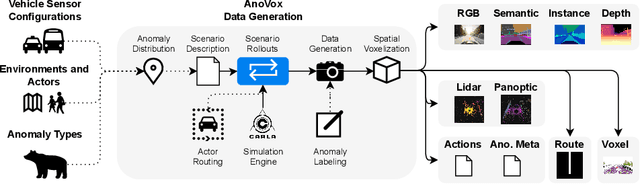
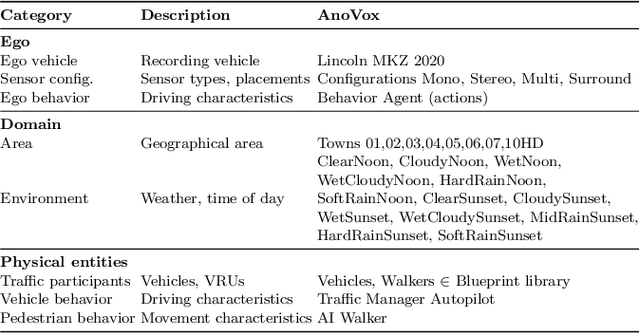
The scale-up of autonomous vehicles depends heavily on their ability to deal with anomalies, such as rare objects on the road. In order to handle such situations, it is necessary to detect anomalies in the first place. Anomaly detection for autonomous driving has made great progress in the past years but suffers from poorly designed benchmarks with a strong focus on camera data. In this work, we propose AnoVox, the largest benchmark for ANOmaly detection in autonomous driving to date. AnoVox incorporates large-scale multimodal sensor data and spatial VOXel ground truth, allowing for the comparison of methods independent of their used sensor. We propose a formal definition of normality and provide a compliant training dataset. AnoVox is the first benchmark to contain both content and temporal anomalies.
Decomposing spiking neural networks with Graphical Neural Activity Threads
Jun 29, 2023A satisfactory understanding of information processing in spiking neural networks requires appropriate computational abstractions of neural activity. Traditionally, the neural population state vector has been the most common abstraction applied to spiking neural networks, but this requires artificially partitioning time into bins that are not obviously relevant to the network itself. We introduce a distinct set of techniques for analyzing spiking neural networks that decomposes neural activity into multiple, disjoint, parallel threads of activity. We construct these threads by estimating the degree of causal relatedness between pairs of spikes, then use these estimates to construct a directed acyclic graph that traces how the network activity evolves through individual spikes. We find that this graph of spiking activity naturally decomposes into disjoint connected components that overlap in space and time, which we call Graphical Neural Activity Threads (GNATs). We provide an efficient algorithm for finding analogous threads that reoccur in large spiking datasets, revealing that seemingly distinct spike trains are composed of similar underlying threads of activity, a hallmark of compositionality. The picture of spiking neural networks provided by our GNAT analysis points to new abstractions for spiking neural computation that are naturally adapted to the spatiotemporally distributed dynamics of spiking neural networks.
Distributed Compressed Sparse Row Format for Spiking Neural Network Simulation, Serialization, and Interoperability
Apr 12, 2023With the increasing development of neuromorphic platforms and their related software tools as well as the increasing scale of spiking neural network (SNN) models, there is a pressure for interoperable and scalable representations of network state. In response to this, we discuss a parallel extension of a widely used format for efficiently representing sparse matrices, the compressed sparse row (CSR), in the context of supporting the simulation and serialization of large-scale SNNs. Sparse matrices for graph adjacency structure provide a natural fit for describing the connectivity of an SNN, and prior work in the area of parallel graph partitioning has developed the distributed CSR (dCSR) format for storing and ingesting large graphs. We contend that organizing additional network information, such as neuron and synapse state, in alignment with its adjacency as dCSR provides a straightforward partition-based distribution of network state. For large-scale simulations, this means each parallel process is only responsible for its own partition of state, which becomes especially useful when the size of an SNN exceeds the memory resources of a single compute node. For potentially long-running simulations, this also enables network serialization to and from disk (e.g. for checkpoint/restart fault-tolerant computing) to be performed largely independently between parallel processes. We also provide a potential implementation, and put it forward for adoption within the neural computing community.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023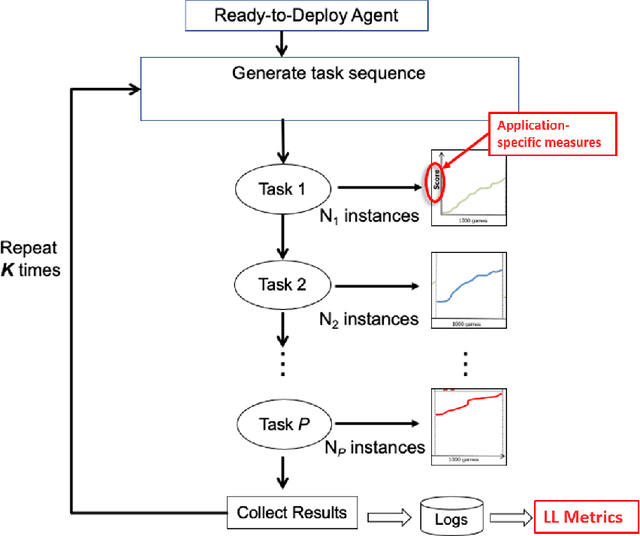
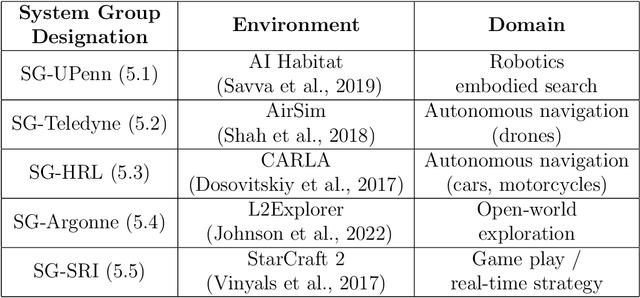


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.