 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-exhibited Personality Traits Can Shape Human Self-concept through Conversations
Jan 19, 2026Recent Large Language Model (LLM) based AI can exhibit recognizable and measurable personality traits during conversations to improve user experience. However, as human understandings of their personality traits can be affected by their interaction partners' traits, a potential risk is that AI traits may shape and bias users' self-concept of their own traits. To explore the possibility, we conducted a randomized behavioral experiment. Our results indicate that after conversations about personal topics with an LLM-based AI chatbot using GPT-4o default personality traits, users' self-concepts aligned with the AI's measured personality traits. The longer the conversation, the greater the alignment. This alignment led to increased homogeneity in self-concepts among users. We also observed that the degree of self-concept alignment was positively associated with users' conversation enjoyment. Our findings uncover how AI personality traits can shape users' self-concepts through human-AI conversation, highlighting both risks and opportunities. We provide important design implications for developing more responsible and ethical AI systems.
What is Stigma Attributed to? A Theory-Grounded, Expert-Annotated Interview Corpus for Demystifying Mental-Health Stigma
May 19, 2025Mental-health stigma remains a pervasive social problem that hampers treatment-seeking and recovery. Existing resources for training neural models to finely classify such stigma are limited, relying primarily on social-media or synthetic data without theoretical underpinnings. To remedy this gap, we present an expert-annotated, theory-informed corpus of human-chatbot interviews, comprising 4,141 snippets from 684 participants with documented socio-cultural backgrounds. Our experiments benchmark state-of-the-art neural models and empirically unpack the challenges of stigma detection. This dataset can facilitate research on computationally detecting, neutralizing, and counteracting mental-health stigma.
Deconstructing Depression Stigma: Integrating AI-driven Data Collection and Analysis with Causal Knowledge Graphs
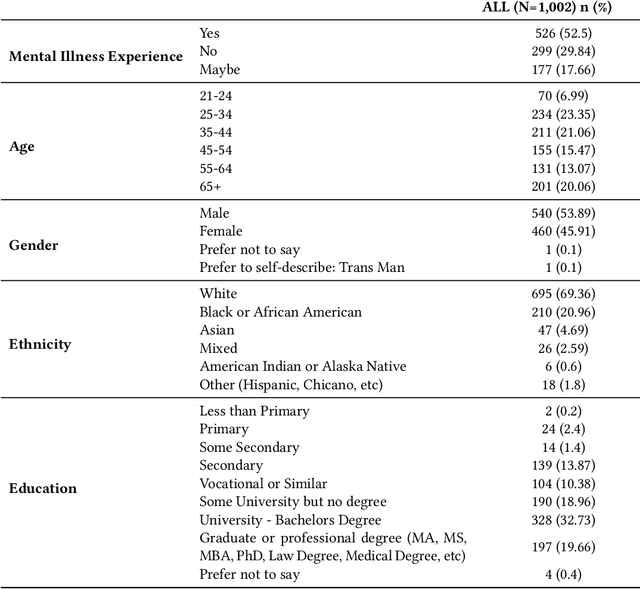
Feb 09, 2025Mental-illness stigma is a persistent social problem, hampering both treatment-seeking and recovery. Accordingly, there is a pressing need to understand it more clearly, but analyzing the relevant data is highly labor-intensive. Therefore, we designed a chatbot to engage participants in conversations; coded those conversations qualitatively with AI assistance; and, based on those coding results, built causal knowledge graphs to decode stigma. The results we obtained from 1,002 participants demonstrate that conversation with our chatbot can elicit rich information about people's attitudes toward depression, while our AI-assisted coding was strongly consistent with human-expert coding. Our novel approach combining large language models (LLMs) and causal knowledge graphs uncovered patterns in individual responses and illustrated the interrelationships of psychological constructs in the dataset as a whole. The paper also discusses these findings' implications for HCI researchers in developing digital interventions, decomposing human psychological constructs, and fostering inclusive attitudes.
AnoVox: A Benchmark for Multimodal Anomaly Detection in Autonomous Driving
May 13, 2024
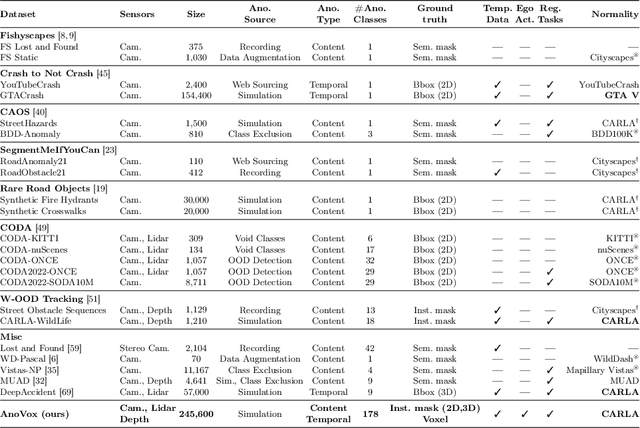
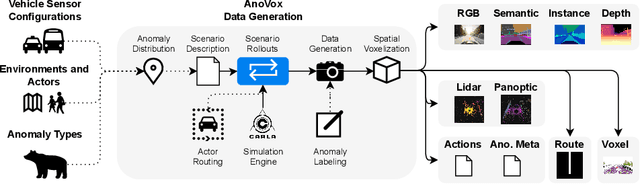
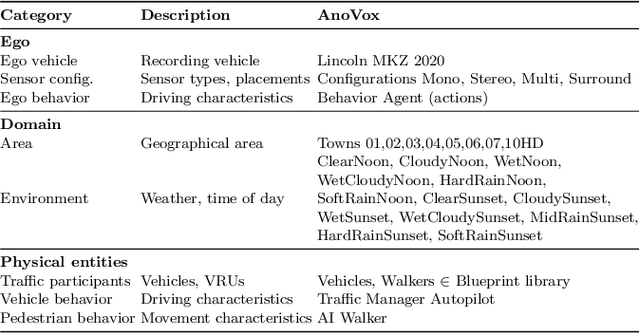
The scale-up of autonomous vehicles depends heavily on their ability to deal with anomalies, such as rare objects on the road. In order to handle such situations, it is necessary to detect anomalies in the first place. Anomaly detection for autonomous driving has made great progress in the past years but suffers from poorly designed benchmarks with a strong focus on camera data. In this work, we propose AnoVox, the largest benchmark for ANOmaly detection in autonomous driving to date. AnoVox incorporates large-scale multimodal sensor data and spatial VOXel ground truth, allowing for the comparison of methods independent of their used sensor. We propose a formal definition of normality and provide a compliant training dataset. AnoVox is the first benchmark to contain both content and temporal anomalies.
Exploring the Potential of Human-LLM Synergy in Advancing Qualitative Analysis: A Case Study on Mental-Illness Stigma
May 09, 2024
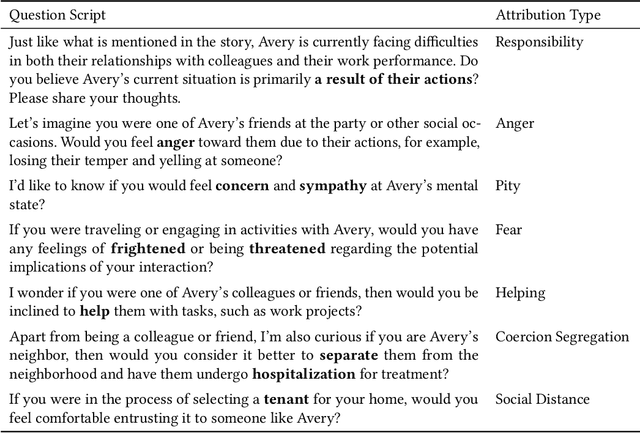
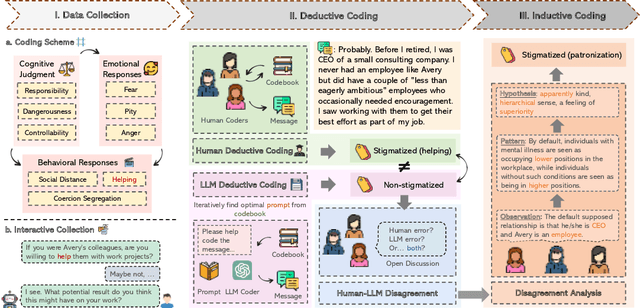
Qualitative analysis is a challenging, yet crucial aspect of advancing research in the field of Human-Computer Interaction (HCI). Recent studies show that large language models (LLMs) can perform qualitative coding within existing schemes, but their potential for collaborative human-LLM discovery and new insight generation in qualitative analysis is still underexplored. To bridge this gap and advance qualitative analysis by harnessing the power of LLMs, we propose CHALET, a novel methodology that leverages the human-LLM collaboration paradigm to facilitate conceptualization and empower qualitative research. The CHALET approach involves LLM-supported data collection, performing both human and LLM deductive coding to identify disagreements, and performing collaborative inductive coding on these disagreement cases to derive new conceptual insights. We validated the effectiveness of CHALET through its application to the attribution model of mental-illness stigma, uncovering implicit stigmatization themes on cognitive, emotional and behavioral dimensions. We discuss the implications for future research, methodology, and the transdisciplinary opportunities CHALET presents for the HCI community and beyond.
Overconfident and Unconfident AI Hinder Human-AI Collaboration
Feb 12, 2024As artificial intelligence (AI) advances, human-AI collaboration has become increasingly prevalent across both professional and everyday settings. In such collaboration, AI can express its confidence level about its performance, serving as a crucial indicator for humans to evaluate AI's suggestions. However, AI may exhibit overconfidence or underconfidence--its expressed confidence is higher or lower than its actual performance--which may lead humans to mistakenly evaluate AI advice. Our study investigates the influences of AI's overconfidence and underconfidence on human trust, their acceptance of AI suggestions, and collaboration outcomes. Our study reveal that disclosing AI confidence levels and performance feedback facilitates better recognition of AI confidence misalignments. However, participants tend to withhold their trust as perceiving such misalignments, leading to a rejection of AI suggestions and subsequently poorer performance in collaborative tasks. Conversely, without such information, participants struggle to identify misalignments, resulting in either the neglect of correct AI advice or the following of incorrect AI suggestions, adversely affecting collaboration. This study offers valuable insights for enhancing human-AI collaboration by underscoring the importance of aligning AI's expressed confidence with its actual performance and the necessity of calibrating human trust towards AI confidence.
MUVO: A Multimodal Generative World Model for Autonomous Driving with Geometric Representations
Nov 23, 2023



Learning unsupervised world models for autonomous driving has the potential to improve the reasoning capabilities of today's systems dramatically. However, most work neglects the physical attributes of the world and focuses on sensor data alone. We propose MUVO, a MUltimodal World Model with Geometric VOxel Representations to address this challenge. We utilize raw camera and lidar data to learn a sensor-agnostic geometric representation of the world, which can directly be used by downstream tasks, such as planning. We demonstrate multimodal future predictions and show that our geometric representation improves the prediction quality of both camera images and lidar point clouds.
Exploring the Potential of World Models for Anomaly Detection in Autonomous Driving
Aug 10, 2023
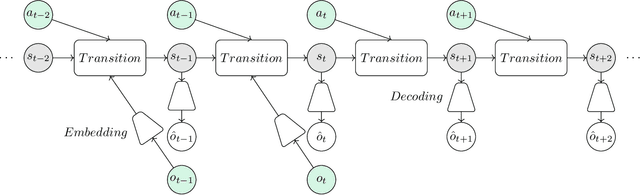


In recent years there have been remarkable advancements in autonomous driving. While autonomous vehicles demonstrate high performance in closed-set conditions, they encounter difficulties when confronted with unexpected situations. At the same time, world models emerged in the field of model-based reinforcement learning as a way to enable agents to predict the future depending on potential actions. This led to outstanding results in sparse reward and complex control tasks. This work provides an overview of how world models can be leveraged to perform anomaly detection in the domain of autonomous driving. We provide a characterization of world models and relate individual components to previous works in anomaly detection to facilitate further research in the field.