 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring multimodal implicit behavior learning for vehicle navigation in simulated cities
Sep 18, 2025Standard Behavior Cloning (BC) fails to learn multimodal driving decisions, where multiple valid actions exist for the same scenario. We explore Implicit Behavioral Cloning (IBC) with Energy-Based Models (EBMs) to better capture this multimodality. We propose Data-Augmented IBC (DA-IBC), which improves learning by perturbing expert actions to form the counterexamples of IBC training and using better initialization for derivative-free inference. Experiments in the CARLA simulator with Bird's-Eye View inputs demonstrate that DA-IBC outperforms standard IBC in urban driving tasks designed to evaluate multimodal behavior learning in a test environment. The learned energy landscapes are able to represent multimodal action distributions, which BC fails to achieve.
An Initial Study of Bird's-Eye View Generation for Autonomous Vehicles using Cross-View Transformers
Aug 17, 2025Bird's-Eye View (BEV) maps provide a structured, top-down abstraction that is crucial for autonomous-driving perception. In this work, we employ Cross-View Transformers (CVT) for learning to map camera images to three BEV's channels - road, lane markings, and planned trajectory - using a realistic simulator for urban driving. Our study examines generalization to unseen towns, the effect of different camera layouts, and two loss formulations (focal and L1). Using training data from only a town, a four-camera CVT trained with the L1 loss delivers the most robust test performance, evaluated in a new town. Overall, our results underscore CVT's promise for mapping camera inputs to reasonably accurate BEV maps.
Physics-Informed Neural Networks with Skip Connections for Modeling and Control of Gas-Lifted Oil Wells
Mar 04, 2024Neural networks, while powerful, often lack interpretability. Physics-Informed Neural Networks (PINNs) address this limitation by incorporating physics laws into the loss function, making them applicable to solving Ordinary Differential Equations (ODEs) and Partial Differential Equations (PDEs). The recently introduced PINC framework extends PINNs to control applications, allowing for open-ended long-range prediction and control of dynamic systems. In this work, we enhance PINC for modeling highly nonlinear systems such as gas-lifted oil wells. By introducing skip connections in the PINC network and refining certain terms in the ODE, we achieve more accurate gradients during training, resulting in an effective modeling process for the oil well system. Our proposed improved PINC demonstrates superior performance, reducing the validation prediction error by an average of 67% in the oil well application and significantly enhancing gradient flow through the network layers, increasing its magnitude by four orders of magnitude compared to the original PINC. Furthermore, experiments showcase the efficacy of Model Predictive Control (MPC) in regulating the bottom-hole pressure of the oil well using the improved PINC model, even in the presence of noisy measurements.
Hierarchical Generative Adversarial Imitation Learning with Mid-level Input Generation for Autonomous Driving on Urban Environments
Feb 09, 2023



Deriving robust control policies for realistic urban navigation scenarios is not a trivial task. In an end-to-end approach, these policies must map high-dimensional images from the vehicle's cameras to low-level actions such as steering and throttle. While pure Reinforcement Learning (RL) approaches are based exclusively on rewards,Generative Adversarial Imitation Learning (GAIL) agents learn from expert demonstrations while interacting with the environment, which favors GAIL on tasks for which a reward signal is difficult to derive. In this work, the hGAIL architecture was proposed to solve the autonomous navigation of a vehicle in an end-to-end approach, mapping sensory perceptions directly to low-level actions, while simultaneously learning mid-level input representations of the agent's environment. The proposed hGAIL consists of an hierarchical Adversarial Imitation Learning architecture composed of two main modules: the GAN (Generative Adversarial Nets) which generates the Bird's-Eye View (BEV) representation mainly from the images of three frontal cameras of the vehicle, and the GAIL which learns to control the vehicle based mainly on the BEV predictions from the GAN as input.Our experiments have shown that GAIL exclusively from cameras (without BEV) fails to even learn the task, while hGAIL, after training, was able to autonomously navigate successfully in all intersections of the city.
Investigation of Proper Orthogonal Decomposition for Echo State Networks
Dec 02, 2022Echo State Networks (ESN) are a type of Recurrent Neural Networks that yields promising results in representing time series and nonlinear dynamic systems. Although they are equipped with a very efficient training procedure, Reservoir Computing strategies, such as the ESN, require the use of high order networks, i.e. large number of layers, resulting in number of states that is magnitudes higher than the number of model inputs and outputs. This not only makes the computation of a time step more costly, but also may pose robustness issues when applying ESNs to problems such as Model Predictive Control (MPC) and other optimal control problems. One such way to circumvent this is through Model Order Reduction strategies such as the Proper Orthogonal Decomposition (POD) and its variants (POD-DEIM), whereby we find an equivalent lower order representation to an already trained high dimension ESN. The objective of this work is to investigate and analyze the performance of POD methods in Echo State Networks, evaluating their effectiveness. To this end, we evaluate the Memory Capacity (MC) of the POD-reduced network in comparison to the original (full order) ENS. We also perform experiments on two different numerical case studies: a NARMA10 difference equation and an oil platform containing two wells and one riser. The results show that there is little loss of performance comparing the original ESN to a POD-reduced counterpart, and also that the performance of a POD-reduced ESN tend to be superior to a normal ESN of the same size. Also we attain speedups of around $80\%$ in comparison to the original ESN.
Generative Adversarial Imitation Learning for End-to-End Autonomous Driving on Urban Environments
Oct 16, 2021
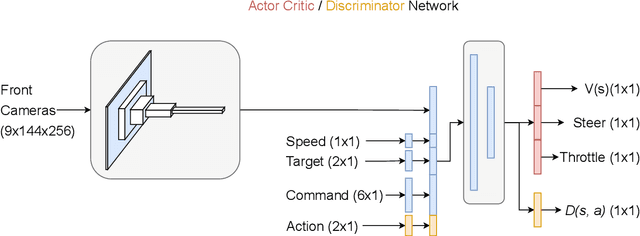

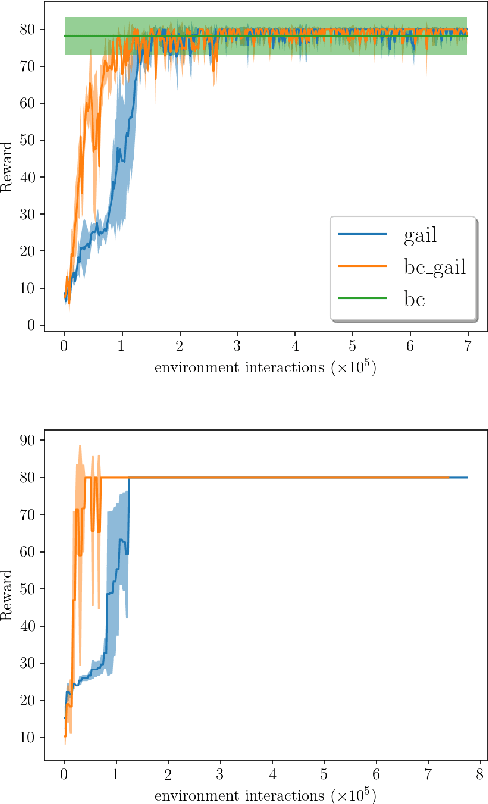
Autonomous driving is a complex task, which has been tackled since the first self-driving car ALVINN in 1989, with a supervised learning approach, or behavioral cloning (BC). In BC, a neural network is trained with state-action pairs that constitute the training set made by an expert, i.e., a human driver. However, this type of imitation learning does not take into account the temporal dependencies that might exist between actions taken in different moments of a navigation trajectory. These type of tasks are better handled by reinforcement learning (RL) algorithms, which need to define a reward function. On the other hand, more recent approaches to imitation learning, such as Generative Adversarial Imitation Learning (GAIL), can train policies without explicitly requiring to define a reward function, allowing an agent to learn by trial and error directly on a training set of expert trajectories. In this work, we propose two variations of GAIL for autonomous navigation of a vehicle in the realistic CARLA simulation environment for urban scenarios. Both of them use the same network architecture, which process high dimensional image input from three frontal cameras, and other nine continuous inputs representing the velocity, the next point from the sparse trajectory and a high-level driving command. We show that both of them are capable of imitating the expert trajectory from start to end after training ends, but the GAIL loss function that is augmented with BC outperforms the former in terms of convergence time and training stability.
Physics-Informed Neural Nets-based Control
Apr 06, 2021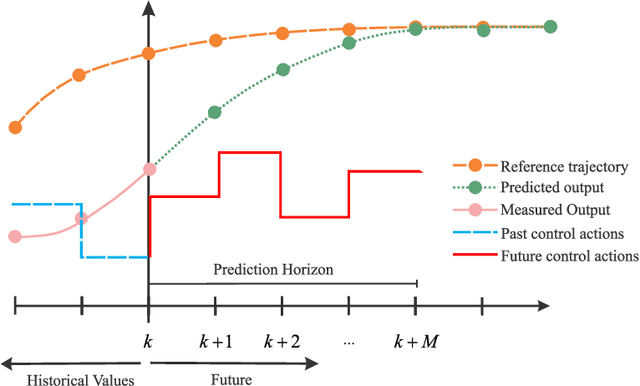
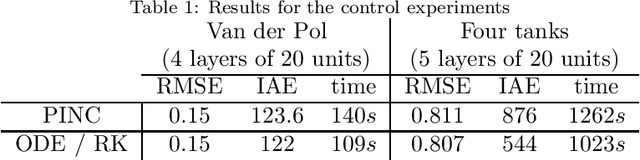
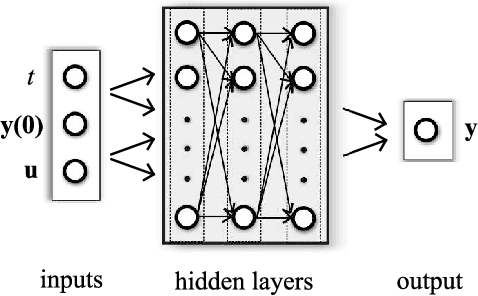
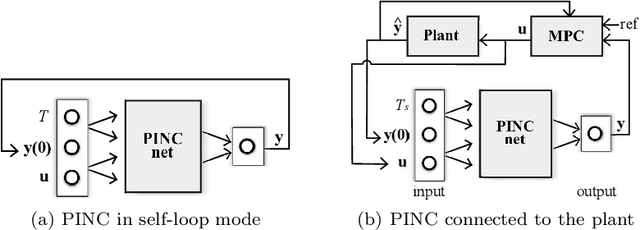
Physics-informed neural networks (PINNs) impose known physical laws into the learning of deep neural networks, making sure they respect the physics of the process while decreasing the demand of labeled data. For systems represented by Ordinary Differential Equations (ODEs), the conventional PINN has a continuous time input variable and outputs the solution of the corresponding ODE. In their original form, PINNs do not allow control inputs neither can they simulate for long-range intervals without serious degradation in their predictions. In this context, this work presents a new framework called Physics-Informed Neural Nets-based Control (PINC), which proposes a novel PINN-based architecture that is amenable to control problems and able to simulate for longer-range time horizons that are not fixed beforehand. First, the network is augmented with new inputs to account for the initial state of the system and the control action. Then, the response over the complete time horizon is split such that each smaller interval constitutes a solution of the ODE conditioned on the fixed values of initial state and control action. The complete response is formed by setting the initial state of the next interval to the terminal state of the previous one. The new methodology enables the optimal control of dynamic systems, making feasible to integrate a priori knowledge from experts and data collected from plants in control applications. We showcase our method in the control of two nonlinear dynamic systems: the Van der Pol oscillator and the four-tank system.