 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring multimodal implicit behavior learning for vehicle navigation in simulated cities
Sep 18, 2025Standard Behavior Cloning (BC) fails to learn multimodal driving decisions, where multiple valid actions exist for the same scenario. We explore Implicit Behavioral Cloning (IBC) with Energy-Based Models (EBMs) to better capture this multimodality. We propose Data-Augmented IBC (DA-IBC), which improves learning by perturbing expert actions to form the counterexamples of IBC training and using better initialization for derivative-free inference. Experiments in the CARLA simulator with Bird's-Eye View inputs demonstrate that DA-IBC outperforms standard IBC in urban driving tasks designed to evaluate multimodal behavior learning in a test environment. The learned energy landscapes are able to represent multimodal action distributions, which BC fails to achieve.
An Initial Study of Bird's-Eye View Generation for Autonomous Vehicles using Cross-View Transformers
Aug 17, 2025Bird's-Eye View (BEV) maps provide a structured, top-down abstraction that is crucial for autonomous-driving perception. In this work, we employ Cross-View Transformers (CVT) for learning to map camera images to three BEV's channels - road, lane markings, and planned trajectory - using a realistic simulator for urban driving. Our study examines generalization to unseen towns, the effect of different camera layouts, and two loss formulations (focal and L1). Using training data from only a town, a four-camera CVT trained with the L1 loss delivers the most robust test performance, evaluated in a new town. Overall, our results underscore CVT's promise for mapping camera inputs to reasonably accurate BEV maps.
Hierarchical Generative Adversarial Imitation Learning with Mid-level Input Generation for Autonomous Driving on Urban Environments
Feb 09, 2023



Deriving robust control policies for realistic urban navigation scenarios is not a trivial task. In an end-to-end approach, these policies must map high-dimensional images from the vehicle's cameras to low-level actions such as steering and throttle. While pure Reinforcement Learning (RL) approaches are based exclusively on rewards,Generative Adversarial Imitation Learning (GAIL) agents learn from expert demonstrations while interacting with the environment, which favors GAIL on tasks for which a reward signal is difficult to derive. In this work, the hGAIL architecture was proposed to solve the autonomous navigation of a vehicle in an end-to-end approach, mapping sensory perceptions directly to low-level actions, while simultaneously learning mid-level input representations of the agent's environment. The proposed hGAIL consists of an hierarchical Adversarial Imitation Learning architecture composed of two main modules: the GAN (Generative Adversarial Nets) which generates the Bird's-Eye View (BEV) representation mainly from the images of three frontal cameras of the vehicle, and the GAIL which learns to control the vehicle based mainly on the BEV predictions from the GAN as input.Our experiments have shown that GAIL exclusively from cameras (without BEV) fails to even learn the task, while hGAIL, after training, was able to autonomously navigate successfully in all intersections of the city.
Generative Adversarial Imitation Learning for End-to-End Autonomous Driving on Urban Environments
Oct 16, 2021
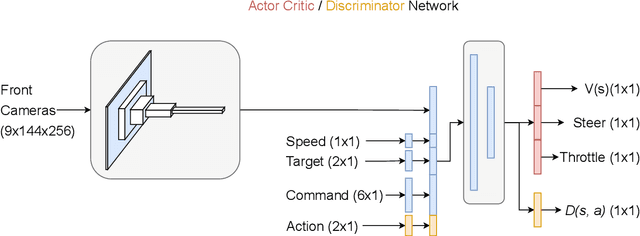

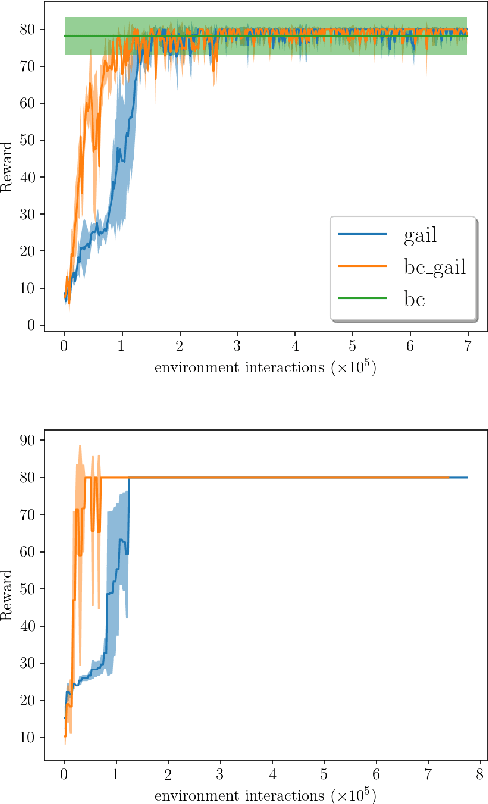
Autonomous driving is a complex task, which has been tackled since the first self-driving car ALVINN in 1989, with a supervised learning approach, or behavioral cloning (BC). In BC, a neural network is trained with state-action pairs that constitute the training set made by an expert, i.e., a human driver. However, this type of imitation learning does not take into account the temporal dependencies that might exist between actions taken in different moments of a navigation trajectory. These type of tasks are better handled by reinforcement learning (RL) algorithms, which need to define a reward function. On the other hand, more recent approaches to imitation learning, such as Generative Adversarial Imitation Learning (GAIL), can train policies without explicitly requiring to define a reward function, allowing an agent to learn by trial and error directly on a training set of expert trajectories. In this work, we propose two variations of GAIL for autonomous navigation of a vehicle in the realistic CARLA simulation environment for urban scenarios. Both of them use the same network architecture, which process high dimensional image input from three frontal cameras, and other nine continuous inputs representing the velocity, the next point from the sparse trajectory and a high-level driving command. We show that both of them are capable of imitating the expert trajectory from start to end after training ends, but the GAIL loss function that is augmented with BC outperforms the former in terms of convergence time and training stability.