 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks Do Work with Pre-Defined Filters
Nov 27, 2024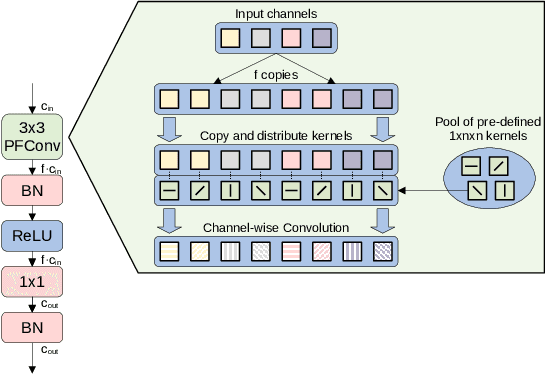
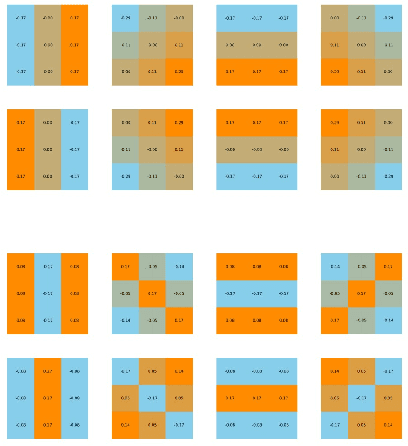
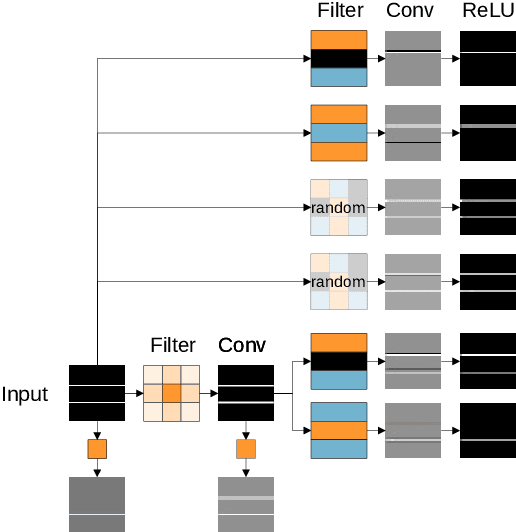
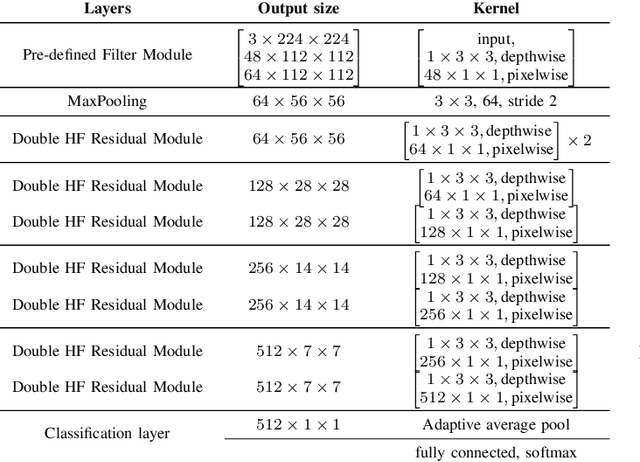
We present a novel class of Convolutional Neural Networks called Pre-defined Filter Convolutional Neural Networks (PFCNNs), where all nxn convolution kernels with n>1 are pre-defined and constant during training. It involves a special form of depthwise convolution operation called a Pre-defined Filter Module (PFM). In the channel-wise convolution part, the 1xnxn kernels are drawn from a fixed pool of only a few (16) different pre-defined kernels. In the 1x1 convolution part linear combinations of the pre-defined filter outputs are learned. Despite this harsh restriction, complex and discriminative features are learned. These findings provide a novel perspective on the way how information is processed within deep CNNs. We discuss various properties of PFCNNs and prove their effectiveness using the popular datasets Caltech101, CIFAR10, CUB-200-2011, FGVC-Aircraft, Flowers102, and Stanford Cars. Our implementation of PFCNNs is provided on Github https://github.com/Criscraft/PredefinedFilterNetworks
Leaky ReLUs That Differ in Forward and Backward Pass Facilitate Activation Maximization in Deep Neural Networks
Oct 22, 2024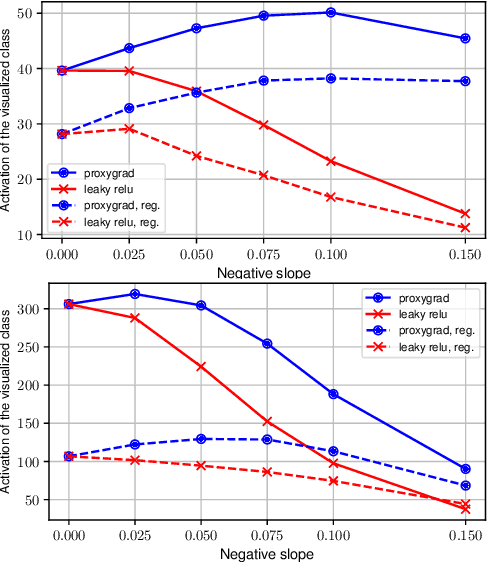

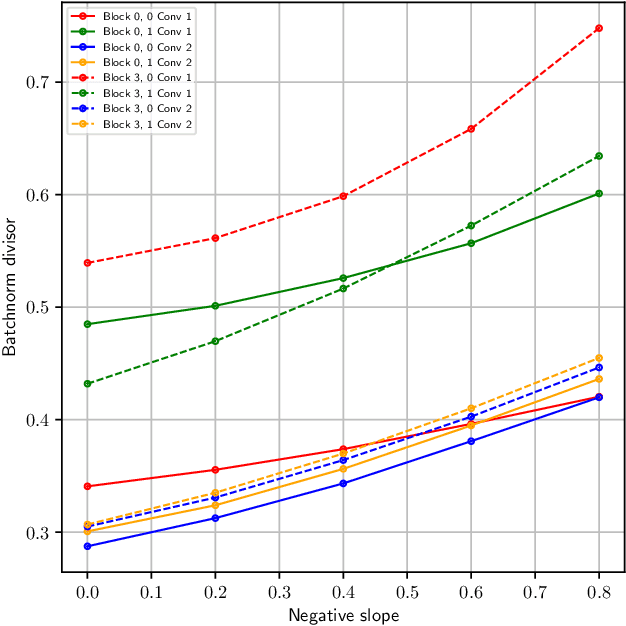
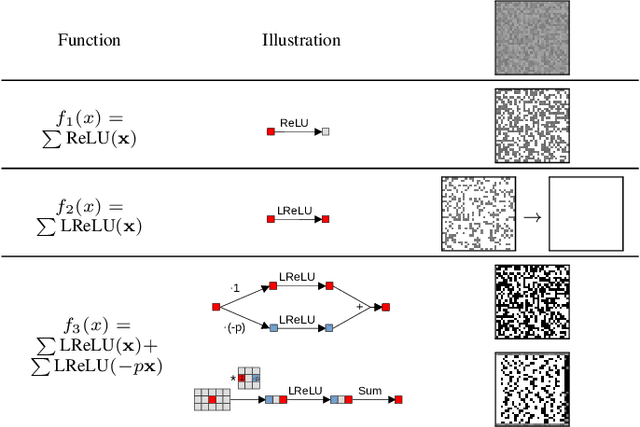
Activation maximization (AM) strives to generate optimal input stimuli, revealing features that trigger high responses in trained deep neural networks. AM is an important method of explainable AI. We demonstrate that AM fails to produce optimal input stimuli for simple functions containing ReLUs or Leaky ReLUs, casting doubt on the practical usefulness of AM and the visual interpretation of the generated images. This paper proposes a solution based on using Leaky ReLUs with a high negative slope in the backward pass while keeping the original, usually zero, slope in the forward pass. The approach significantly increases the maxima found by AM. The resulting ProxyGrad algorithm implements a novel optimization technique for neural networks that employs a secondary network as a proxy for gradient computation. This proxy network is designed to have a simpler loss landscape with fewer local maxima than the original network. Our chosen proxy network is an identical copy of the original network, including its weights, with distinct negative slopes in the Leaky ReLUs. Moreover, we show that ProxyGrad can be used to train the weights of Convolutional Neural Networks for classification such that, on some of the tested benchmarks, they outperform traditional networks.
TEVR: Improving Speech Recognition by Token Entropy Variance Reduction
Jun 25, 2022



This paper presents TEVR, a speech recognition model designed to minimize the variation in token entropy w.r.t. to the language model. This takes advantage of the fact that if the language model will reliably and accurately predict a token anyway, then the acoustic model doesn't need to be accurate in recognizing it. We train German ASR models with 900 million parameters and show that on CommonVoice German, TEVR scores a very competitive 3.64% word error rate, which outperforms the best reported results by a relative 16.89% reduction in word error rate. We hope that releasing our fully trained speech recognition pipeline to the community will lead to privacy-preserving offline virtual assistants in the future.
Bio-inspired Min-Nets Improve the Performance and Robustness of Deep Networks
Jan 06, 2022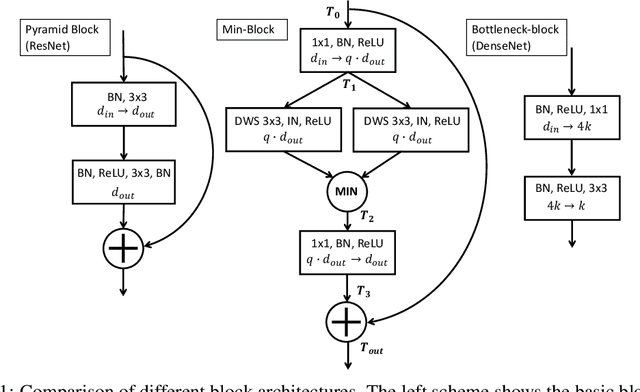
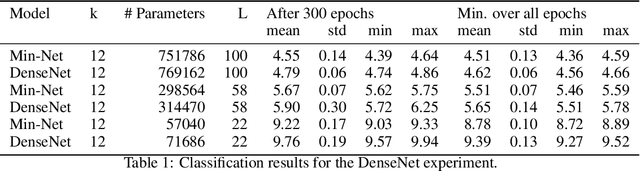
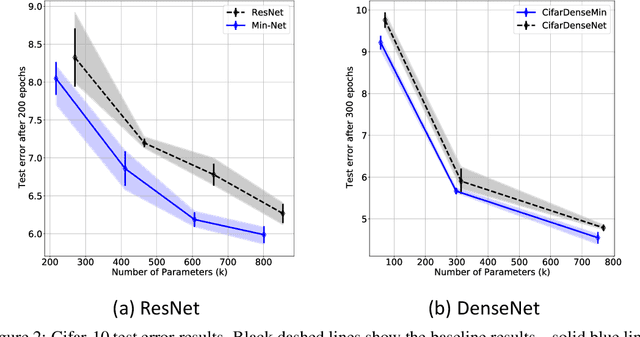
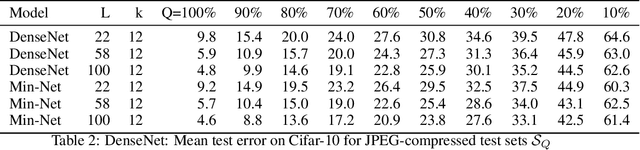
Min-Nets are inspired by end-stopped cortical cells with units that output the minimum of two learned filters. We insert such Min-units into state-of-the-art deep networks, such as the popular ResNet and DenseNet, and show that the resulting Min-Nets perform better on the Cifar-10 benchmark. Moreover, we show that Min-Nets are more robust against JPEG compression artifacts. We argue that the minimum operation is the simplest way of implementing an AND operation on pairs of filters and that such AND operations introduce a bias that is appropriate given the statistics of natural images.
Explainable COVID-19 Detection Using Chest CT Scans and Deep Learning
Nov 09, 2020
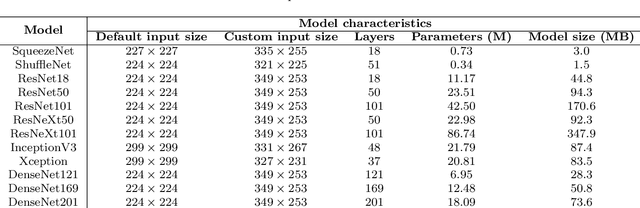
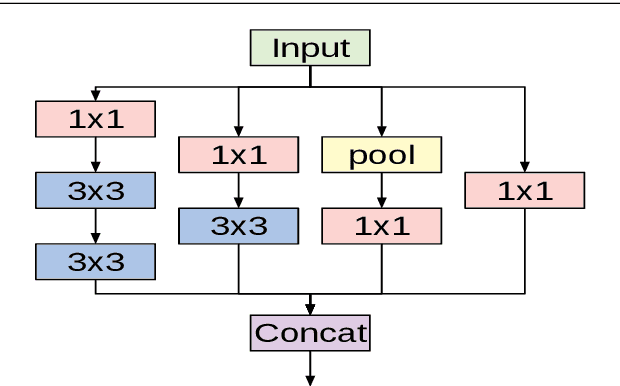
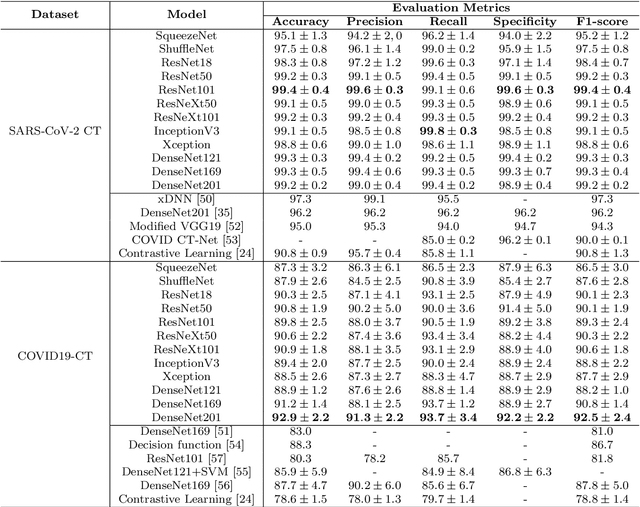
This paper explores how well deep learning models trained on chest CT images can diagnose COVID-19 infected people in a fast and automated process. To this end, we adopt advanced deep network architectures and propose a transfer learning strategy using custom-sized input tailored for each deep architecture to achieve the best performance. We conduct extensive sets of experiments on two CT image datasets, namely the SARS-CoV-2 CT-scan and the COVID19-CT. The obtained results show superior performances for our models compared with previous studies, where our best models achieve average accuracy, precision, sensitivity, specificity and F1 score of 99.4%, 99.6%, 99.8%, 99.6% and 99.4% on the SARS-CoV-2 dataset; and 92.9%, 91.3%, 93.7%, 92.2% and 92.5% on the COVID19-CT dataset, respectively. Furthermore, we apply two visualization techniques to provide visual explanations for the models' predictions. The visualizations show well-separated clusters for CT images of COVID-19 from other lung diseases, and accurate localizations of the COVID-19 associated regions.
Feature Products Yield Efficient Networks
Aug 18, 2020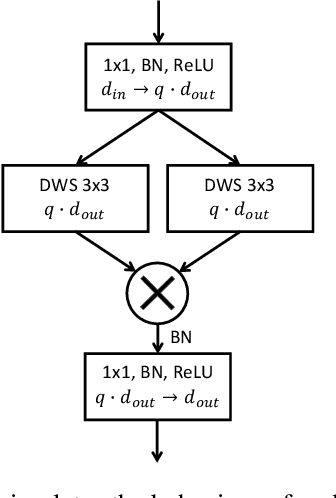

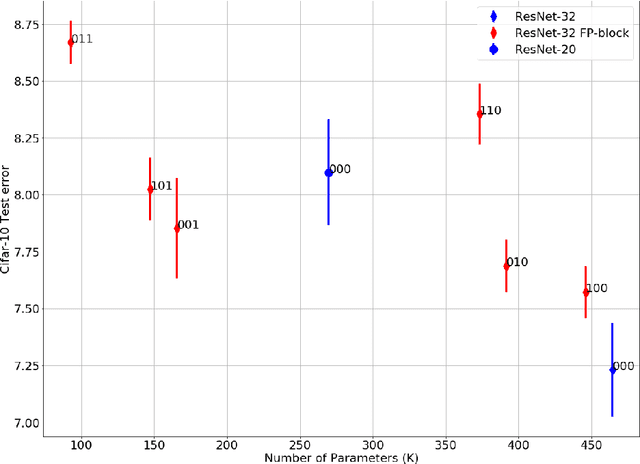
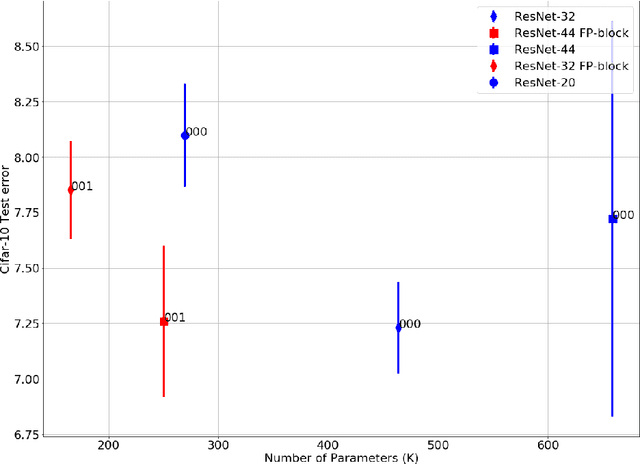
We introduce Feature-Product networks (FP-nets) as a novel deep-network architecture based on a new building block inspired by principles of biological vision. For each input feature map, a so-called FP-block learns two different filters, the outputs of which are then multiplied. Such FP-blocks are inspired by models of end-stopped neurons, which are common in cortical areas V1 and especially in V2. Convolutional neural networks can be transformed into parameter-efficient FP-nets by substituting conventional blocks of regular convolutions with FP-blocks. In this way, we create several novel FP-nets based on state-of-the-art networks and evaluate them on the Cifar-10 and ImageNet challenges. We show that the use of FP-blocks reduces the number of parameters significantly without decreasing generalization capability. Since so far heuristics and search algorithms have been used to find more efficient networks, it seems remarkable that we can obtain even more efficient networks based on a novel bio-inspired design principle.
Deep Convolutional Neural Networks as Generic Feature Extractors
Oct 06, 2017
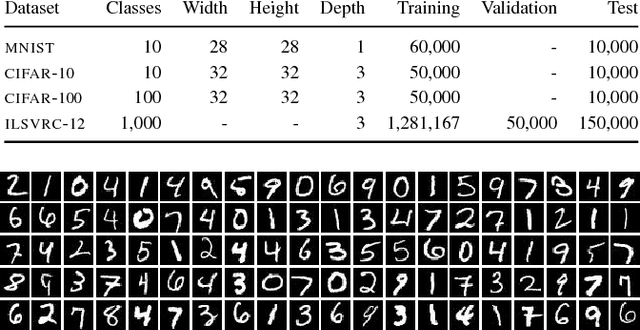


Recognizing objects in natural images is an intricate problem involving multiple conflicting objectives. Deep convolutional neural networks, trained on large datasets, achieve convincing results and are currently the state-of-the-art approach for this task. However, the long time needed to train such deep networks is a major drawback. We tackled this problem by reusing a previously trained network. For this purpose, we first trained a deep convolutional network on the ILSVRC2012 dataset. We then maintained the learned convolution kernels and only retrained the classification part on different datasets. Using this approach, we achieved an accuracy of 67.68 % on CIFAR-100, compared to the previous state-of-the-art result of 65.43 %. Furthermore, our findings indicate that convolutional networks are able to learn generic feature extractors that can be used for different tasks.
Recursive Autoconvolution for Unsupervised Learning of Convolutional Neural Networks
Mar 26, 2017

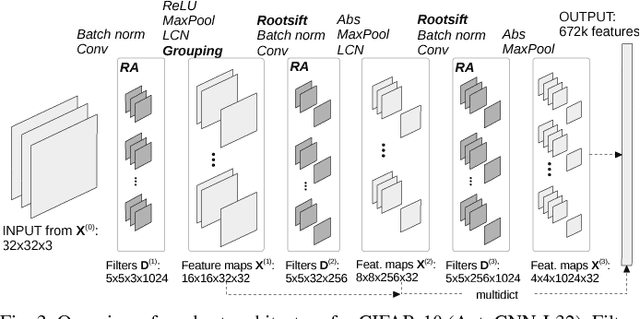
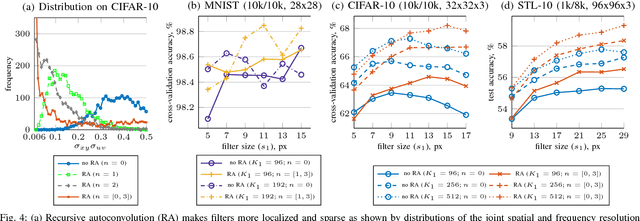
In visual recognition tasks, such as image classification, unsupervised learning exploits cheap unlabeled data and can help to solve these tasks more efficiently. We show that the recursive autoconvolution operator, adopted from physics, boosts existing unsupervised methods by learning more discriminative filters. We take well established convolutional neural networks and train their filters layer-wise. In addition, based on previous works we design a network which extracts more than 600k features per sample, but with the total number of trainable parameters greatly reduced by introducing shared filters in higher layers. We evaluate our networks on the MNIST, CIFAR-10, CIFAR-100 and STL-10 image classification benchmarks and report several state of the art results among other unsupervised methods.
A Hybrid Convolutional Variational Autoencoder for Text Generation
Feb 08, 2017
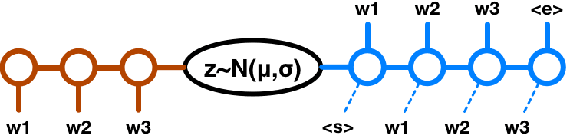
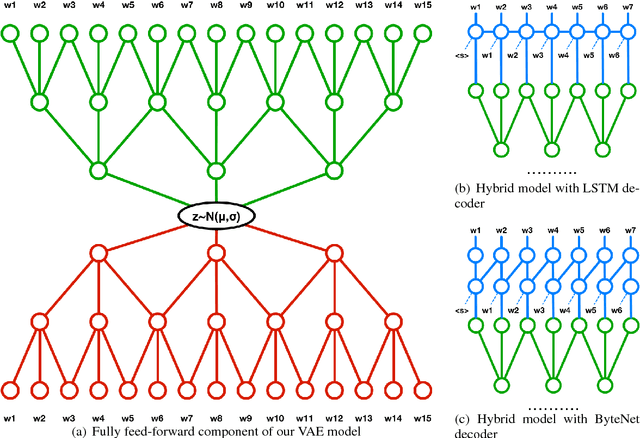

In this paper we explore the effect of architectural choices on learning a Variational Autoencoder (VAE) for text generation. In contrast to the previously introduced VAE model for text where both the encoder and decoder are RNNs, we propose a novel hybrid architecture that blends fully feed-forward convolutional and deconvolutional components with a recurrent language model. Our architecture exhibits several attractive properties such as faster run time and convergence, ability to better handle long sequences and, more importantly, it helps to avoid some of the major difficulties posed by training VAE models on textual data.
Recurrent Dropout without Memory Loss
Aug 05, 2016
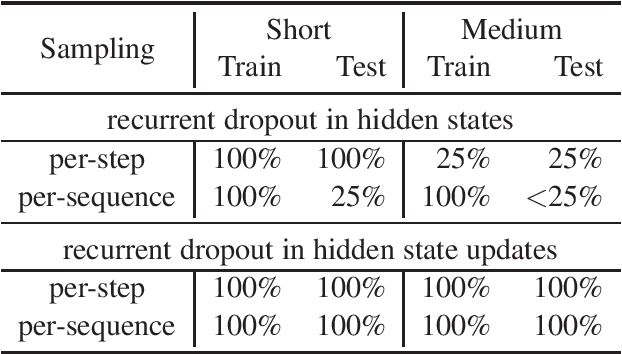
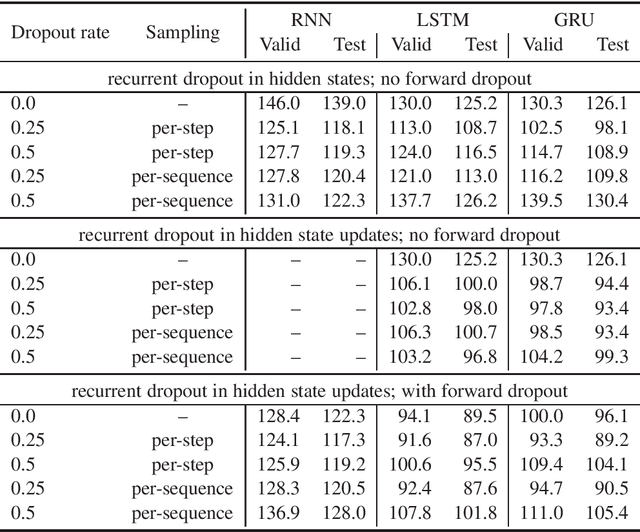
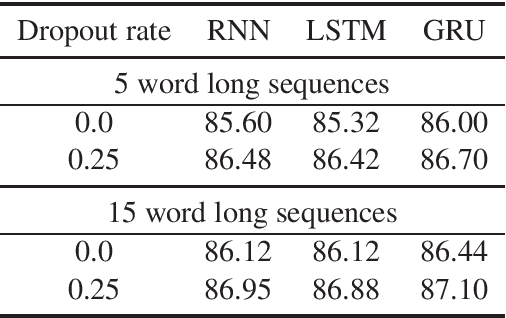
This paper presents a novel approach to recurrent neural network (RNN) regularization. Differently from the widely adopted dropout method, which is applied to \textit{forward} connections of feed-forward architectures or RNNs, we propose to drop neurons directly in \textit{recurrent} connections in a way that does not cause loss of long-term memory. Our approach is as easy to implement and apply as the regular feed-forward dropout and we demonstrate its effectiveness for Long Short-Term Memory network, the most popular type of RNN cells. Our experiments on NLP benchmarks show consistent improvements even when combined with conventional feed-forward dropout.