 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Accurate Evaluation of GANs for Language Generation
Jun 14, 2018



Generative Adversarial Networks (GANs) are a promising approach to language generation. The latest works introducing novel GAN models for language generation use n-gram based metrics for evaluation and only report single scores of the best run. In this paper, we argue that this often misrepresents the true picture and does not tell the full story, as GAN models can be extremely sensitive to the random initialization and small deviations from the best hyperparameter choice. In particular, we demonstrate that the previously used BLEU score is not sensitive to semantic deterioration of generated texts and propose alternative metrics that better capture the quality and diversity of the generated samples. We also conduct a set of experiments comparing a number of GAN models for text with a conventional Language Model (LM) and find that neither of the considered models performs convincingly better than the LM.
A Hybrid Convolutional Variational Autoencoder for Text Generation
Feb 08, 2017
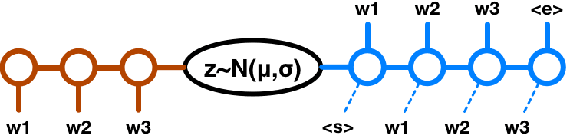
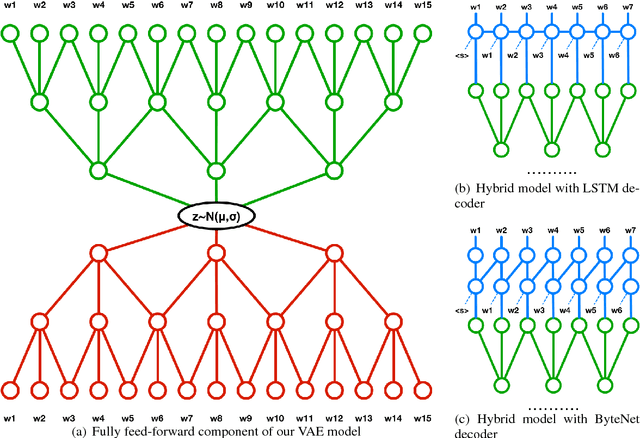

In this paper we explore the effect of architectural choices on learning a Variational Autoencoder (VAE) for text generation. In contrast to the previously introduced VAE model for text where both the encoder and decoder are RNNs, we propose a novel hybrid architecture that blends fully feed-forward convolutional and deconvolutional components with a recurrent language model. Our architecture exhibits several attractive properties such as faster run time and convergence, ability to better handle long sequences and, more importantly, it helps to avoid some of the major difficulties posed by training VAE models on textual data.
Recurrent Dropout without Memory Loss
Aug 05, 2016
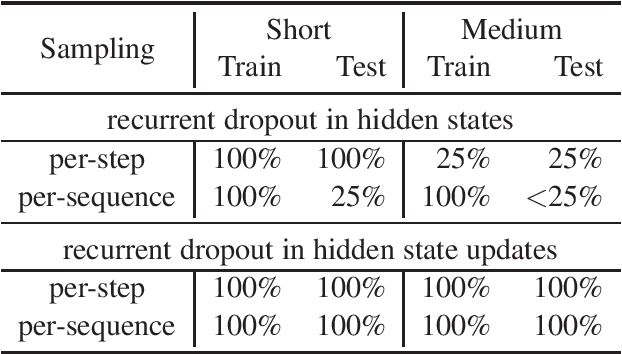
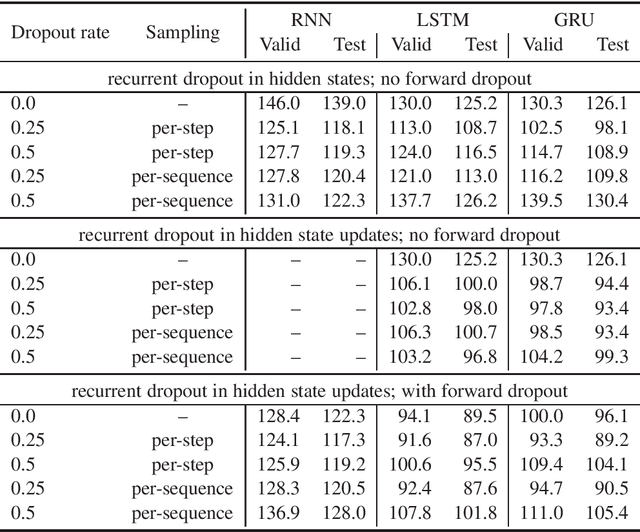
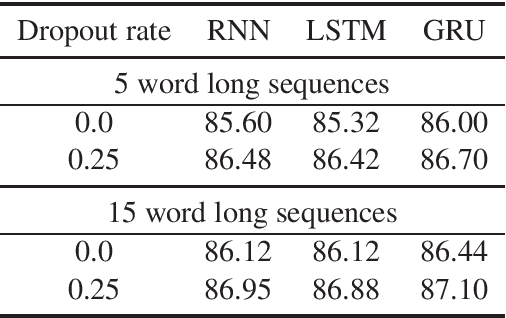
This paper presents a novel approach to recurrent neural network (RNN) regularization. Differently from the widely adopted dropout method, which is applied to \textit{forward} connections of feed-forward architectures or RNNs, we propose to drop neurons directly in \textit{recurrent} connections in a way that does not cause loss of long-term memory. Our approach is as easy to implement and apply as the regular feed-forward dropout and we demonstrate its effectiveness for Long Short-Term Memory network, the most popular type of RNN cells. Our experiments on NLP benchmarks show consistent improvements even when combined with conventional feed-forward dropout.