 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolutional Neural Networks as Generic Feature Extractors
Oct 06, 2017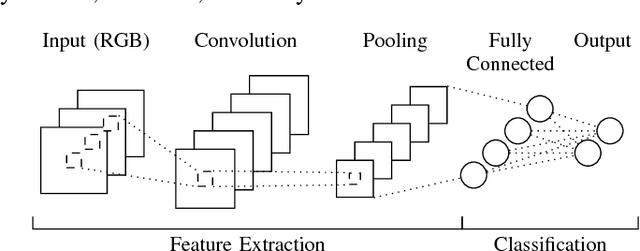
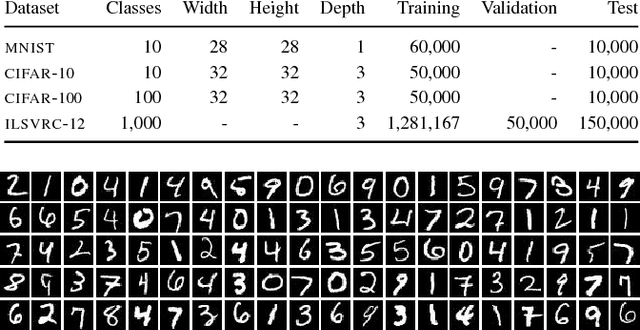


Recognizing objects in natural images is an intricate problem involving multiple conflicting objectives. Deep convolutional neural networks, trained on large datasets, achieve convincing results and are currently the state-of-the-art approach for this task. However, the long time needed to train such deep networks is a major drawback. We tackled this problem by reusing a previously trained network. For this purpose, we first trained a deep convolutional network on the ILSVRC2012 dataset. We then maintained the learned convolution kernels and only retrained the classification part on different datasets. Using this approach, we achieved an accuracy of 67.68 % on CIFAR-100, compared to the previous state-of-the-art result of 65.43 %. Furthermore, our findings indicate that convolutional networks are able to learn generic feature extractors that can be used for different tasks.