Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEVR: Improving Speech Recognition by Token Entropy Variance Reduction
Paper and Code
Jun 25, 2022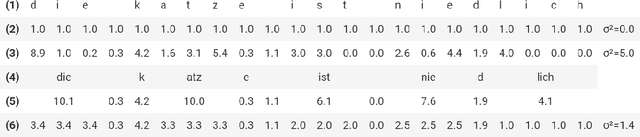



This paper presents TEVR, a speech recognition model designed to minimize the variation in token entropy w.r.t. to the language model. This takes advantage of the fact that if the language model will reliably and accurately predict a token anyway, then the acoustic model doesn't need to be accurate in recognizing it. We train German ASR models with 900 million parameters and show that on CommonVoice German, TEVR scores a very competitive 3.64% word error rate, which outperforms the best reported results by a relative 16.89% reduction in word error rate. We hope that releasing our fully trained speech recognition pipeline to the community will lead to privacy-preserving offline virtual assistants in the future.
* 10 pages including 2 pages appendix, 1 figure, 6 tables
View paper on