 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Distributionally Robust Bayesian Optimization with Continuous Context
Mar 26, 2025We address the challenge of sequential data-driven decision-making under context distributional uncertainty. This problem arises in numerous real-world scenarios where the learner optimizes black-box objective functions in the presence of uncontrollable contextual variables. We consider the setting where the context distribution is uncertain but known to lie within an ambiguity set defined as a ball in the Wasserstein distance. We propose a novel algorithm for Wasserstein Distributionally Robust Bayesian Optimization that can handle continuous context distributions while maintaining computational tractability. Our theoretical analysis combines recent results in self-normalized concentration in Hilbert spaces and finite-sample bounds for distributionally robust optimization to establish sublinear regret bounds that match state-of-the-art results. Through extensive comparisons with existing approaches on both synthetic and real-world problems, we demonstrate the simplicity, effectiveness, and practical applicability of our proposed method.
Online Residual Learning from Offline Experts for Pedestrian Tracking
Sep 09, 2024In this paper, we consider the problem of predicting unknown targets from data. We propose Online Residual Learning (ORL), a method that combines online adaptation with offline-trained predictions. At a lower level, we employ multiple offline predictions generated before or at the beginning of the prediction horizon. We augment every offline prediction by learning their respective residual error concerning the true target state online, using the recursive least squares algorithm. At a higher level, we treat the augmented lower-level predictors as experts, adopting the Prediction with Expert Advice framework. We utilize an adaptive softmax weighting scheme to form an aggregate prediction and provide guarantees for ORL in terms of regret. We employ ORL to boost performance in the setting of online pedestrian trajectory prediction. Based on data from the Stanford Drone Dataset, we show that ORL can demonstrate best-of-both-worlds performance.
Adaptive Bayesian Optimization for High-Precision Motion Systems
Apr 22, 2024Controller tuning and parameter optimization are crucial in system design to improve closed-loop system performance. Bayesian optimization has been established as an efficient model-free controller tuning and adaptation method. However, Bayesian optimization methods are computationally expensive and therefore difficult to use in real-time critical scenarios. In this work, we propose a real-time purely data-driven, model-free approach for adaptive control, by online tuning low-level controller parameters. We base our algorithm on GoOSE, an algorithm for safe and sample-efficient Bayesian optimization, for handling performance and stability criteria. We introduce multiple computational and algorithmic modifications for computational efficiency and parallelization of optimization steps. We further evaluate the algorithm's performance on a real precision-motion system utilized in semiconductor industry applications by modifying the payload and reference stepsize and comparing it to an interpolated constrained optimization-based baseline approach.
Online Identification of Stochastic Continuous-Time Wiener Models Using Sampled Data
Mar 09, 2024It is well known that ignoring the presence of stochastic disturbances in the identification of stochastic Wiener models leads to asymptotically biased estimators. On the other hand, optimal statistical identification, via likelihood-based methods, is sensitive to the assumptions on the data distribution and is usually based on relatively complex sequential Monte Carlo algorithms. We develop a simple recursive online estimation algorithm based on an output-error predictor, for the identification of continuous-time stochastic parametric Wiener models through stochastic approximation. The method is applicable to generic model parameterizations and, as demonstrated in the numerical simulation examples, it is robust with respect to the assumptions on the spectrum of the disturbance process.
Predictive Linear Online Tracking for Unknown Targets
Feb 15, 2024In this paper, we study the problem of online tracking in linear control systems, where the objective is to follow a moving target. Unlike classical tracking control, the target is unknown, non-stationary, and its state is revealed sequentially, thus, fitting the framework of online non-stochastic control. We consider the case of quadratic costs and propose a new algorithm, called predictive linear online tracking (PLOT). The algorithm uses recursive least squares with exponential forgetting to learn a time-varying dynamic model of the target. The learned model is used in the optimal policy under the framework of receding horizon control. We show the dynamic regret of PLOT scales with $\mathcal{O}(\sqrt{TV_T})$, where $V_T$ is the total variation of the target dynamics and $T$ is the time horizon. Unlike prior work, our theoretical results hold for non-stationary targets. We implement PLOT on a real quadrotor and provide open-source software, thus, showcasing one of the first successful applications of online control methods on real hardware.
Safe Risk-averse Bayesian Optimization for Controller Tuning
Jun 23, 2023Controller tuning and parameter optimization are crucial in system design to improve both the controller and underlying system performance. Bayesian optimization has been established as an efficient model-free method for controller tuning and adaptation. Standard methods, however, are not enough for high-precision systems to be robust with respect to unknown input-dependent noise and stable under safety constraints. In this work, we present a novel data-driven approach, RaGoOSE, for safe controller tuning in the presence of heteroscedastic noise, combining safe learning with risk-averse Bayesian optimization. We demonstrate the method for synthetic benchmark and compare its performance to established BO-based tuning methods. We further evaluate RaGoOSE performance on a real precision-motion system utilized in semiconductor industry applications and compare it to the built-in auto-tuning routine.
Implications of Regret on Stability of Linear Dynamical Systems
Nov 14, 2022
The setting of an agent making decisions under uncertainty and under dynamic constraints is common for the fields of optimal control, reinforcement learning and recently also for online learning. In the online learning setting, the quality of an agent's decision is often quantified by the concept of regret, comparing the performance of the chosen decisions to the best possible ones in hindsight. While regret is a useful performance measure, when dynamical systems are concerned, it is important to also assess the stability of the closed-loop system for a chosen policy. In this work, we show that for linear state feedback policies and linear systems subject to adversarial disturbances, linear regret implies asymptotic stability in both time-varying and time-invariant settings. Conversely, we also show that bounded input bounded state (BIBS) stability and summability of the state transition matrices imply linear regret.
Regret Analysis of Online Gradient Descent-based Iterative Learning Control with Model Mismatch
Apr 10, 2022
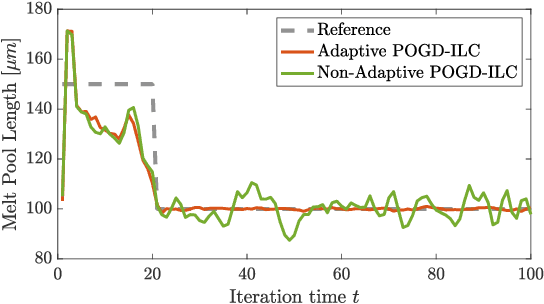
In Iterative Learning Control (ILC), a sequence of feedforward control actions is generated at each iteration on the basis of partial model knowledge and past measurements with the goal of steering the system toward a desired reference trajectory. This is framed here as an online learning task, where the decision-maker takes sequential decisions by solving a sequence of optimization problems having only partial knowledge of the cost functions. Having established this connection, the performance of an online gradient-descent based scheme using inexact gradient information is analyzed in the setting of dynamic and static regret, standard measures in online learning. Fundamental limitations of the scheme and its integration with adaptation mechanisms are further investigated, followed by numerical simulations on a benchmark ILC problem.