 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Quantum Harmonizer: Generating Chord Progressions and Other Sonification Methods with the VQE Algorithm
Sep 21, 2023This work investigates a case study of using physical-based sonification of Quadratic Unconstrained Binary Optimization (QUBO) problems, optimized by the Variational Quantum Eigensolver (VQE) algorithm. The VQE approximates the solution of the problem by using an iterative loop between the quantum computer and a classical optimization routine. This work explores the intermediary statevectors found in each VQE iteration as the means of sonifying the optimization process itself. The implementation was realised in the form of a musical interface prototype named Variational Quantum Harmonizer (VQH), providing potential design strategies for musical applications, focusing on chords, chord progressions, and arpeggios. The VQH can be used both to enhance data visualization or to create artistic pieces. The methodology is also relevant in terms of how an artist would gain intuition towards achieving a desired musical sound by carefully designing QUBO cost functions. Flexible mapping strategies could supply a broad portfolio of sounds for QUBO and quantum-inspired musical compositions, as demonstrated in a case study composition, "Dependent Origination" by Peter Thomas and Paulo Itaborai.
Teaching Qubits to Sing: Mission Impossible?
Jul 21, 2022
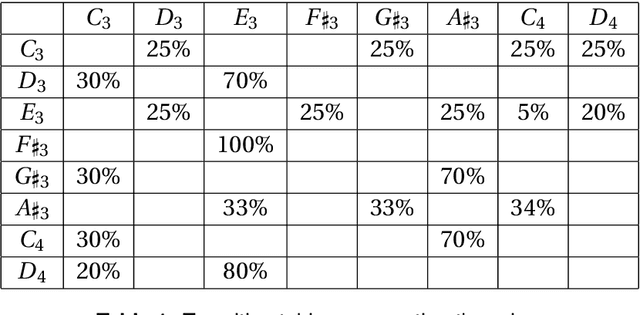

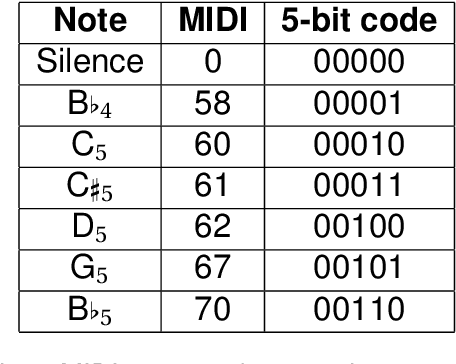
This paper introduces a system that learns to sing new tunes by listening to examples. It extracts sequencing rules from input music and uses these rules to generate new tunes, which are sung by a vocal synthesiser. We developed a method to represent rules for musical composition as quantum circuits. We claim that such musical rules are quantum native: they are naturally encodable in the amplitudes of quantum states. To evaluate a rule to generate a subsequent event, the system builds the respective quantum circuit dynamically and measures it. After a brief discussion about the vocal synthesis methods that we have been experimenting with, the paper introduces our novel generative music method through a practical example. The paper shows some experiments and concludes with a discussion about harnessing the creative potential of the system.
Word Embeddings for Automatic Equalization in Audio Mixing
Feb 17, 2022
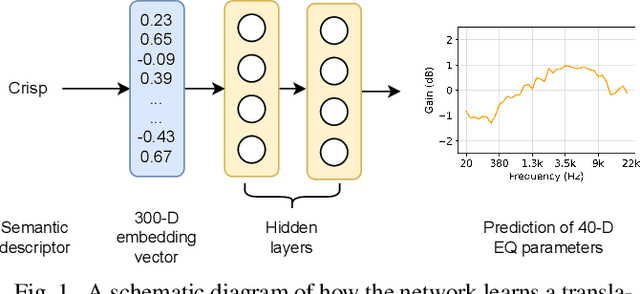
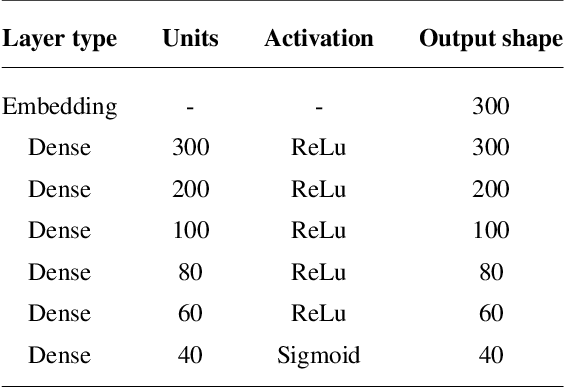
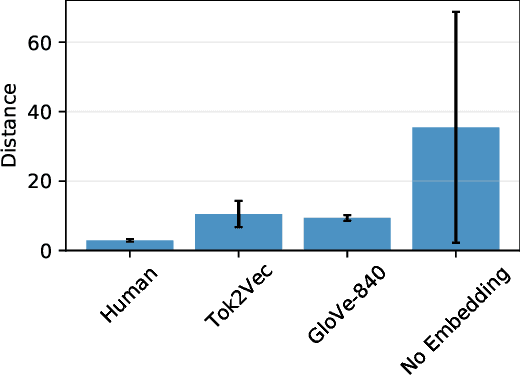
In recent years, machine learning has been widely adopted to automate the audio mixing process. Automatic mixing systems have been applied to various audio effects such as gain-adjustment, stereo panning, equalization, and reverberation. These systems can be controlled through visual interfaces, providing audio examples, using knobs, and semantic descriptors. Using semantic descriptors or textual information to control these systems is an effective way for artists to communicate their creative goals. Furthermore, sometimes artists use non-technical words that may not be understood by the mixing system, or even a mixing engineer. In this paper, we explore the novel idea of using word embeddings to represent semantic descriptors. Word embeddings are generally obtained by training neural networks on large corpora of written text. These embeddings serve as the input layer of the neural network to create a translation from words to EQ settings. Using this technique, the machine learning model can also generate EQ settings for semantic descriptors that it has not seen before. We perform experiments to demonstrate the feasibility of this idea. In addition, we compare the EQ settings of humans with the predictions of the neural network to evaluate the quality of predictions. The results showed that the embedding layer enables the neural network to understand semantic descriptors. We observed that the models with embedding layers perform better those without embedding layers, but not as good as human labels.
A Quantum Natural Language Processing Approach to Musical Intelligence
Nov 10, 2021
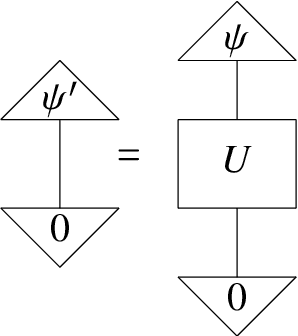
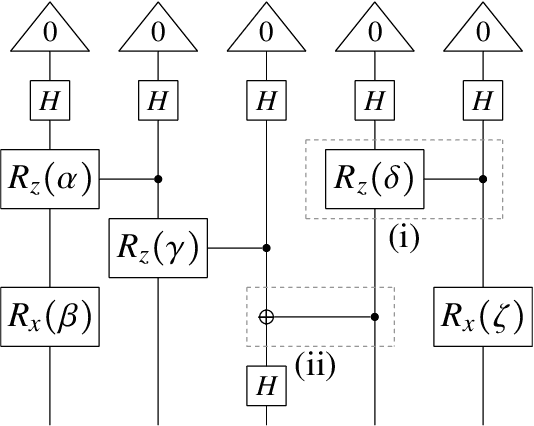
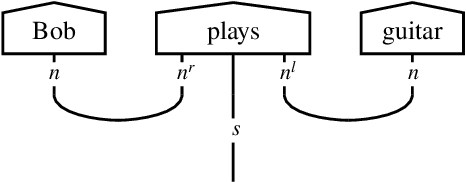
There has been tremendous progress in Artificial Intelligence (AI) for music, in particular for musical composition and access to large databases for commercialisation through the Internet. We are interested in further advancing this field, focusing on composition. In contrast to current black-box AI methods, we are championing an interpretable compositional outlook on generative music systems. In particular, we are importing methods from the Distributional Compositional Categorical (DisCoCat) modelling framework for Natural Language Processing (NLP), motivated by musical grammars. Quantum computing is a nascent technology, which is very likely to impact the music industry in time to come. Thus, we are pioneering a Quantum Natural Language Processing (QNLP) approach to develop a new generation of intelligent musical systems. This work follows from previous experimental implementations of DisCoCat linguistic models on quantum hardware. In this chapter, we present Quanthoven, the first proof-of-concept ever built, which (a) demonstrates that it is possible to program a quantum computer to learn to classify music that conveys different meanings and (b) illustrates how such a capability might be leveraged to develop a system to compose meaningful pieces of music. After a discussion about our current understanding of music as a communication medium and its relationship to natural language, the chapter focuses on the techniques developed to (a) encode musical compositions as quantum circuits, and (b) design a quantum classifier. The chapter ends with demonstrations of compositions created with the system.
You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection
Sep 01, 2021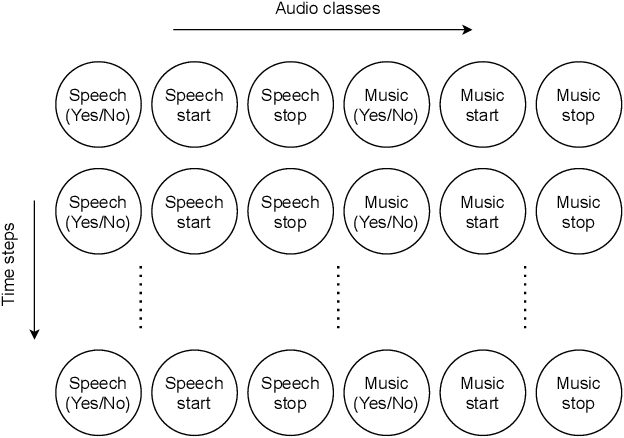
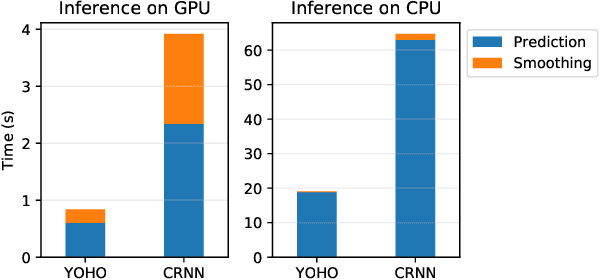
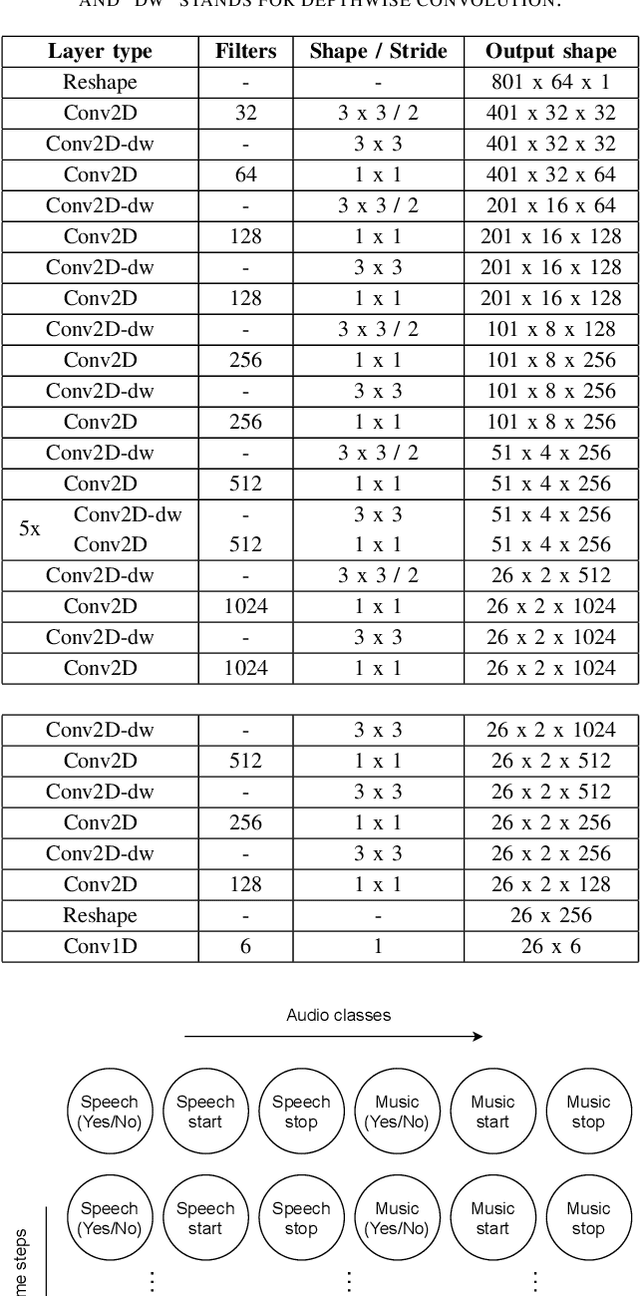
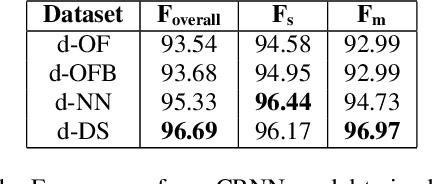
Audio segmentation and sound event detection are crucial topics in machine listening that aim to detect acoustic classes and their respective boundaries. It is useful for audio-content analysis, speech recognition, audio-indexing, and music information retrieval. In recent years, most research articles adopt segmentation-by-classification. This technique divides audio into small frames and individually performs classification on these frames. In this paper, we present a novel approach called You Only Hear Once (YOHO), which is inspired by the YOLO algorithm popularly adopted in Computer Vision. We convert the detection of acoustic boundaries into a regression problem instead of frame-based classification. This is done by having separate output neurons to detect the presence of an audio class and predict its start and end points. YOHO obtained a higher F-measure and lower error rate than the state-of-the-art Convolutional Recurrent Neural Network on multiple datasets. As YOHO is purely a convolutional neural network and has no recurrent layers, it is faster during inference. In addition, as this approach is more end-to-end and predicts acoustic boundaries directly, it is significantly quicker during post-processing and smoothing.
Artificially Synthesising Data for Audio Classification and Segmentation to Improve Speech and Music Detection in Radio Broadcast
Feb 19, 2021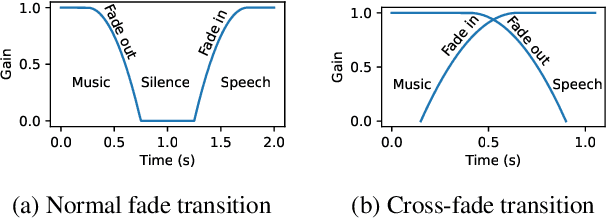
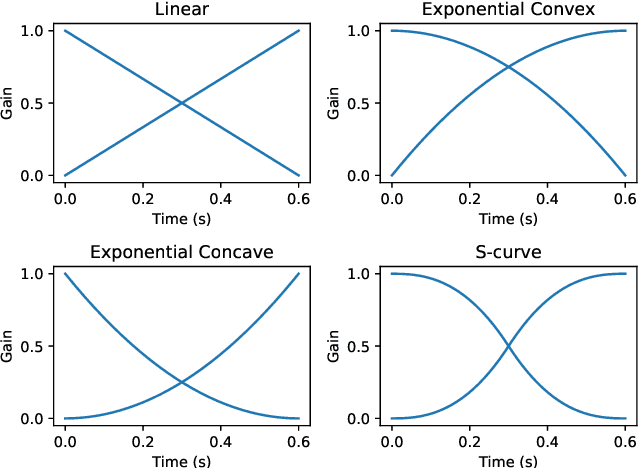
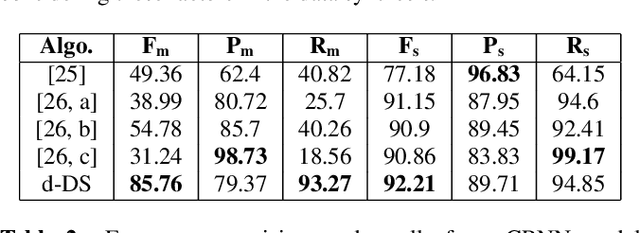
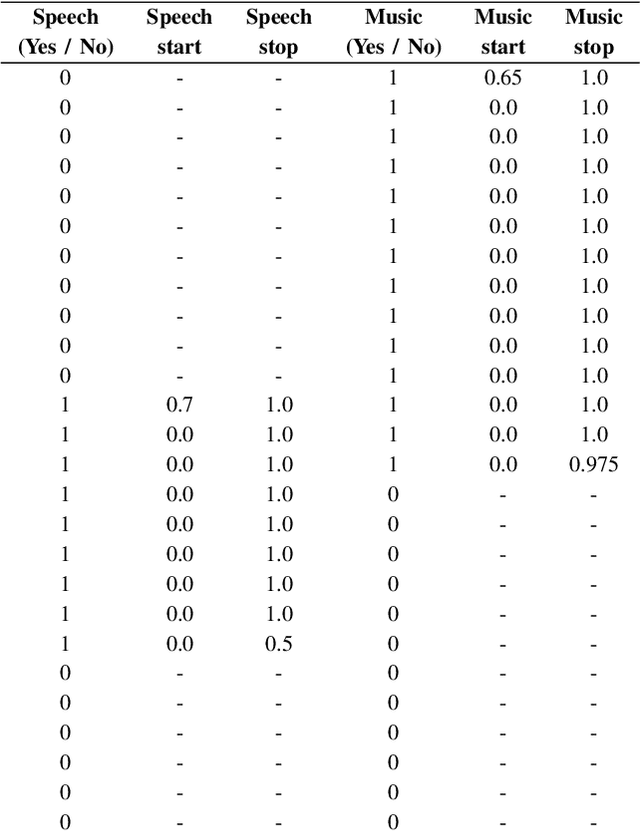
Segmenting audio into homogeneous sections such as music and speech helps us understand the content of audio. It is useful as a pre-processing step to index, store, and modify audio recordings, radio broadcasts and TV programmes. Deep learning models for segmentation are generally trained on copyrighted material, which cannot be shared. Annotating these datasets is time-consuming and expensive and therefore, it significantly slows down research progress. In this study, we present a novel procedure that artificially synthesises data that resembles radio signals. We replicate the workflow of a radio DJ in mixing audio and investigate parameters like fade curves and audio ducking. We trained a Convolutional Recurrent Neural Network (CRNN) on this synthesised data and outperformed state-of-the-art algorithms for music-speech detection. This paper demonstrates the data synthesis procedure as a highly effective technique to generate large datasets to train deep neural networks for audio segmentation.
On Interfacing the Brain with Quantum Computers: An Approach to Listen to the Logic of the Mind
Jan 17, 2021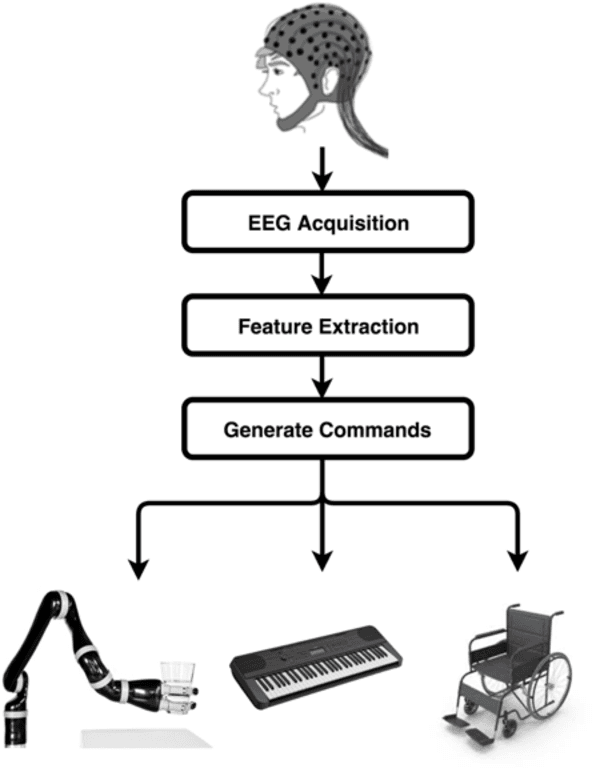
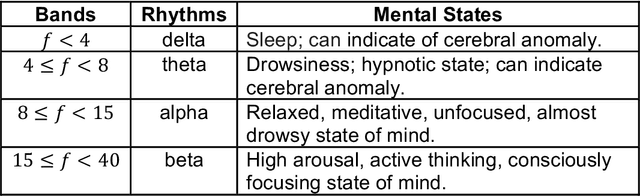

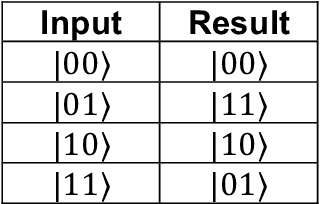
This chapter presents a quantum computing-based approach to study and harness neuronal correlates of mental activity for the development of Brain-Computer Interface (BCI) systems. It introduces the notion of a logic of the mind, where neurophysiological data are encoded as logical expressions representing mental activity. Effective logical expressions are likely to be extensive, involving dozens of variables. Large expressions require considerable computational power to be processed. This is problematic for BCI applications because they require fast reaction times to execute sequences of commands. Quantum computers hold much promise in terms of processing speed for some problems, including those involving logical expressions. Hence, we propose to use quantum computers to process the logic of the mind. The chapter begins with an introduction to BCI and the electroencephalogram, which is the neurophysiological signal that is normally used in BCI. Then, it briefly discusses how the EEG corresponds to mental states, followed by an introduction to the logic of the mind. After that, there is an overview of quantum computing, focusing on the basics deemed necessary to understand how it processes logical expressions. An example of a BCI system is presented. In a nutshell, the system reads the EEG and builds logical expressions, which are sent to a quantum computer to solve them. In turn, the system converts the results into sounds by means of a bespoke synthesiser. Essentially, the BCI here is a musical instrument controlled by the mind of the player. Our BCI is a proof-of-concept aimed at demonstrating how quantum computing may support the development of sophisticated BCI systems. The remaining of the chapter is devoted to technical and practical considerations on the limitations of current quantum computing hardware technology and scalability of the system.