 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embeddings for Automatic Equalization in Audio Mixing
Paper and Code

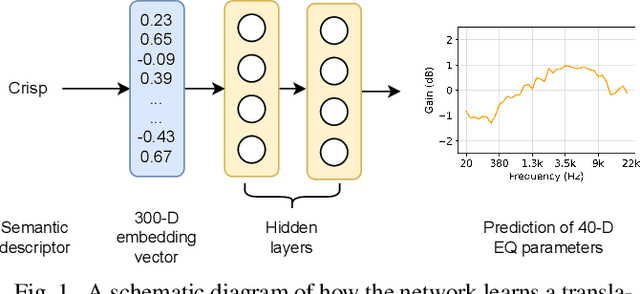
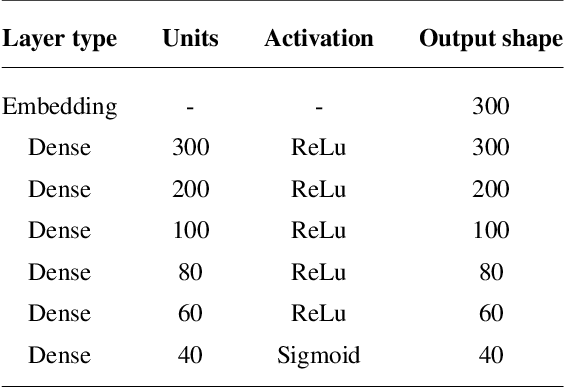
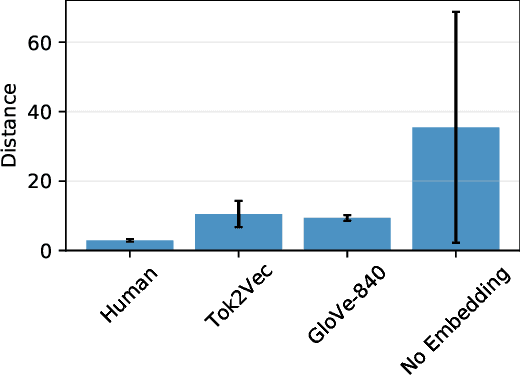
In recent years, machine learning has been widely adopted to automate the audio mixing process. Automatic mixing systems have been applied to various audio effects such as gain-adjustment, stereo panning, equalization, and reverberation. These systems can be controlled through visual interfaces, providing audio examples, using knobs, and semantic descriptors. Using semantic descriptors or textual information to control these systems is an effective way for artists to communicate their creative goals. Furthermore, sometimes artists use non-technical words that may not be understood by the mixing system, or even a mixing engineer. In this paper, we explore the novel idea of using word embeddings to represent semantic descriptors. Word embeddings are generally obtained by training neural networks on large corpora of written text. These embeddings serve as the input layer of the neural network to create a translation from words to EQ settings. Using this technique, the machine learning model can also generate EQ settings for semantic descriptors that it has not seen before. We perform experiments to demonstrate the feasibility of this idea. In addition, we compare the EQ settings of humans with the predictions of the neural network to evaluate the quality of predictions. The results showed that the embedding layer enables the neural network to understand semantic descriptors. We observed that the models with embedding layers perform better those without embedding layers, but not as good as human labels.