 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much to Dereverberate? Low-Latency Single-Channel Speech Enhancement in Distant Microphone Scenarios
May 02, 2025Dereverberation is an important sub-task of Speech Enhancement (SE) to improve the signal's intelligibility and quality. However, it remains challenging because the reverberation is highly correlated with the signal. Furthermore, the single-channel SE literature has predominantly focused on rooms with short reverb times (typically under 1 second), smaller rooms (under volumes of 1000 cubic meters) and relatively short distances (up to 2 meters). In this paper, we explore real-time low-latency single-channel SE under distant microphone scenarios, such as 5 to 10 meters, and focus on conference rooms and theatres, with larger room dimensions and reverberation times. Such a setup is useful for applications such as lecture demonstrations, drama, and to enhance stage acoustics. First, we show that single-channel SE in such challenging scenarios is feasible. Second, we investigate the relationship between room volume and reverberation time, and demonstrate its importance when randomly simulating room impulse responses. Lastly, we show that for dereverberation with short decay times, preserving early reflections before decaying the transfer function of the room improves overall signal quality.
Real-time Low-latency Music Source Separation using Hybrid Spectrogram-TasNet
Feb 27, 2024There have been significant advances in deep learning for music demixing in recent years. However, there has been little attention given to how these neural networks can be adapted for real-time low-latency applications, which could be helpful for hearing aids, remixing audio streams and live shows. In this paper, we investigate the various challenges involved in adapting current demixing models in the literature for this use case. Subsequently, inspired by the Hybrid Demucs architecture, we propose the Hybrid Spectrogram Time-domain Audio Separation Network HS-TasNet, which utilises the advantages of spectral and waveform domains. For a latency of 23 ms, the HS-TasNet obtains an overall signal-to-distortion ratio (SDR) of 4.65 on the MusDB test set, and increases to 5.55 with additional training data. These results demonstrate the potential of efficient demixing for real-time low-latency music applications.
Word Embeddings for Automatic Equalization in Audio Mixing
Feb 17, 2022
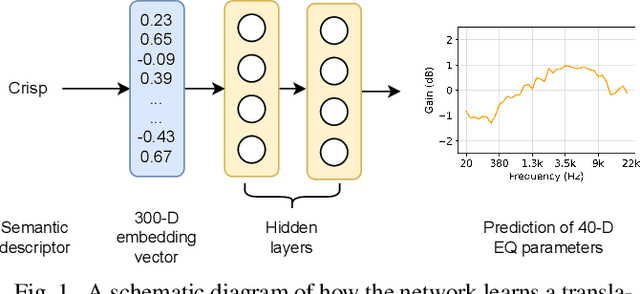
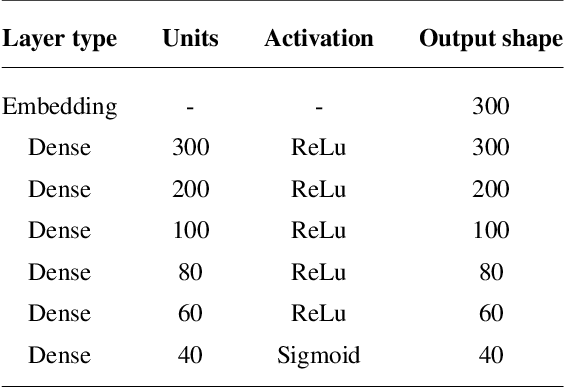
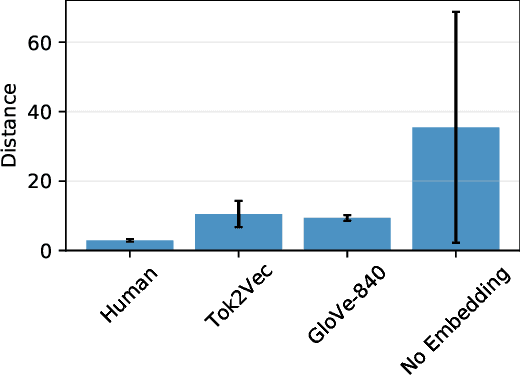
In recent years, machine learning has been widely adopted to automate the audio mixing process. Automatic mixing systems have been applied to various audio effects such as gain-adjustment, stereo panning, equalization, and reverberation. These systems can be controlled through visual interfaces, providing audio examples, using knobs, and semantic descriptors. Using semantic descriptors or textual information to control these systems is an effective way for artists to communicate their creative goals. Furthermore, sometimes artists use non-technical words that may not be understood by the mixing system, or even a mixing engineer. In this paper, we explore the novel idea of using word embeddings to represent semantic descriptors. Word embeddings are generally obtained by training neural networks on large corpora of written text. These embeddings serve as the input layer of the neural network to create a translation from words to EQ settings. Using this technique, the machine learning model can also generate EQ settings for semantic descriptors that it has not seen before. We perform experiments to demonstrate the feasibility of this idea. In addition, we compare the EQ settings of humans with the predictions of the neural network to evaluate the quality of predictions. The results showed that the embedding layer enables the neural network to understand semantic descriptors. We observed that the models with embedding layers perform better those without embedding layers, but not as good as human labels.
You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection
Sep 01, 2021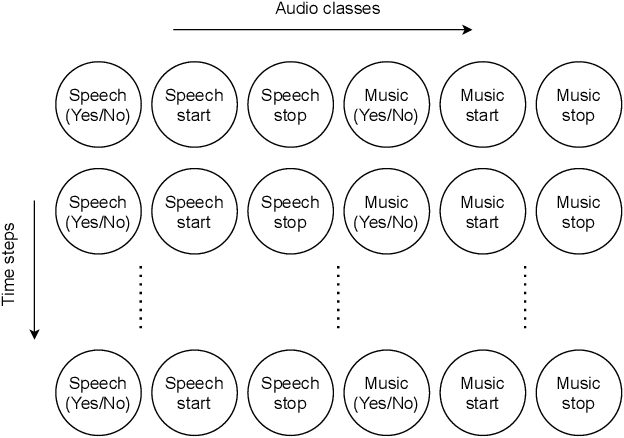
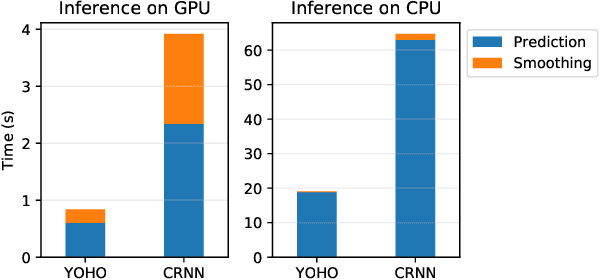
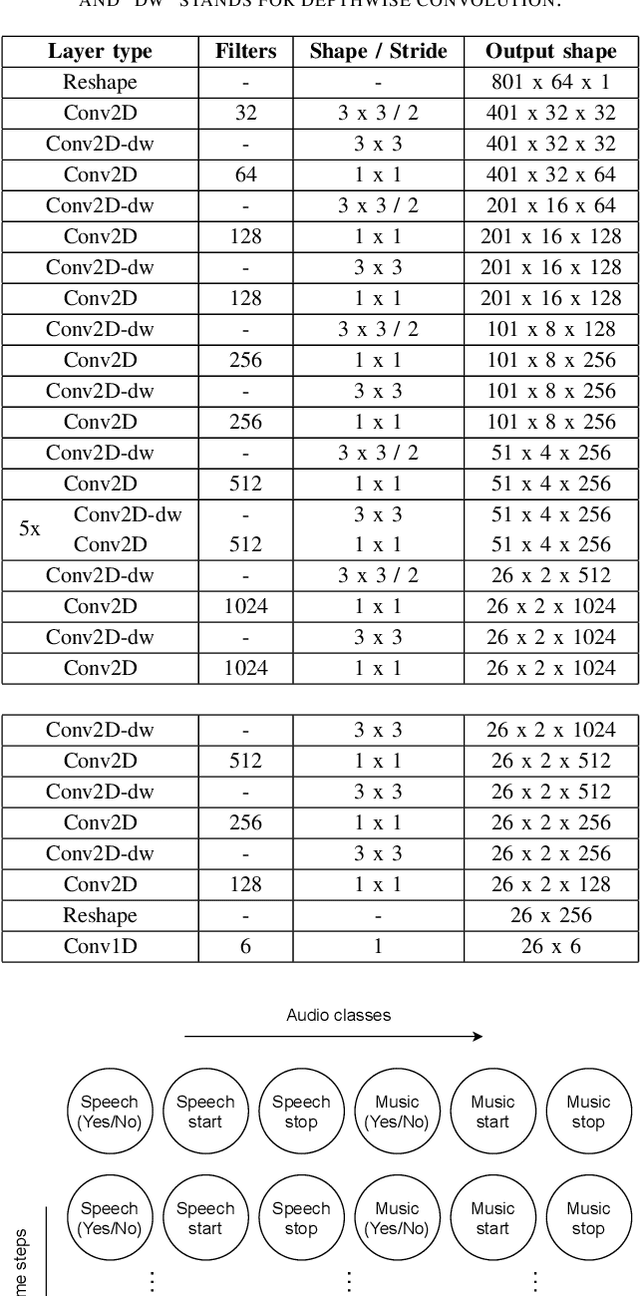
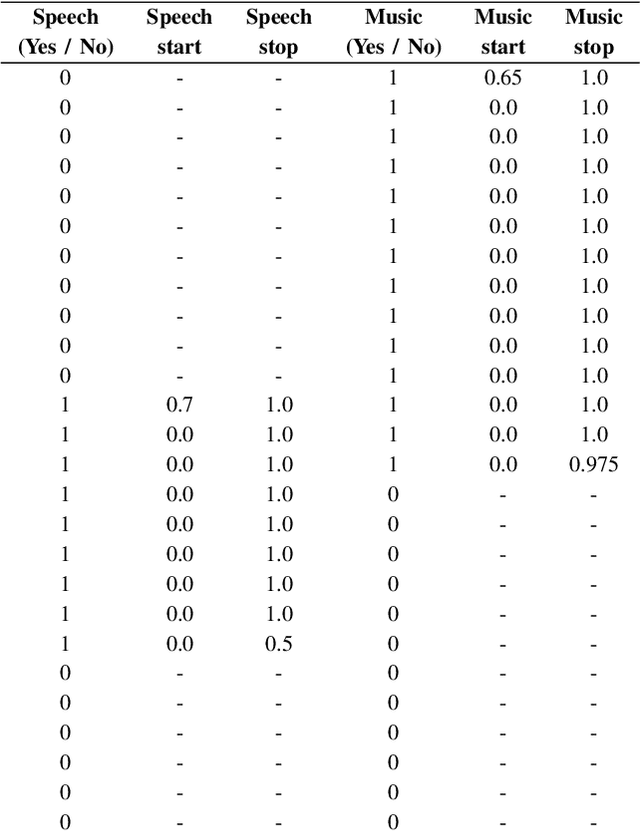
Audio segmentation and sound event detection are crucial topics in machine listening that aim to detect acoustic classes and their respective boundaries. It is useful for audio-content analysis, speech recognition, audio-indexing, and music information retrieval. In recent years, most research articles adopt segmentation-by-classification. This technique divides audio into small frames and individually performs classification on these frames. In this paper, we present a novel approach called You Only Hear Once (YOHO), which is inspired by the YOLO algorithm popularly adopted in Computer Vision. We convert the detection of acoustic boundaries into a regression problem instead of frame-based classification. This is done by having separate output neurons to detect the presence of an audio class and predict its start and end points. YOHO obtained a higher F-measure and lower error rate than the state-of-the-art Convolutional Recurrent Neural Network on multiple datasets. As YOHO is purely a convolutional neural network and has no recurrent layers, it is faster during inference. In addition, as this approach is more end-to-end and predicts acoustic boundaries directly, it is significantly quicker during post-processing and smoothing.
Artificially Synthesising Data for Audio Classification and Segmentation to Improve Speech and Music Detection in Radio Broadcast
Feb 19, 2021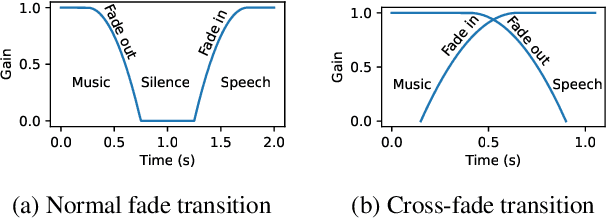
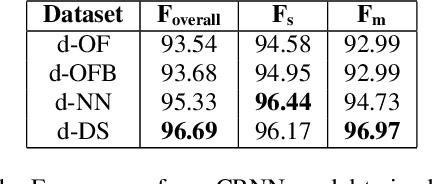
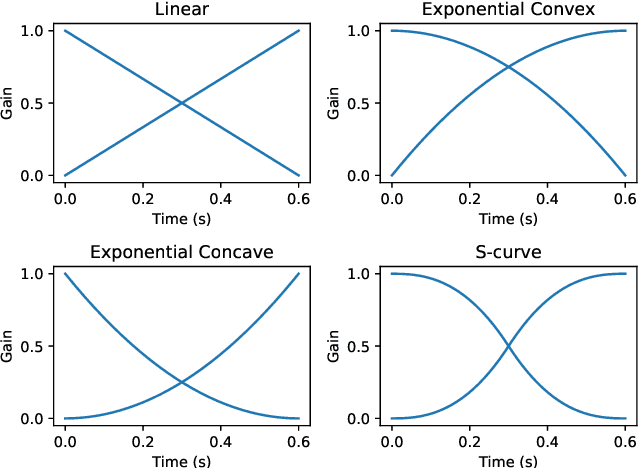
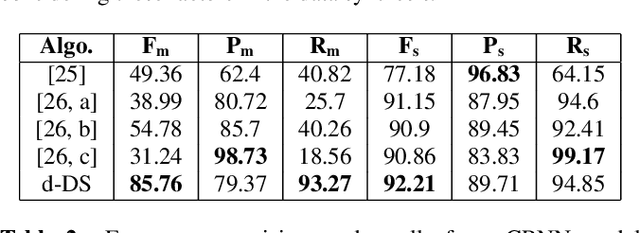
Segmenting audio into homogeneous sections such as music and speech helps us understand the content of audio. It is useful as a pre-processing step to index, store, and modify audio recordings, radio broadcasts and TV programmes. Deep learning models for segmentation are generally trained on copyrighted material, which cannot be shared. Annotating these datasets is time-consuming and expensive and therefore, it significantly slows down research progress. In this study, we present a novel procedure that artificially synthesises data that resembles radio signals. We replicate the workflow of a radio DJ in mixing audio and investigate parameters like fade curves and audio ducking. We trained a Convolutional Recurrent Neural Network (CRNN) on this synthesised data and outperformed state-of-the-art algorithms for music-speech detection. This paper demonstrates the data synthesis procedure as a highly effective technique to generate large datasets to train deep neural networks for audio segmentation.