 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection
Paper and Code
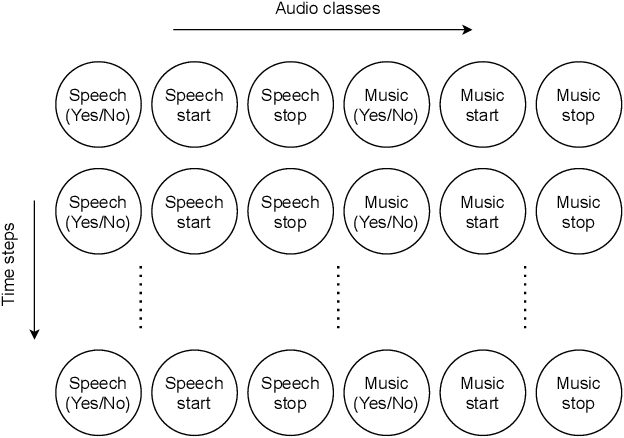
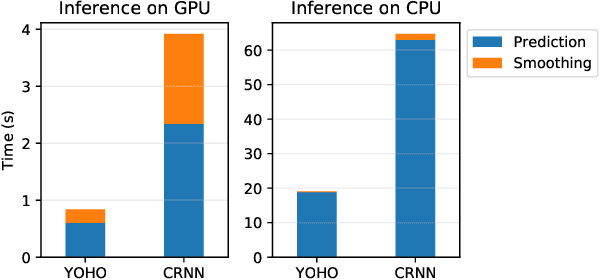
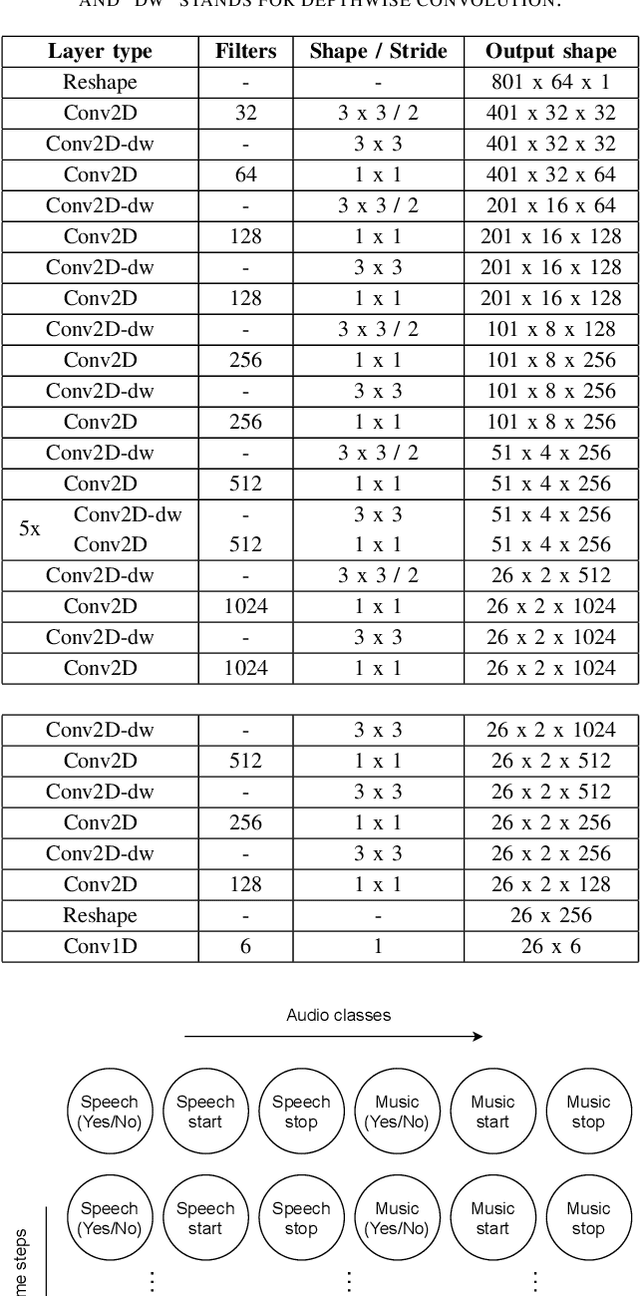
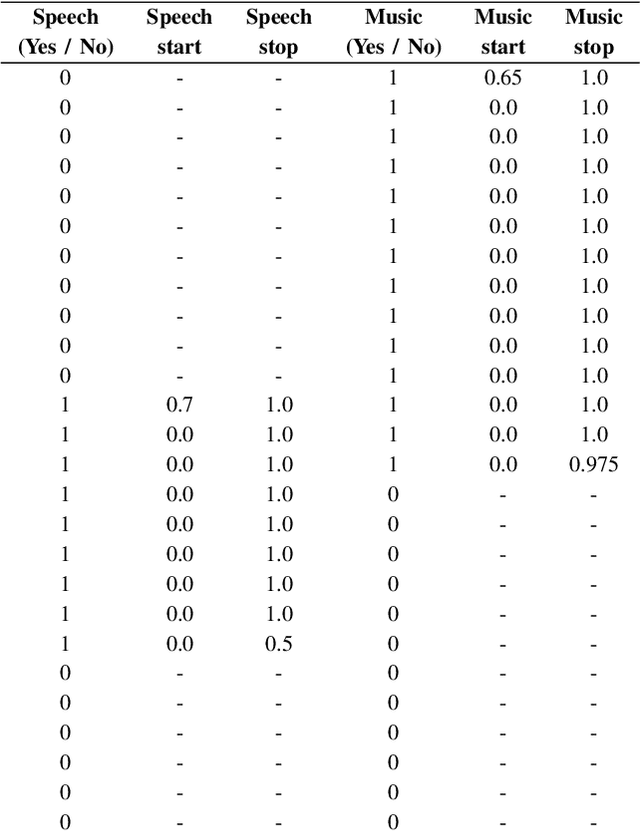
Audio segmentation and sound event detection are crucial topics in machine listening that aim to detect acoustic classes and their respective boundaries. It is useful for audio-content analysis, speech recognition, audio-indexing, and music information retrieval. In recent years, most research articles adopt segmentation-by-classification. This technique divides audio into small frames and individually performs classification on these frames. In this paper, we present a novel approach called You Only Hear Once (YOHO), which is inspired by the YOLO algorithm popularly adopted in Computer Vision. We convert the detection of acoustic boundaries into a regression problem instead of frame-based classification. This is done by having separate output neurons to detect the presence of an audio class and predict its start and end points. YOHO obtained a higher F-measure and lower error rate than the state-of-the-art Convolutional Recurrent Neural Network on multiple datasets. As YOHO is purely a convolutional neural network and has no recurrent layers, it is faster during inference. In addition, as this approach is more end-to-end and predicts acoustic boundaries directly, it is significantly quicker during post-processing and smoothing.