 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidening Access to Applied Machine Learning with TinyML
Jun 09, 2021
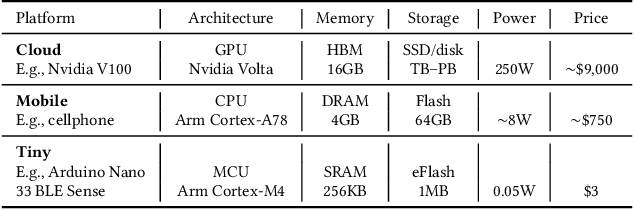

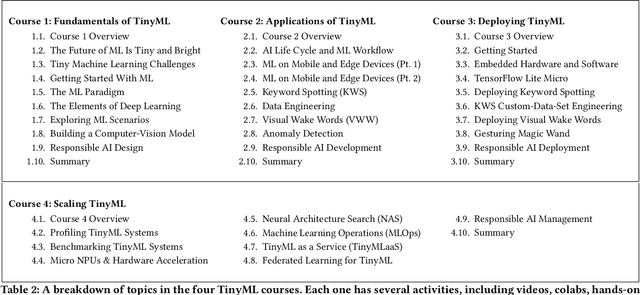
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
Causal Inference through the Method of Direct Estimation
Apr 01, 2017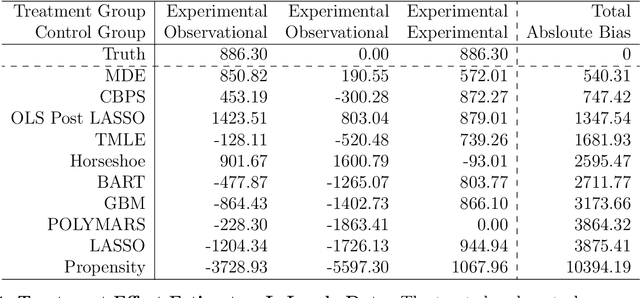
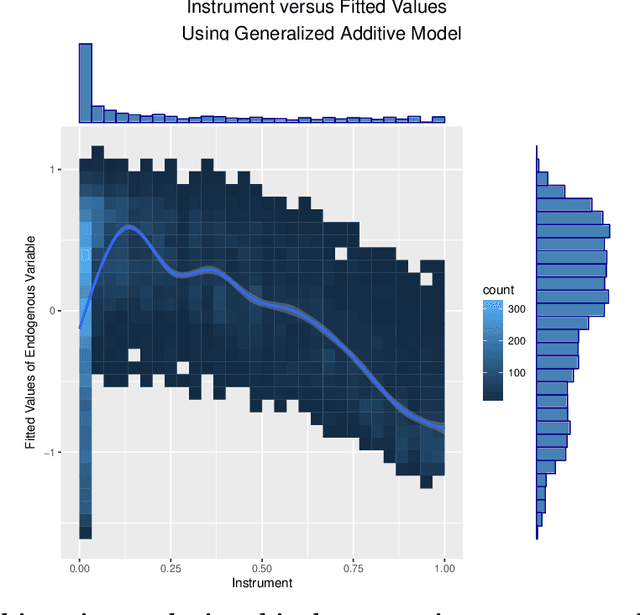
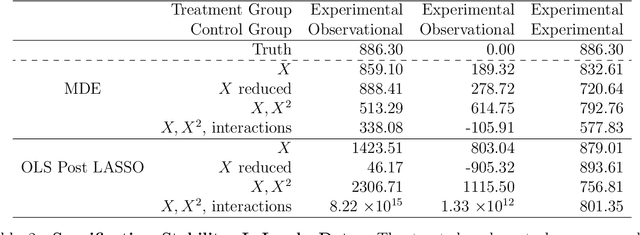
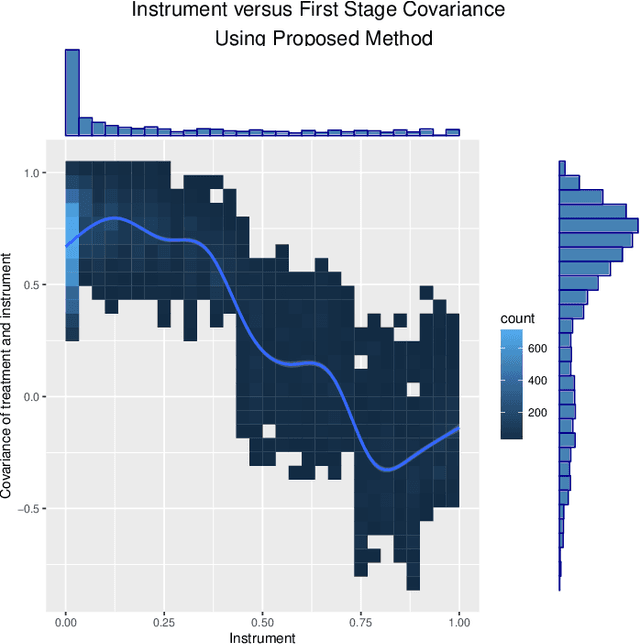
The intersection of causal inference and machine learning is a rapidly advancing field. We propose a new approach, the method of direct estimation, that draws on both traditions in order to obtain nonparametric estimates of treatment effects. The approach focuses on estimating the effect of fluctuations in a treatment variable on an outcome. A tensor-spline implementation enables rich interactions between functional bases allowing for the approach to capture treatment/covariate interactions. We show how new innovations in Bayesian sparse modeling readily handle the proposed framework, and then document its performance in simulation and applied examples. Furthermore we show how the method of direct estimation can easily extend to structural estimators commonly used in a variety of disciplines, like instrumental variables, mediation analysis, and sequential g-estimation.
Delving Deeper into MOOC Student Dropout Prediction
Feb 21, 2017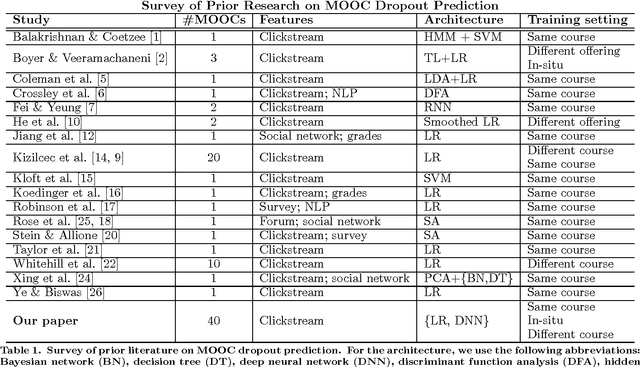
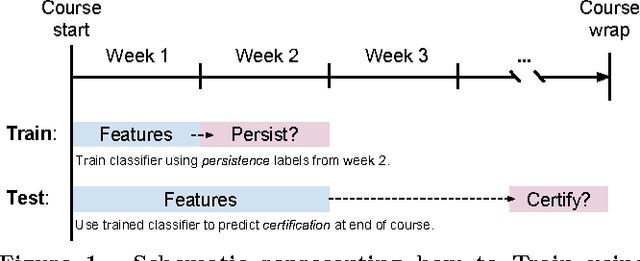
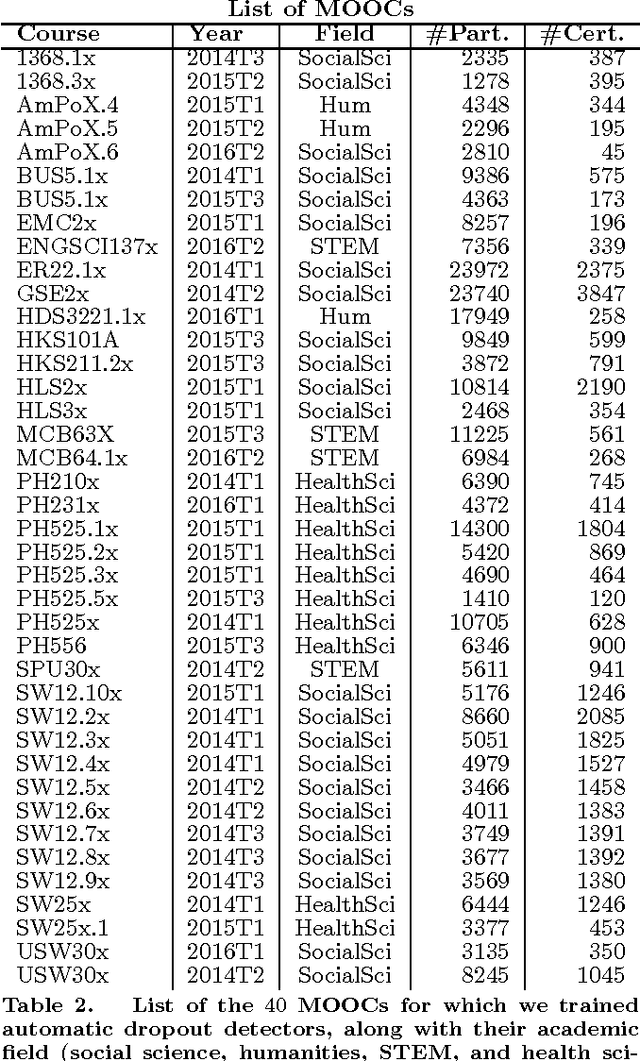
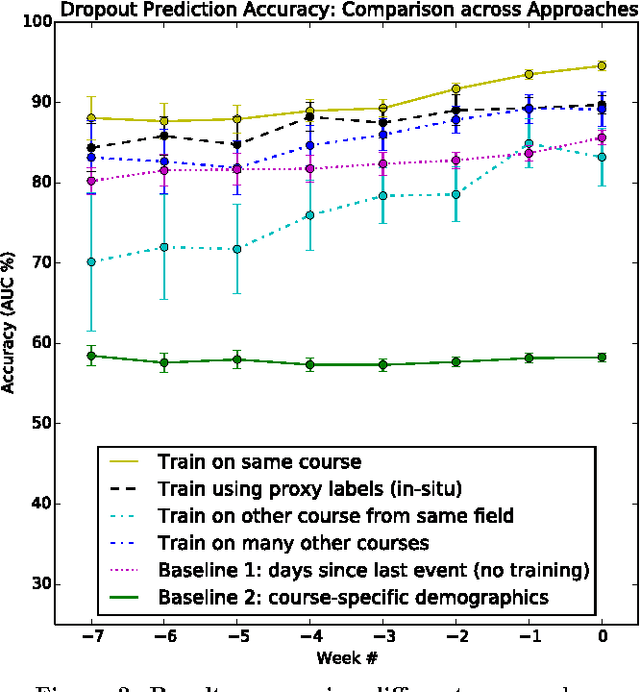
In order to obtain reliable accuracy estimates for automatic MOOC dropout predictors, it is important to train and test them in a manner consistent with how they will be used in practice. Yet most prior research on MOOC dropout prediction has measured test accuracy on the same course used for training the classifier, which can lead to overly optimistic accuracy estimates. In order to understand better how accuracy is affected by the training+testing regime, we compared the accuracy of a standard dropout prediction architecture (clickstream features + logistic regression) across 4 different training paradigms. Results suggest that (1) training and testing on the same course ("post-hoc") can overestimate accuracy by several percentage points; (2) dropout classifiers trained on proxy labels based on students' persistence are surprisingly competitive with post-hoc training (87.33% versus 90.20% AUC averaged over 8 weeks of 40 HarvardX MOOCs); and (3) classifier performance does not vary significantly with the academic discipline. Finally, we also research new dropout prediction architectures based on deep, fully-connected, feed-forward neural networks and find that (4) networks with as many as 5 hidden layers can statistically significantly increase test accuracy over that of logistic regression.