 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural collapse in the orthoplex regime
Mar 21, 2026When training a neural network for classification, the feature vectors of the training set are known to collapse to the vertices of a regular simplex, provided the dimension $d$ of the feature space and the number $n$ of classes satisfies $n\leq d+1$. This phenomenon is known as neural collapse. For other applications like language models, one instead takes $n\gg d$. Here, the neural collapse phenomenon still occurs, but with different emergent geometric figures. We characterize these geometric figures in the orthoplex regime where $d+2\leq n\leq 2d$. The techniques in our analysis primarily involve Radon's theorem and convexity.
On the clustering behavior of sliding windows
Mar 18, 2025Things can go spectacularly wrong when clustering timeseries data that has been preprocessed with a sliding window. We highlight three surprising failures that emerge depending on how the window size compares with the timeseries length. In addition to computational examples, we present theoretical explanations for each of these failure modes.
Sketch-and-solve approaches to k-means clustering by semidefinite programming
Nov 28, 2022We introduce a sketch-and-solve approach to speed up the Peng-Wei semidefinite relaxation of k-means clustering. When the data is appropriately separated we identify the k-means optimal clustering. Otherwise, our approach provides a high-confidence lower bound on the optimal k-means value. This lower bound is data-driven; it does not make any assumption on the data nor how it is generated. We provide code and an extensive set of numerical experiments where we use this approach to certify approximate optimality of clustering solutions obtained by k-means++.
Group-invariant max filtering
May 27, 2022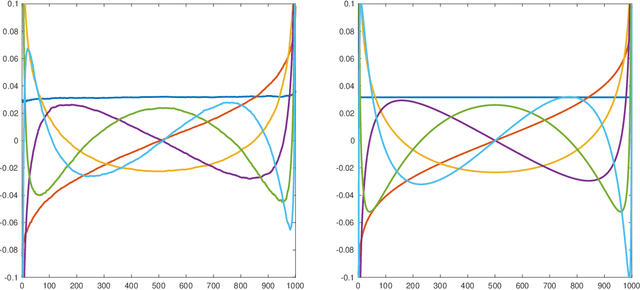
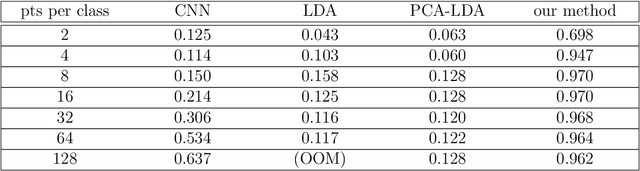
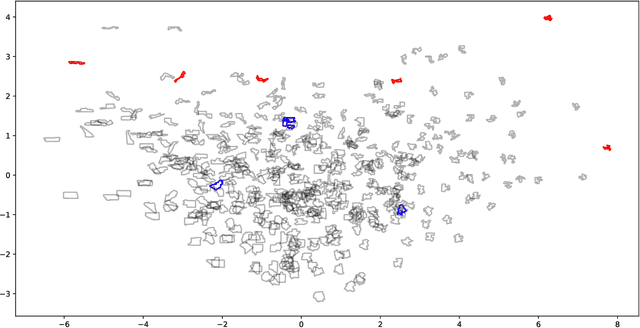
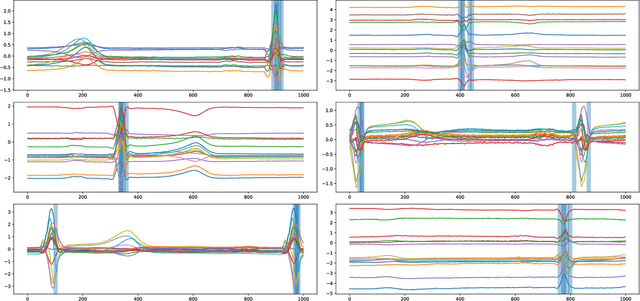
Given a real inner product space $V$ and a group $G$ of linear isometries, we construct a family of $G$-invariant real-valued functions on $V$ that we call max filters. In the case where $V=\mathbb{R}^d$ and $G$ is finite, a suitable max filter bank separates orbits, and is even bilipschitz in the quotient metric. In the case where $V=L^2(\mathbb{R}^d)$ and $G$ is the group of translation operators, a max filter exhibits stability to diffeomorphic distortion like that of the scattering transform introduced by Mallat. We establish that max filters are well suited for various classification tasks, both in theory and in practice.
Neural collapse with unconstrained features
Nov 23, 2020
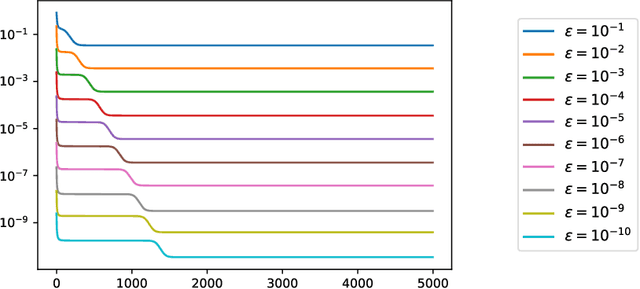
Neural collapse is an emergent phenomenon in deep learning that was recently discovered by Papyan, Han and Donoho. We propose a simple "unconstrained features model" in which neural collapse also emerges empirically. By studying this model, we provide some explanation for the emergence of neural collapse in terms of the landscape of empirical risk.
Lie PCA: Density estimation for symmetric manifolds
Sep 13, 2020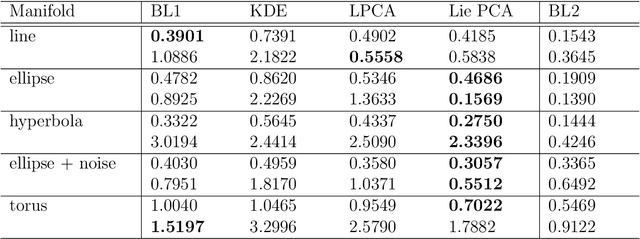

We introduce an extension to local principal component analysis for learning symmetric manifolds. In particular, we use a spectral method to approximate the Lie algebra corresponding to the symmetry group of the underlying manifold. We derive the sample complexity of our method for a variety of manifolds before applying it to various data sets for improved density estimation.
Sketching semidefinite programs for faster clustering
Aug 10, 2020
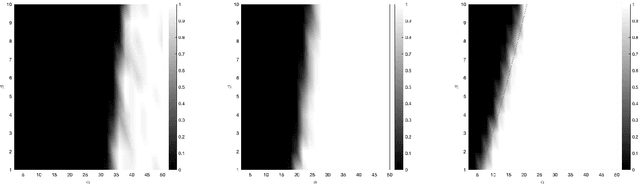
Many clustering problems enjoy solutions by semidefinite programming. Theoretical results in this vein frequently consider data with a planted clustering and a notion of signal strength such that the semidefinite program exactly recovers the planted clustering when the signal strength is sufficiently large. In practice, semidefinite programs are notoriously slow, and so speedups are welcome. In this paper, we show how to sketch a popular semidefinite relaxation of a graph clustering problem known as minimum bisection, and our analysis supports a meta-claim that the clustering task is less computationally burdensome when there is more signal.
SqueezeFit: Label-aware dimensionality reduction by semidefinite programming
Dec 06, 2018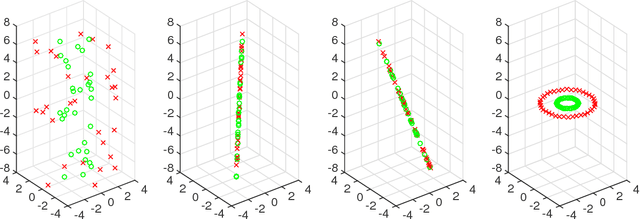


Given labeled points in a high-dimensional vector space, we seek a low-dimensional subspace such that projecting onto this subspace maintains some prescribed distance between points of differing labels. Intended applications include compressive classification. Taking inspiration from large margin nearest neighbor classification, this paper introduces a semidefinite relaxation of this problem. Unlike its predecessors, this relaxation is amenable to theoretical analysis, allowing us to provably recover a planted projection operator from the data.
SUNLayer: Stable denoising with generative networks
Mar 25, 2018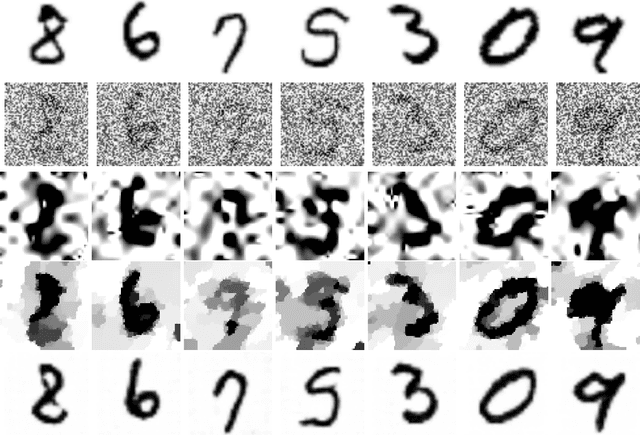
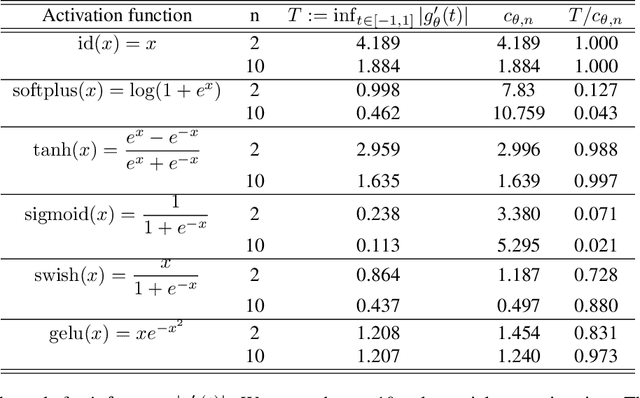
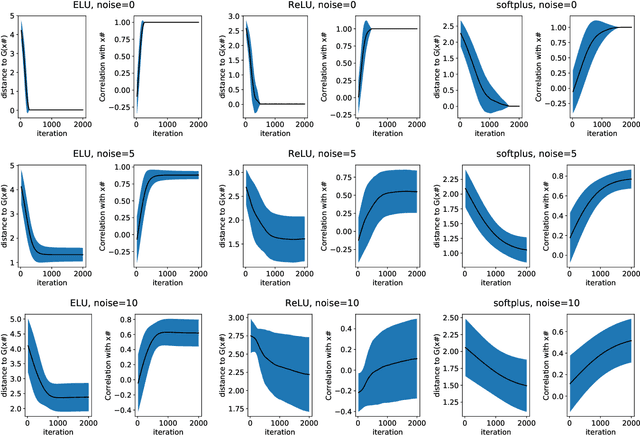
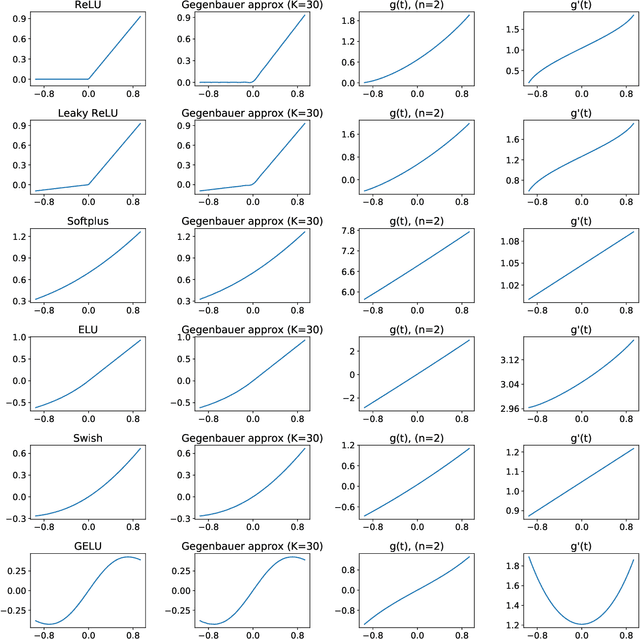
It has been experimentally established that deep neural networks can be used to produce good generative models for real world data. It has also been established that such generative models can be exploited to solve classical inverse problems like compressed sensing and super resolution. In this work we focus on the classical signal processing problem of image denoising. We propose a theoretical setting that uses spherical harmonics to identify what mathematical properties of the activation functions will allow signal denoising with local methods.
Monte Carlo approximation certificates for k-means clustering
Oct 03, 2017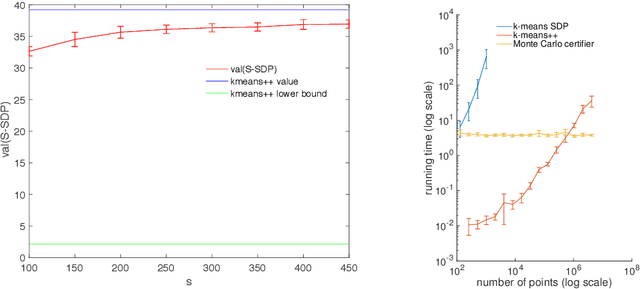
Efficient algorithms for $k$-means clustering frequently converge to suboptimal partitions, and given a partition, it is difficult to detect $k$-means optimality. In this paper, we develop an a posteriori certifier of approximate optimality for $k$-means clustering. The certifier is a sub-linear Monte Carlo algorithm based on Peng and Wei's semidefinite relaxation of $k$-means. In particular, solving the relaxation for small random samples of the dataset produces a high-confidence lower bound on the $k$-means objective, and being sub-linear, our algorithm is faster than $k$-means++ when the number of data points is large. We illustrate the performance of our algorithm with both numerical experiments and a performance guarantee: If the data points are drawn independently from any mixture of two Gaussians over $\mathbb{R}^m$ with identity covariance, then with probability $1-O(1/m)$, our $\operatorname{poly}(m)$-time algorithm produces a 3-approximation certificate with 99% confidence.