 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
OutFlip: Generating Out-of-Domain Samples for Unknown Intent Detection with Natural Language Attack
May 12, 2021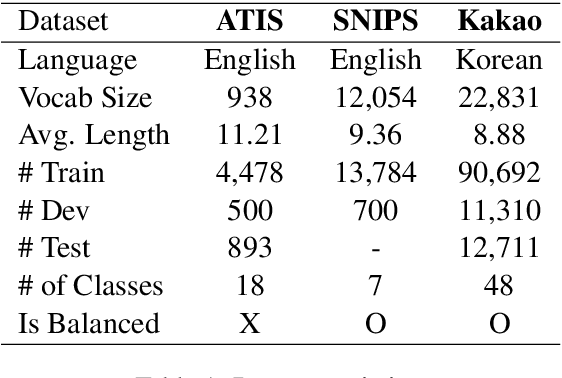
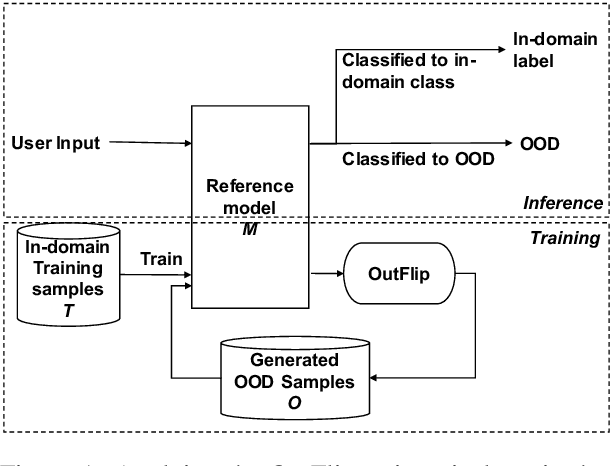
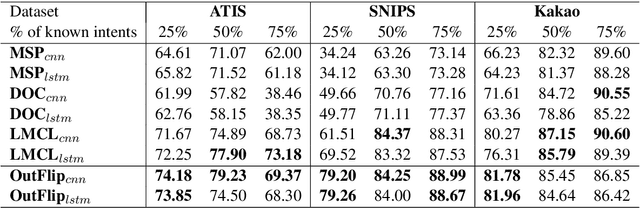
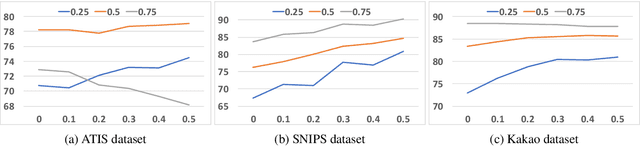
Out-of-domain (OOD) input detection is vital in a task-oriented dialogue system since the acceptance of unsupported inputs could lead to an incorrect response of the system. This paper proposes OutFlip, a method to generate out-of-domain samples using only in-domain training dataset automatically. A white-box natural language attack method HotFlip is revised to generate out-of-domain samples instead of adversarial examples. Our evaluation results showed that integrating OutFlip-generated out-of-domain samples into the training dataset could significantly improve an intent classification model's out-of-domain detection performance.
Integrated Eojeol Embedding for Erroneous Sentence Classification in Korean Chatbots
Apr 13, 2020
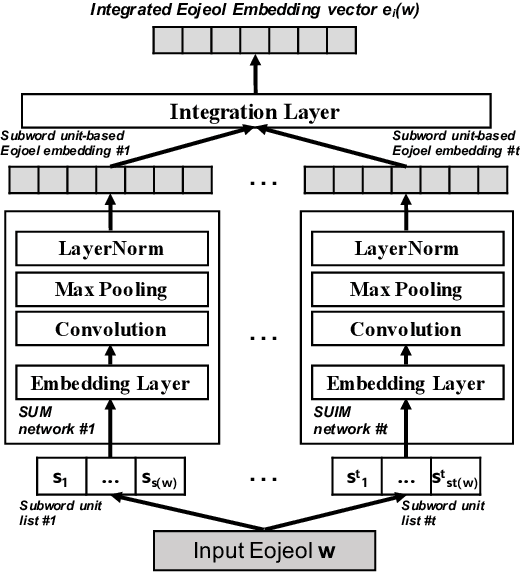
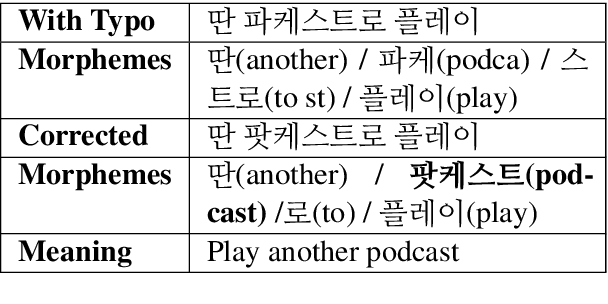
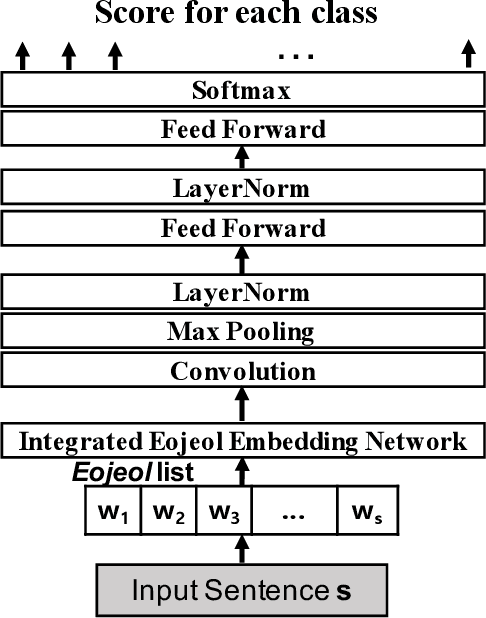
This paper attempts to analyze the Korean sentence classification system for a chatbot. Sentence classification is the task of classifying an input sentence based on predefined categories. However, spelling or space error contained in the input sentence causes problems in morphological analysis and tokenization. This paper proposes a novel approach of Integrated Eojeol (Korean syntactic word separated by space) Embedding to reduce the effect that poorly analyzed morphemes may make on sentence classification. It also proposes two noise insertion methods that further improve classification performance. Our evaluation results indicate that the proposed system classifies erroneous sentences more accurately than the baseline system by 17%p.0
RYANSQL: Recursively Applying Sketch-based Slot Fillings for Complex Text-to-SQL in Cross-Domain Databases
Apr 07, 2020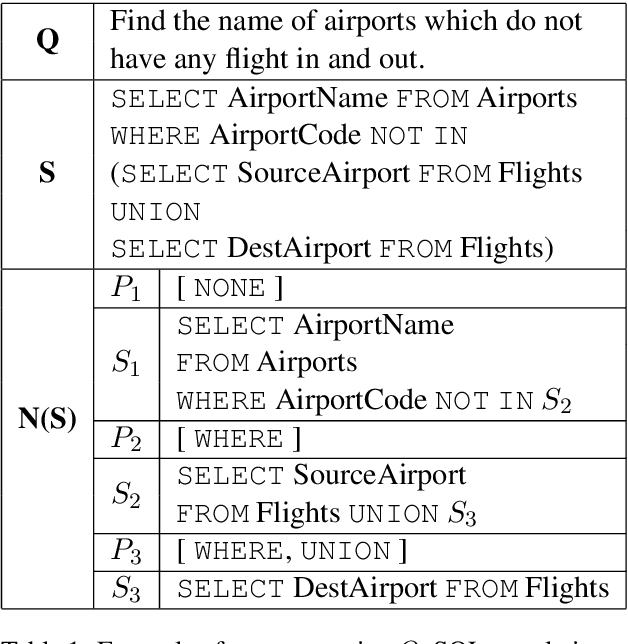


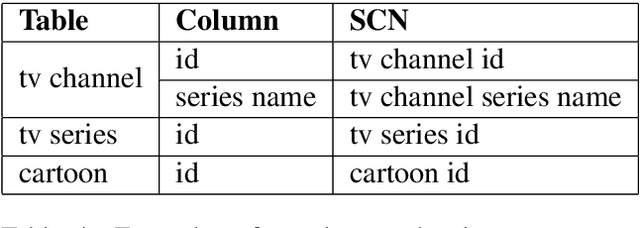
Text-to-SQL is the problem of converting a user question into an SQL query, when the question and database are given. In this paper, we present a neural network approach called RYANSQL (Recursively Yielding Annotation Network for SQL) to solve complex Text-to-SQL tasks for cross-domain databases. State-ment Position Code (SPC) is defined to trans-form a nested SQL query into a set of non-nested SELECT statements; a sketch-based slot filling approach is proposed to synthesize each SELECT statement for its corresponding SPC. Additionally, two input manipulation methods are presented to improve generation performance further. RYANSQL achieved 58.2% accuracy on the challenging Spider benchmark, which is a 3.2%p improvement over previous state-of-the-art approaches. At the time of writing, RYANSQL achieves the first position on the Spider leaderboard.