 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiM-Gestor: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2
Nov 23, 2024
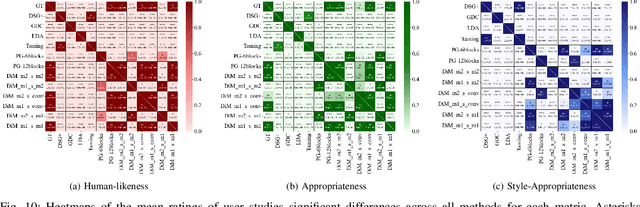
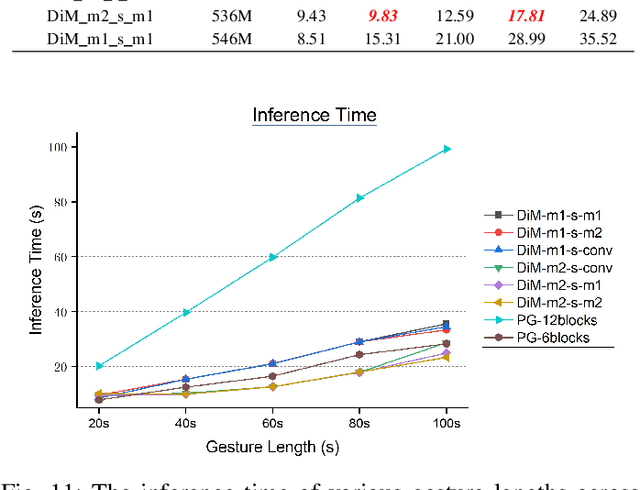
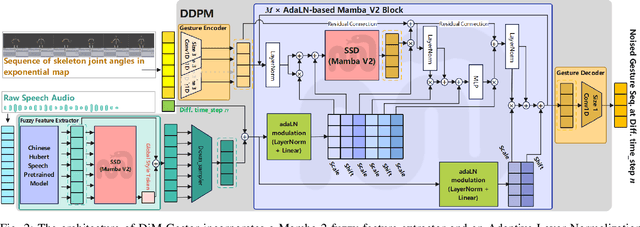
Speech-driven gesture generation using transformer-based generative models represents a rapidly advancing area within virtual human creation. However, existing models face significant challenges due to their quadratic time and space complexities, limiting scalability and efficiency. To address these limitations, we introduce DiM-Gestor, an innovative end-to-end generative model leveraging the Mamba-2 architecture. DiM-Gestor features a dual-component framework: (1) a fuzzy feature extractor and (2) a speech-to-gesture mapping module, both built on the Mamba-2. The fuzzy feature extractor, integrated with a Chinese Pre-trained Model and Mamba-2, autonomously extracts implicit, continuous speech features. These features are synthesized into a unified latent representation and then processed by the speech-to-gesture mapping module. This module employs an Adaptive Layer Normalization (AdaLN)-enhanced Mamba-2 mechanism to uniformly apply transformations across all sequence tokens. This enables precise modeling of the nuanced interplay between speech features and gesture dynamics. We utilize a diffusion model to train and infer diverse gesture outputs. Extensive subjective and objective evaluations conducted on the newly released Chinese Co-Speech Gestures dataset corroborate the efficacy of our proposed model. Compared with Transformer-based architecture, the assessments reveal that our approach delivers competitive results and significantly reduces memory usage, approximately 2.4 times, and enhances inference speeds by 2 to 4 times. Additionally, we released the CCG dataset, a Chinese Co-Speech Gestures dataset, comprising 15.97 hours (six styles across five scenarios) of 3D full-body skeleton gesture motion performed by professional Chinese TV broadcasters.
Mixed Reality Depth Contour Occlusion Using Binocular Similarity Matching and Three-dimensional Contour Optimisation
Mar 04, 2022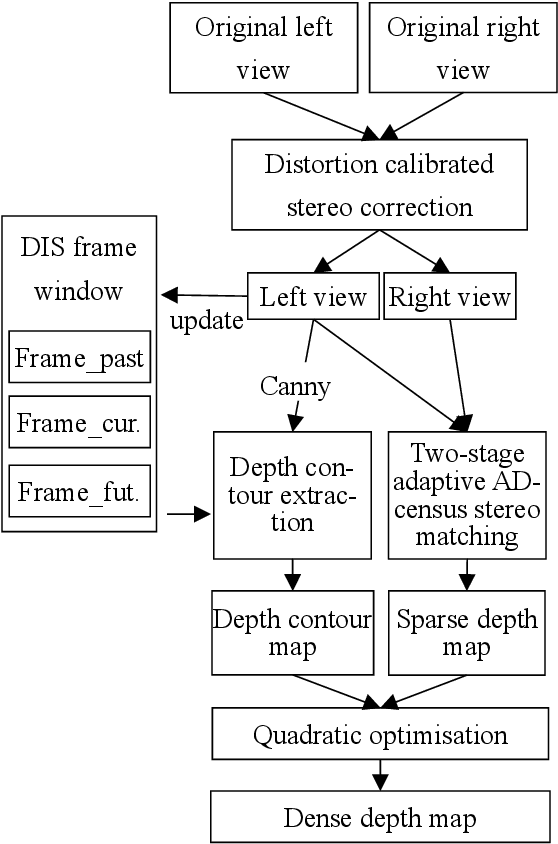
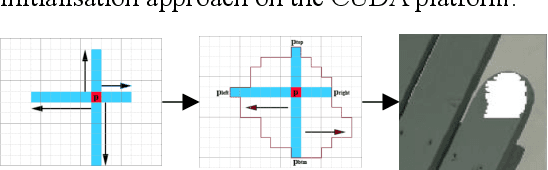
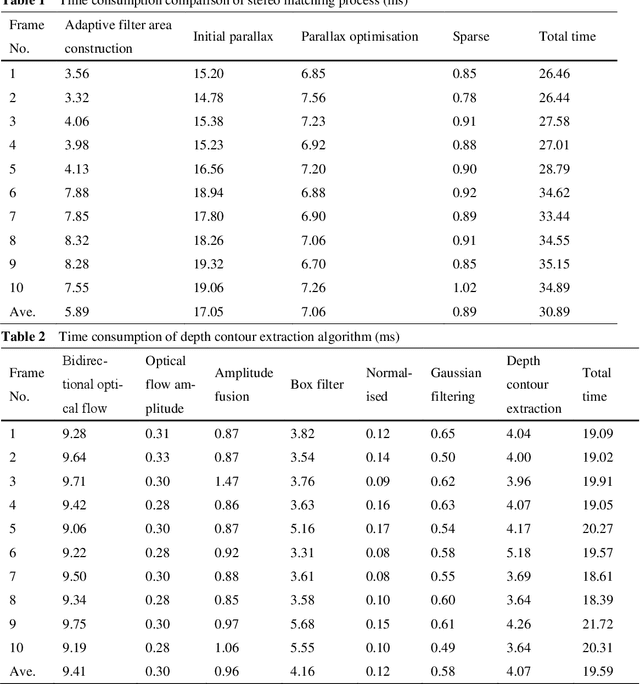

Mixed reality applications often require virtual objects that are partly occluded by real objects. However, previous research and commercial products have limitations in terms of performance and efficiency. To address these challenges, we propose a novel depth contour occlusion (DCO) algorithm. The proposed method is based on the sensitivity of contour occlusion and a binocular stereoscopic vision device. In this method, a depth contour map is combined with a sparse depth map obtained from a two-stage adaptive filter area stereo matching algorithm and the depth contour information of the objects extracted by a digital image stabilisation optical flow method. We also propose a quadratic optimisation model with three constraints to generate an accurate dense map of the depth contour for high-quality real-virtual occlusion. The whole process is accelerated by GPU. To evaluate the effectiveness of the algorithm, we demonstrate a time con-sumption statistical analysis for each stage of the DCO algorithm execution. To verify the relia-bility of the real-virtual occlusion effect, we conduct an experimental analysis on single-sided, enclosed, and complex occlusions; subsequently, we compare it with the occlusion method without quadratic optimisation. With our GPU implementation for real-time DCO, the evaluation indicates that applying the presented DCO algorithm can enhance the real-time performance and the visual quality of real-virtual occlusion.