 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLivestock Monitoring with Transformer
Nov 02, 2021

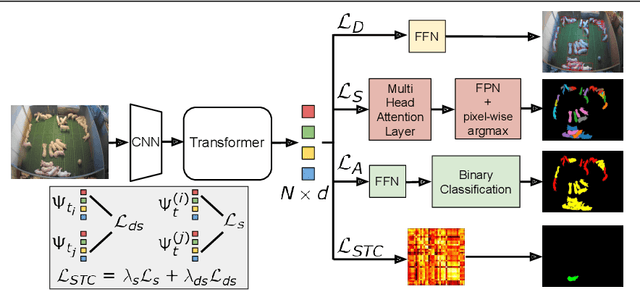

Tracking the behaviour of livestock enables early detection and thus prevention of contagious diseases in modern animal farms. Apart from economic gains, this would reduce the amount of antibiotics used in livestock farming which otherwise enters the human diet exasperating the epidemic of antibiotic resistance - a leading cause of death. We could use standard video cameras, available in most modern farms, to monitor livestock. However, most computer vision algorithms perform poorly on this task, primarily because, (i) animals bred in farms look identical, lacking any obvious spatial signature, (ii) none of the existing trackers are robust for long duration, and (iii) real-world conditions such as changing illumination, frequent occlusion, varying camera angles, and sizes of the animals make it hard for models to generalize. Given these challenges, we develop an end-to-end behaviour monitoring system for group-housed pigs to perform simultaneous instance level segmentation, tracking, action recognition and re-identification (STAR) tasks. We present starformer, the first end-to-end multiple-object livestock monitoring framework that learns instance-level embeddings for grouped pigs through the use of transformer architecture. For benchmarking, we present Pigtrace, a carefully curated dataset comprising video sequences with instance level bounding box, segmentation, tracking and activity classification of pigs in real indoor farming environment. Using simultaneous optimization on STAR tasks we show that starformer outperforms popular baseline models trained for individual tasks.
Adaptive Neural Message Passing for Inductive Learning on Hypergraphs
Sep 22, 2021


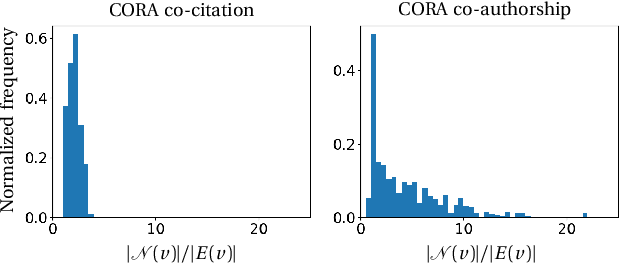
Graphs are the most ubiquitous data structures for representing relational datasets and performing inferences in them. They model, however, only pairwise relations between nodes and are not designed for encoding the higher-order relations. This drawback is mitigated by hypergraphs, in which an edge can connect an arbitrary number of nodes. Most hypergraph learning approaches convert the hypergraph structure to that of a graph and then deploy existing geometric deep learning methods. This transformation leads to information loss, and sub-optimal exploitation of the hypergraph's expressive power. We present HyperMSG, a novel hypergraph learning framework that uses a modular two-level neural message passing strategy to accurately and efficiently propagate information within each hyperedge and across the hyperedges. HyperMSG adapts to the data and task by learning an attention weight associated with each node's degree centrality. Such a mechanism quantifies both local and global importance of a node, capturing the structural properties of a hypergraph. HyperMSG is inductive, allowing inference on previously unseen nodes. Further, it is robust and outperforms state-of-the-art hypergraph learning methods on a wide range of tasks and datasets. Finally, we demonstrate the effectiveness of HyperMSG in learning multimodal relations through detailed experimentation on a challenging multimedia dataset.
Improving Solar Cell Metallization Designs using Convolutional Neural Networks
Apr 08, 2021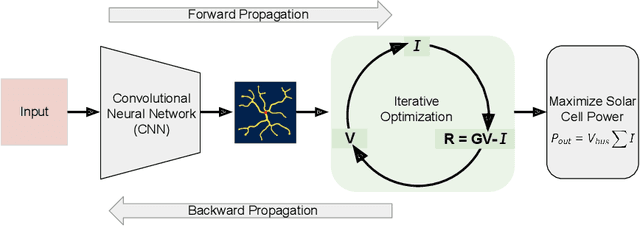
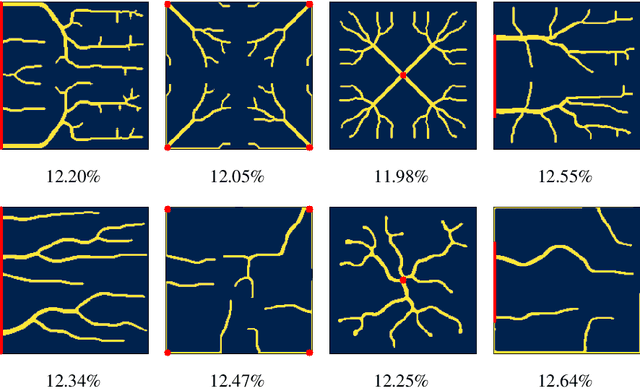
Optimizing the design of solar cell metallizations is one of the ways to improve the performance of solar cells. Recently, it has been shown that Topology Optimization (TO) can be used to design complex metallization patterns for solar cells that lead to improved performance. TO generates unconventional design patterns that cannot be obtained with the traditional shape optimization methods. In this paper, we show that this design process can be improved further using a deep learning inspired strategy. We present SolarNet, a CNN-based reparameterization scheme that can be used to obtain improved metallization designs. SolarNet modifies the optimization domain such that rather than optimizing the electrode material distribution directly, the weights of a CNN model are optimized. The design generated by CNN is then evaluated using the physics equations, which in turn generates gradients for backpropagation. SolarNet is trained end-to-end involving backpropagation through the solar cell model as well as the CNN pipeline. Through application on solar cells of different shapes as well as different busbar geometries, we demonstrate that SolarNet improves the performance of solar cells compared to the traditional TO approach.
Rotation Equivariant Siamese Networks for Tracking
Dec 24, 2020
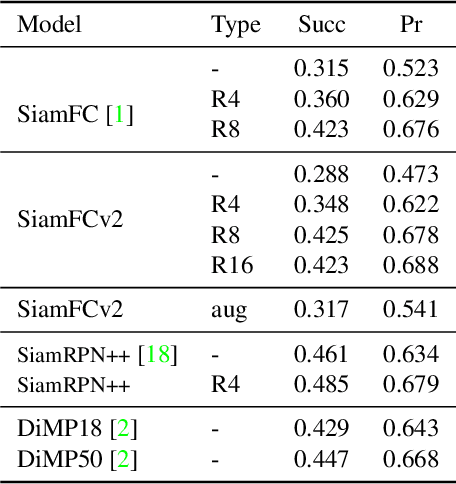

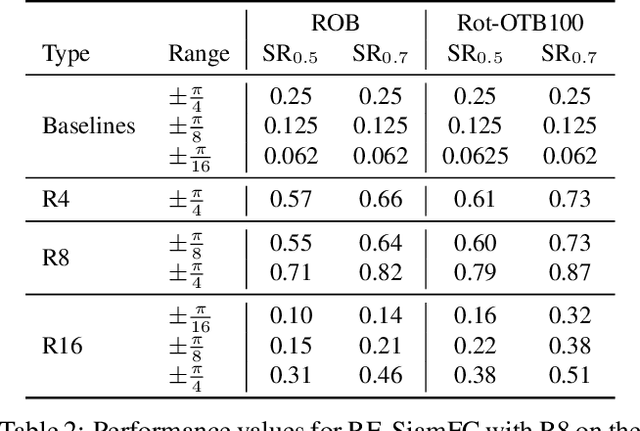
Rotation is among the long prevailing, yet still unresolved, hard challenges encountered in visual object tracking. The existing deep learning-based tracking algorithms use regular CNNs that are inherently translation equivariant, but not designed to tackle rotations. In this paper, we first demonstrate that in the presence of rotation instances in videos, the performance of existing trackers is severely affected. To circumvent the adverse effect of rotations, we present rotation-equivariant Siamese networks (RE-SiamNets), built through the use of group-equivariant convolutional layers comprising steerable filters. SiamNets allow estimating the change in orientation of the object in an unsupervised manner, thereby facilitating its use in relative 2D pose estimation as well. We further show that this change in orientation can be used to impose an additional motion constraint in Siamese tracking through imposing restriction on the change in orientation between two consecutive frames. For benchmarking, we present Rotation Tracking Benchmark (RTB), a dataset comprising a set of videos with rotation instances. Through experiments on two popular Siamese architectures, we show that RE-SiamNets handle the problem of rotation very well and out-perform their regular counterparts. Further, RE-SiamNets can accurately estimate the relative change in pose of the target in an unsupervised fashion, namely the in-plane rotation the target has sustained with respect to the reference frame.
HyperSAGE: Generalizing Inductive Representation Learning on Hypergraphs
Oct 09, 2020



Graphs are the most ubiquitous form of structured data representation used in machine learning. They model, however, only pairwise relations between nodes and are not designed for encoding the higher-order relations found in many real-world datasets. To model such complex relations, hypergraphs have proven to be a natural representation. Learning the node representations in a hypergraph is more complex than in a graph as it involves information propagation at two levels: within every hyperedge and across the hyperedges. Most current approaches first transform a hypergraph structure to a graph for use in existing geometric deep learning algorithms. This transformation leads to information loss, and sub-optimal exploitation of the hypergraph's expressive power. We present HyperSAGE, a novel hypergraph learning framework that uses a two-level neural message passing strategy to accurately and efficiently propagate information through hypergraphs. The flexible design of HyperSAGE facilitates different ways of aggregating neighborhood information. Unlike the majority of related work which is transductive, our approach, inspired by the popular GraphSAGE method, is inductive. Thus, it can also be used on previously unseen nodes, facilitating deployment in problems such as evolving or partially observed hypergraphs. Through extensive experimentation, we show that HyperSAGE outperforms state-of-the-art hypergraph learning methods on representative benchmark datasets. We also demonstrate that the higher expressive power of HyperSAGE makes it more stable in learning node representations as compared to the alternatives.
Hard Occlusions in Visual Object Tracking
Sep 10, 2020
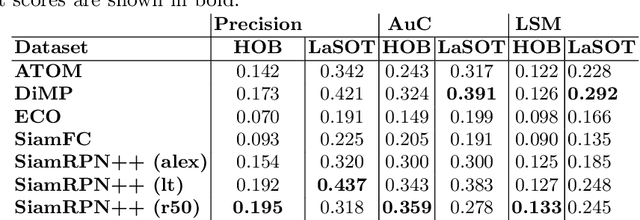

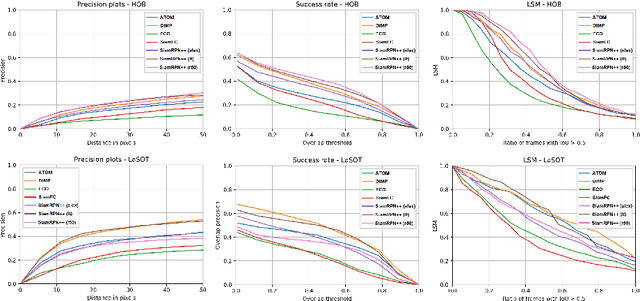
Visual object tracking is among the hardest problems in computer vision, as trackers have to deal with many challenging circumstances such as illumination changes, fast motion, occlusion, among others. A tracker is assessed to be good or not based on its performance on the recent tracking datasets, e.g., VOT2019, and LaSOT. We argue that while the recent datasets contain large sets of annotated videos that to some extent provide a large bandwidth for training data, the hard scenarios such as occlusion and in-plane rotation are still underrepresented. For trackers to be brought closer to the real-world scenarios and deployed in safety-critical devices, even the rarest hard scenarios must be properly addressed. In this paper, we particularly focus on hard occlusion cases and benchmark the performance of recent state-of-the-art trackers (SOTA) on them. We created a small-scale dataset containing different categories within hard occlusions, on which the selected trackers are evaluated. Results show that hard occlusions remain a very challenging problem for SOTA trackers. Furthermore, it is observed that tracker performance varies wildly between different categories of hard occlusions, where a top-performing tracker on one category performs significantly worse on a different category. The varying nature of tracker performance based on specific categories suggests that the common tracker rankings using averaged single performance scores are not adequate to gauge tracker performance in real-world scenarios.
Generating Annotated High-Fidelity Images Containing Multiple Coherent Objects
Jun 24, 2020
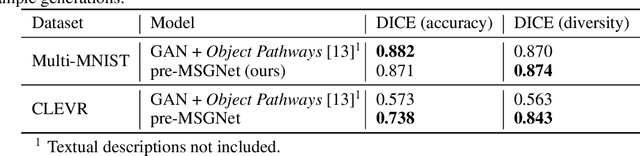
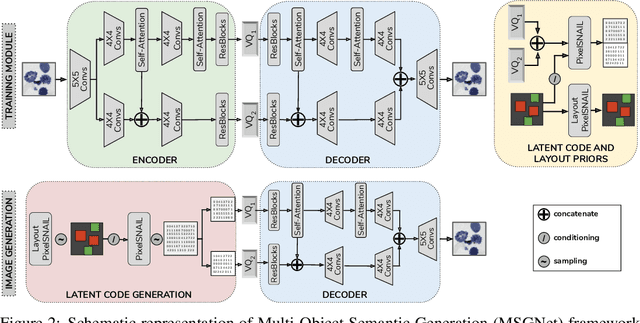

Recent developments related to generative models have made it possible to generate diverse high-fidelity images. In particular, layout-to-image generation models have gained significant attention due to their capability to generate realistic complex images containing distinct objects. These models are generally conditioned on either semantic layouts or textual descriptions. However, unlike natural images, providing auxiliary information can be extremely hard in domains such as biomedical imaging and remote sensing. In this work, we propose a multi-object generation framework that can synthesize images with multiple objects without explicitly requiring their contextual information during the generation process. Based on a vector-quantized variational autoencoder (VQ-VAE) backbone, our model learns to preserve spatial coherency within an image as well as semantic coherency between the objects and the background through two powerful autoregressive priors: PixelSNAIL and LayoutPixelSNAIL. While the PixelSNAIL learns the distribution of the latent encodings of the VQ-VAE, the LayoutPixelSNAIL is used to specifically learn the semantic distribution of the objects. An implicit advantage of our approach is that the generated samples are accompanied by object-level annotations. We demonstrate how coherency and fidelity are preserved with our method through experiments on the Multi-MNIST and CLEVR datasets; thereby outperforming state-of-the-art multi-object generative methods. The efficacy of our approach is demonstrated through application on medical imaging datasets, where we show that augmenting the training set with generated samples using our approach improves the performance of existing models.
HyperLearn: A Distributed Approach for Representation Learning in Datasets With Many Modalities
Sep 19, 2019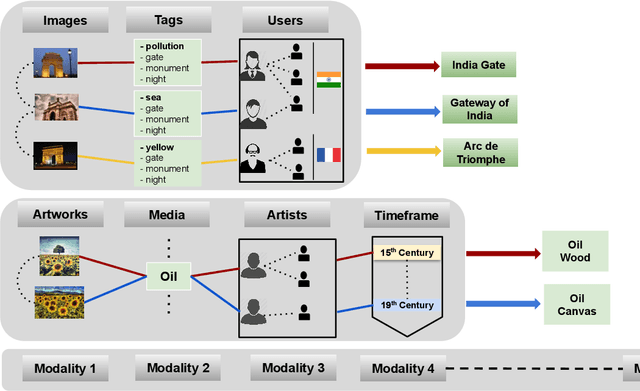



Multimodal datasets contain an enormous amount of relational information, which grows exponentially with the introduction of new modalities. Learning representations in such a scenario is inherently complex due to the presence of multiple heterogeneous information channels. These channels can encode both (a) inter-relations between the items of different modalities and (b) intra-relations between the items of the same modality. Encoding multimedia items into a continuous low-dimensional semantic space such that both types of relations are captured and preserved is extremely challenging, especially if the goal is a unified end-to-end learning framework. The two key challenges that need to be addressed are: 1) the framework must be able to merge complex intra and inter relations without losing any valuable information and 2) the learning model should be invariant to the addition of new and potentially very different modalities. In this paper, we propose a flexible framework which can scale to data streams from many modalities. To that end we introduce a hypergraph-based model for data representation and deploy Graph Convolutional Networks to fuse relational information within and across modalities. Our approach provides an efficient solution for distributing otherwise extremely computationally expensive or even unfeasible training processes across multiple-GPUs, without any sacrifices in accuracy. Moreover, adding new modalities to our model requires only an additional GPU unit keeping the computational time unchanged, which brings representation learning to truly multimodal datasets. We demonstrate the feasibility of our approach in the experiments on multimedia datasets featuring second, third and fourth order relations.