 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Annotated High-Fidelity Images Containing Multiple Coherent Objects
Paper and Code

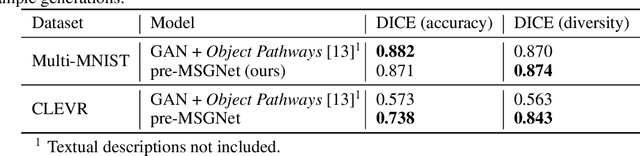
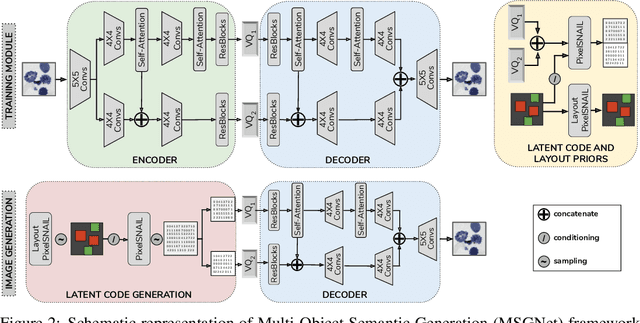

Recent developments related to generative models have made it possible to generate diverse high-fidelity images. In particular, layout-to-image generation models have gained significant attention due to their capability to generate realistic complex images containing distinct objects. These models are generally conditioned on either semantic layouts or textual descriptions. However, unlike natural images, providing auxiliary information can be extremely hard in domains such as biomedical imaging and remote sensing. In this work, we propose a multi-object generation framework that can synthesize images with multiple objects without explicitly requiring their contextual information during the generation process. Based on a vector-quantized variational autoencoder (VQ-VAE) backbone, our model learns to preserve spatial coherency within an image as well as semantic coherency between the objects and the background through two powerful autoregressive priors: PixelSNAIL and LayoutPixelSNAIL. While the PixelSNAIL learns the distribution of the latent encodings of the VQ-VAE, the LayoutPixelSNAIL is used to specifically learn the semantic distribution of the objects. An implicit advantage of our approach is that the generated samples are accompanied by object-level annotations. We demonstrate how coherency and fidelity are preserved with our method through experiments on the Multi-MNIST and CLEVR datasets; thereby outperforming state-of-the-art multi-object generative methods. The efficacy of our approach is demonstrated through application on medical imaging datasets, where we show that augmenting the training set with generated samples using our approach improves the performance of existing models.