 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSci-VLA: Agentic VLA Inference Plugin for Long-Horizon Tasks in Scientific Experiments
Feb 10, 2026Robotic laboratories play a critical role in autonomous scientific discovery by enabling scalable, continuous experimental execution. Recent vision-language-action (VLA) models offer a promising foundation for robotic laboratories. However, scientific experiments typically involve long-horizon tasks composed of multiple atomic tasks, posing a fundamental challenge to existing VLA models. While VLA models fine-tuned for scientific tasks can reliably execute atomic experimental actions seen during training, they often fail to perform composite tasks formed by reordering and composing these known atomic actions. This limitation arises from a distributional mismatch between training-time atomic tasks and inference-time composite tasks, which prevents VLA models from executing necessary transitional operations between atomic tasks. To address this challenge, we propose an Agentic VLA Inference Plugin for Long-Horizon Tasks in Scientific Experiments. It introduces an LLM-based agentic inference mechanism that intervenes when executing sequential manipulation tasks. By performing explicit transition inference and generating transitional robotic action code, the proposed plugin guides VLA models through missing transitional steps, enabling reliable execution of composite scientific workflows without any additional training. This inference-only intervention makes our method computationally efficient, data-efficient, and well-suited for open-ended and long-horizon robotic laboratory tasks. We build 3D assets of scientific instruments and common scientific operating scenes within an existing simulation environment. In these scenes, we have verified that our method increases the average success rate per atomic task by 42\% during inference. Furthermore, we show that our method can be easily transferred from the simulation to real scientific laboratories.
Partial-Label Regression
Jun 15, 2023
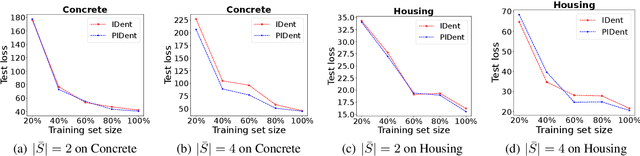
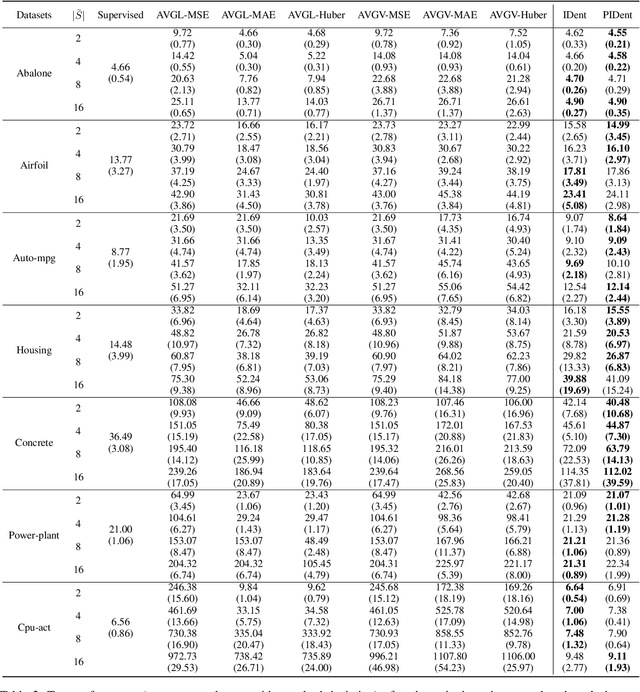
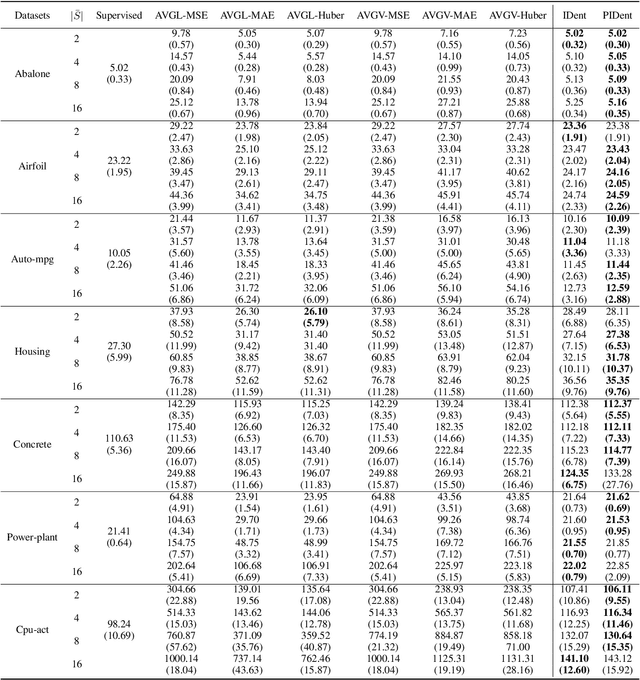
Partial-label learning is a popular weakly supervised learning setting that allows each training example to be annotated with a set of candidate labels. Previous studies on partial-label learning only focused on the classification setting where candidate labels are all discrete, which cannot handle continuous labels with real values. In this paper, we provide the first attempt to investigate partial-label regression, where each training example is annotated with a set of real-valued candidate labels. To solve this problem, we first propose a simple baseline method that takes the average loss incurred by candidate labels as the predictive loss. The drawback of this method lies in that the loss incurred by the true label may be overwhelmed by other false labels. To overcome this drawback, we propose an identification method that takes the least loss incurred by candidate labels as the predictive loss. We further improve it by proposing a progressive identification method to differentiate candidate labels using progressively updated weights for incurred losses. We prove that the latter two methods are model-consistent and provide convergence analyses. Our proposed methods are theoretically grounded and can be compatible with any models, optimizers, and losses. Experiments validate the effectiveness of our proposed methods.
Learning from Noisy Labels via Dynamic Loss Thresholding
Apr 01, 2021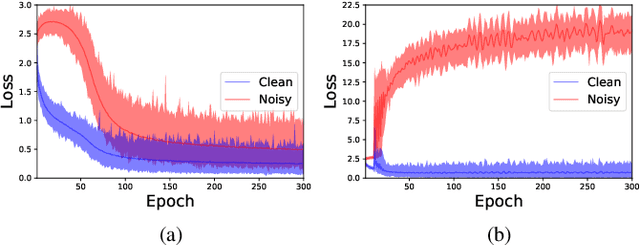
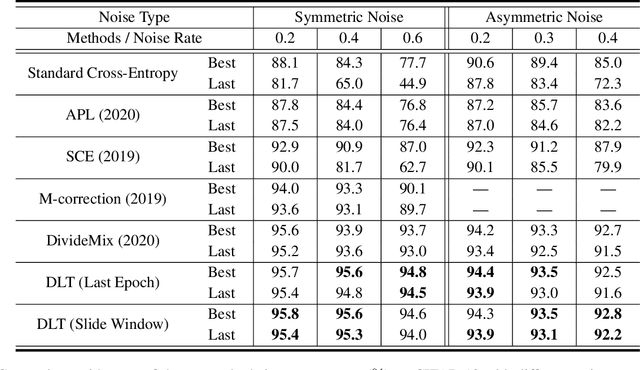
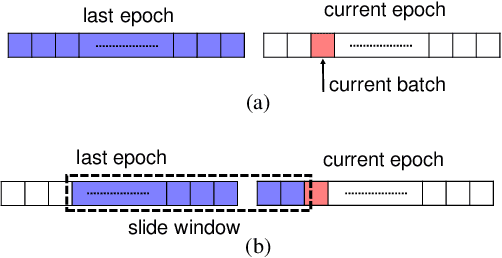
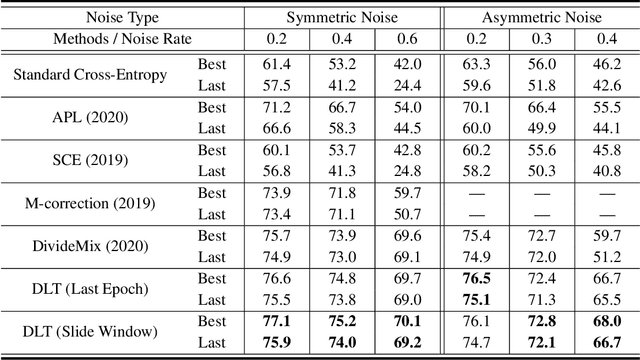
Numerous researches have proved that deep neural networks (DNNs) can fit everything in the end even given data with noisy labels, and result in poor generalization performance. However, recent studies suggest that DNNs tend to gradually memorize the data, moving from correct data to mislabeled data. Inspired by this finding, we propose a novel method named Dynamic Loss Thresholding (DLT). During the training process, DLT records the loss value of each sample and calculates dynamic loss thresholds. Specifically, DLT compares the loss value of each sample with the current loss threshold. Samples with smaller losses can be considered as clean samples with higher probability and vice versa. Then, DLT discards the potentially corrupted labels and further leverages supervised learning techniques. Experiments on CIFAR-10/100 and Clothing1M demonstrate substantial improvements over recent state-of-the-art methods. In addition, we investigate two real-world problems for the first time. Firstly, we propose a novel approach to estimate the noise rates of datasets based on the loss difference between the early and late training stages of DNNs. Secondly, we explore the effect of hard samples (which are difficult to be distinguished) on the process of learning from noisy labels.