 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable discovery of interpretable subgroups via calibration in causal studies
Sep 29, 2020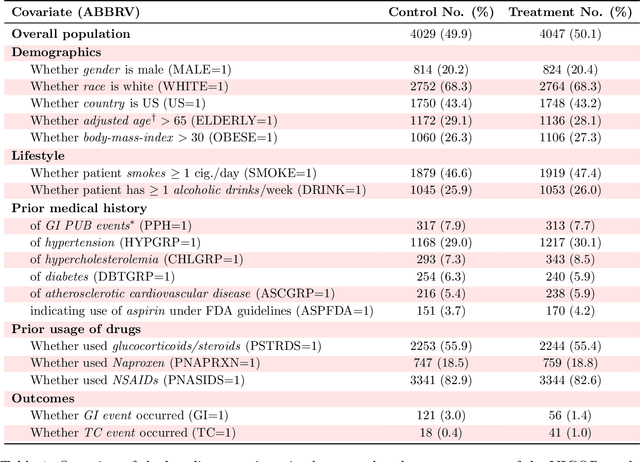
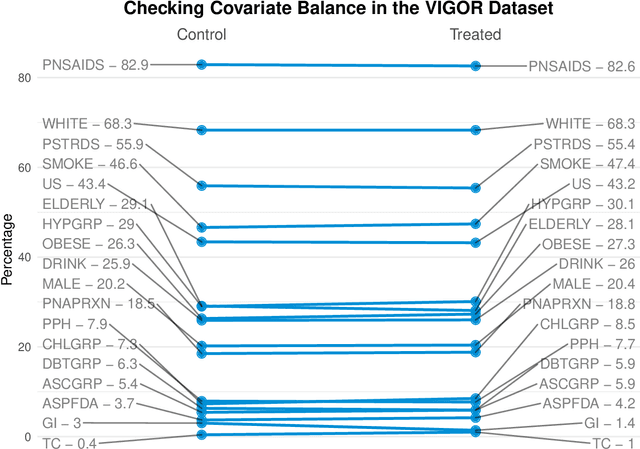
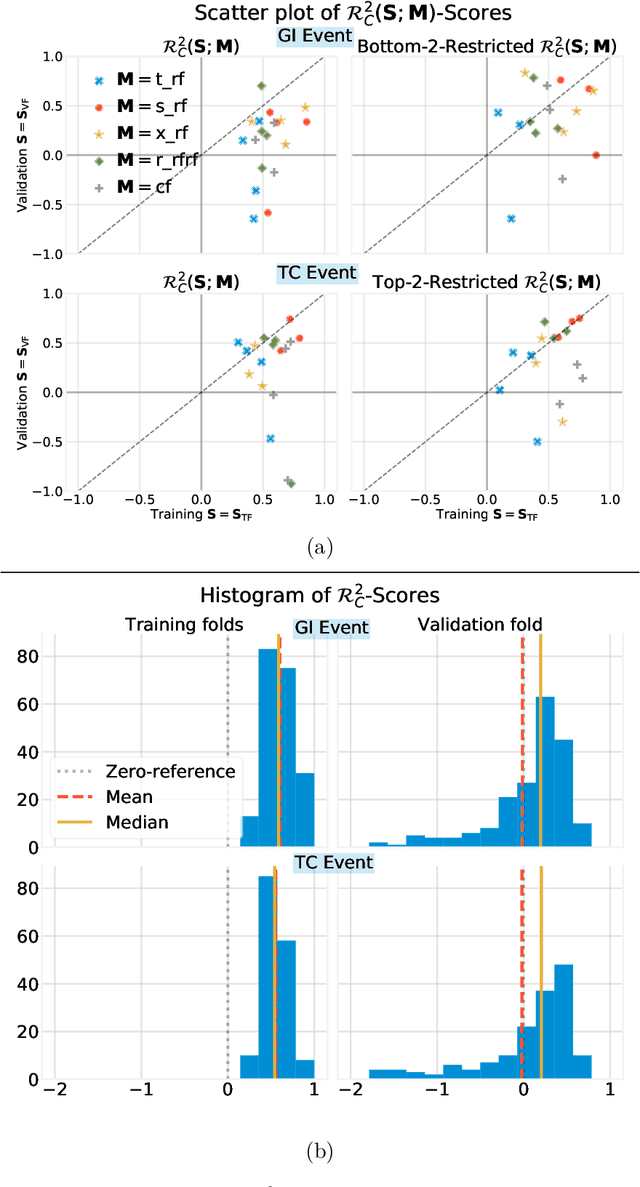
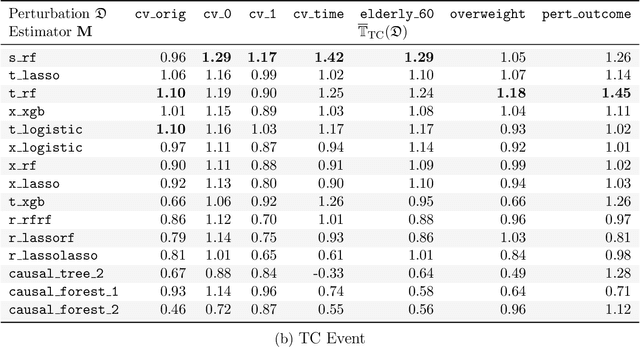
Building on Yu and Kumbier's PCS framework and for randomized experiments, we introduce a novel methodology for Stable Discovery of Interpretable Subgroups via Calibration (StaDISC), with large heterogeneous treatment effects. StaDISC was developed during our re-analysis of the 1999-2000 VIGOR study, an 8076 patient randomized controlled trial (RCT), that compared the risk of adverse events from a then newly approved drug, Rofecoxib (Vioxx), to that from an older drug Naproxen. Vioxx was found to, on average and in comparison to Naproxen, reduce the risk of gastrointestinal (GI) events but increase the risk of thrombotic cardiovascular (CVT) events. Applying StaDISC, we fit 18 popular conditional average treatment effect (CATE) estimators for both outcomes and use calibration to demonstrate their poor global performance. However, they are locally well-calibrated and stable, enabling the identification of patient groups with larger than (estimated) average treatment effects. In fact, StaDISC discovers three clinically interpretable subgroups each for the GI outcome (totaling 29.4% of the study size) and the CVT outcome (totaling 11.0%). Complementary analyses of the found subgroups using the 2001-2004 APPROVe study, a separate independently conducted RCT with 2587 patients, provides further supporting evidence for the promise of StaDISC.
Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model
Nov 05, 2015

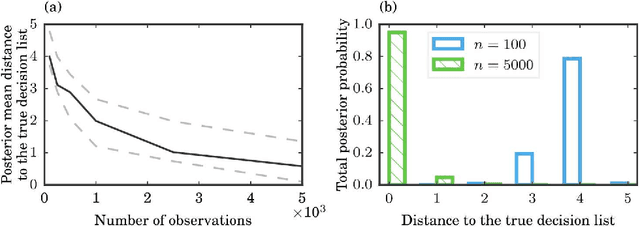
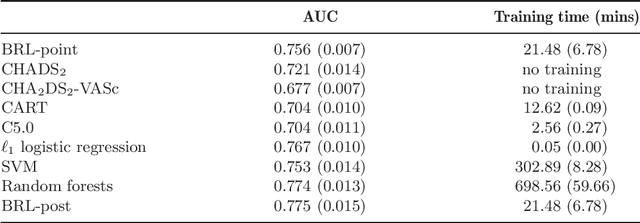
We aim to produce predictive models that are not only accurate, but are also interpretable to human experts. Our models are decision lists, which consist of a series of if...then... statements (e.g., if high blood pressure, then stroke) that discretize a high-dimensional, multivariate feature space into a series of simple, readily interpretable decision statements. We introduce a generative model called Bayesian Rule Lists that yields a posterior distribution over possible decision lists. It employs a novel prior structure to encourage sparsity. Our experiments show that Bayesian Rule Lists has predictive accuracy on par with the current top algorithms for prediction in machine learning. Our method is motivated by recent developments in personalized medicine, and can be used to produce highly accurate and interpretable medical scoring systems. We demonstrate this by producing an alternative to the CHADS$_2$ score, actively used in clinical practice for estimating the risk of stroke in patients that have atrial fibrillation. Our model is as interpretable as CHADS$_2$, but more accurate.
* Published at http://dx.doi.org/10.1214/15-AOAS848 in the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Probabilistic Temporal Reasoning with Endogenous Change
Feb 20, 2013
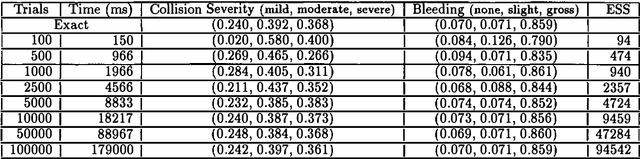


This paper presents a probabilistic model for reasoning about the state of a system as it changes over time, both due to exogenous and endogenous influences. Our target domain is a class of medical prediction problems that are neither so urgent as to preclude careful diagnosis nor progress so slowly as to allow arbitrary testing and treatment options. In these domains there is typically enough time to gather information about the patient's state and consider alternative diagnoses and treatments, but the temporal interaction between the timing of tests, treatments, and the course of the disease must also be considered. Our approach is to elicit a qualitative structural model of the patient from a human expert---the model identifies important attributes, the way in which exogenous changes affect attribute values, and the way in which the patient's condition changes endogenously. We then elicit probabilistic information to capture the expert's uncertainty about the effects of tests and treatments and the nature and timing of endogenous state changes. This paper describes the model in the context of a problem in treating vehicle accident trauma, and suggests a method for solving the model based on the technique of sequential imputation. A complementary goal of this work is to understand and synthesize a disparate collection of research efforts all using the name ?probabilistic temporal reasoning.? This paper analyzes related work and points out essential differences between our proposed model and other approaches in the literature.
An Alternative Markov Property for Chain Graphs
Feb 13, 2013Graphical Markov models use graphs, either undirected, directed, or mixed, to represent possible dependences among statistical variables. Applications of undirected graphs (UDGs) include models for spatial dependence and image analysis, while acyclic directed graphs (ADGs), which are especially convenient for statistical analysis, arise in such fields as genetics and psychometrics and as models for expert systems and Bayesian belief networks. Lauritzen, Wermuth and Frydenberg (LWF) introduced a Markov property for chain graphs, which are mixed graphs that can be used to represent simultaneously both causal and associative dependencies and which include both UDGs and ADGs as special cases. In this paper an alternative Markov property (AMP) for chain graphs is introduced, which in some ways is a more direct extension of the ADG Markov property than is the LWF property for chain graph.