 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming volcanic monitoring: A dataset and benchmark for onboard volcano activity detection
Oct 27, 2025Natural disasters, such as volcanic eruptions, pose significant challenges to daily life and incur considerable global economic losses. The emergence of next-generation small-satellites, capable of constellation-based operations, offers unparalleled opportunities for near-real-time monitoring and onboard processing of such events. However, a major bottleneck remains the lack of extensive annotated datasets capturing volcanic activity, which hinders the development of robust detection systems. This paper introduces a novel dataset explicitly designed for volcanic activity and eruption detection, encompassing diverse volcanoes worldwide. The dataset provides binary annotations to identify volcanic anomalies or non-anomalies, covering phenomena such as temperature anomalies, eruptions, and volcanic ash emissions. These annotations offer a foundational resource for developing and evaluating detection models, addressing a critical gap in volcanic monitoring research. Additionally, we present comprehensive benchmarks using state-of-the-art models to establish baselines for future studies. Furthermore, we explore the potential for deploying these models onboard next-generation satellites. Using the Intel Movidius Myriad X VPU as a testbed, we demonstrate the feasibility of volcanic activity detection directly onboard. This capability significantly reduces latency and enhances response times, paving the way for advanced early warning systems. This paves the way for innovative solutions in volcanic disaster management, encouraging further exploration and refinement of onboard monitoring technologies.
Attention Driven Fusion for Multi-Modal Emotion Recognition
Oct 10, 2020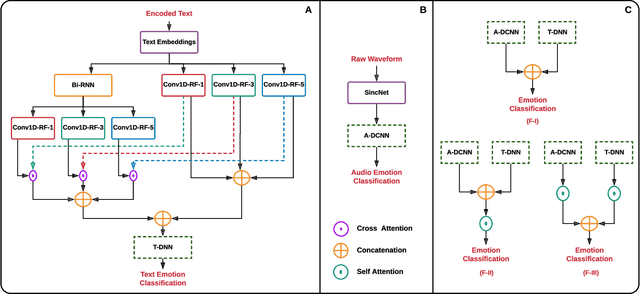

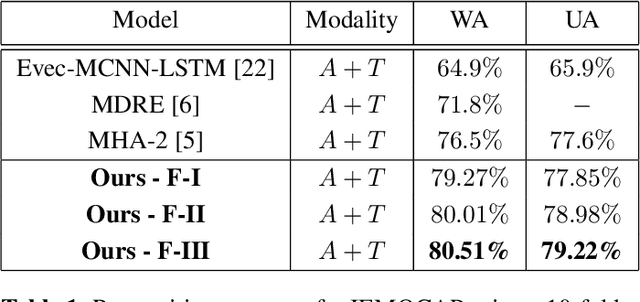
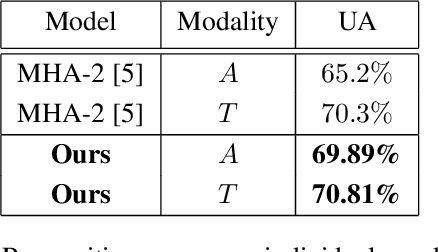
Deep learning has emerged as a powerful alternative to hand-crafted methods for emotion recognition on combined acoustic and text modalities. Baseline systems model emotion information in text and acoustic modes independently using Deep Convolutional Neural Networks (DCNN) and Recurrent Neural Networks (RNN), followed by applying attention, fusion, and classification. In this paper, we present a deep learning-based approach to exploit and fuse text and acoustic data for emotion classification. We utilize a SincNet layer, based on parameterized sinc functions with band-pass filters, to extract acoustic features from raw audio followed by a DCNN. This approach learns filter banks tuned for emotion recognition and provides more effective features compared to directly applying convolutions over the raw speech signal. For text processing, we use two branches (a DCNN and a Bi-direction RNN followed by a DCNN) in parallel where cross attention is introduced to infer the N-gram level correlations on hidden representations received from the Bi-RNN. Following existing state-of-the-art, we evaluate the performance of the proposed system on the IEMOCAP dataset. Experimental results indicate that the proposed system outperforms existing methods, achieving 3.5% improvement in weighted accuracy.
Memory Based Attentive Fusion
Jul 16, 2020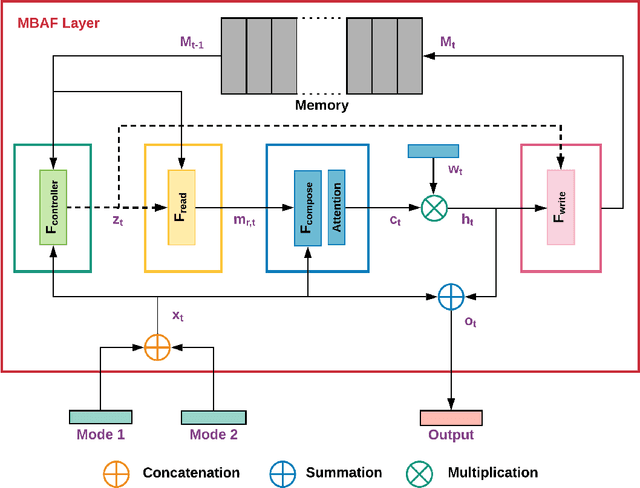
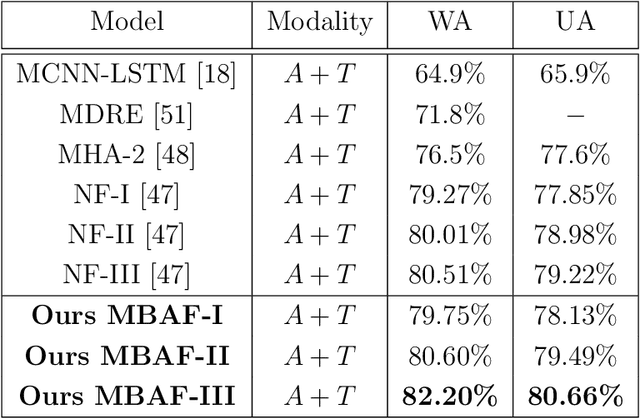
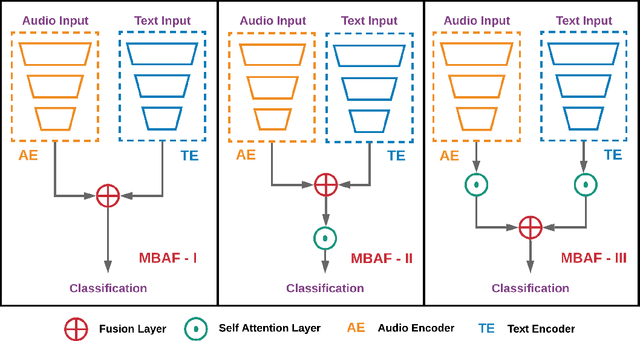
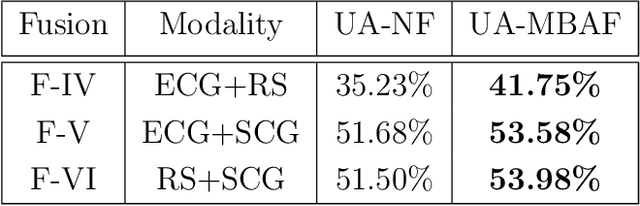
The use of multi-modal data for deep machine learning has shown promise when compared to uni-modal approaches, where fusion of multi-modal features has resulted in improved performance. However, most state-of-the-art methods use naive fusion which processes feature streams from a given time-step and ignores long-term dependencies within the data during fusion. In this paper, we present a novel Memory Based Attentive Fusion (MBAF) layer, which fuses modes by incorporating both the current features and long-term dependencies in the data, thus allowing the model to understand the relative importance of modes over time. We define an explicit memory block within the fusion layer which stores features containing long-term dependencies of the fused data. The inputs to our layer are fused through attentive composition and transformation, and the transformed features are combined with the input to generate the fused layer output. Following existing state-of-the-art methods, we have evaluated the performance and the generalizability of the proposed approach on the IEMOCAP and PhysioNet-CMEBS datasets with different modalities. In our experiments, we replace the naive fusion layer in benchmark networks with our proposed layer to enable a fair comparison. Experimental results indicate that MBAF layer can generalise across different modalities and networks to enhance the fusion and improve performance.
Temporarily-Aware Context Modelling using Generative Adversarial Networks for Speech Activity Detection
Apr 02, 2020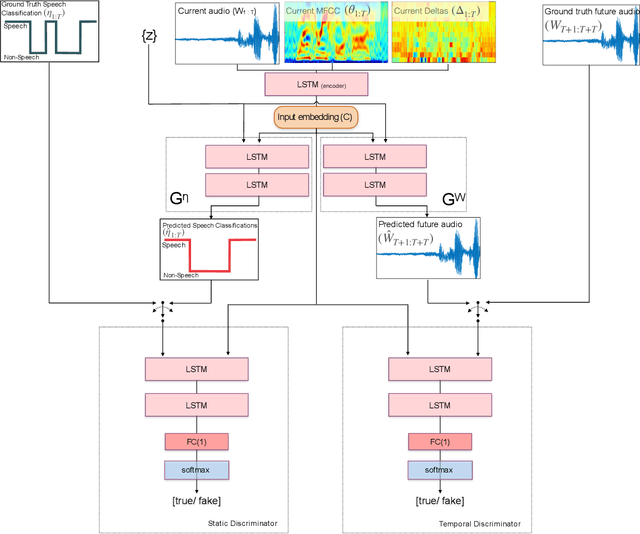
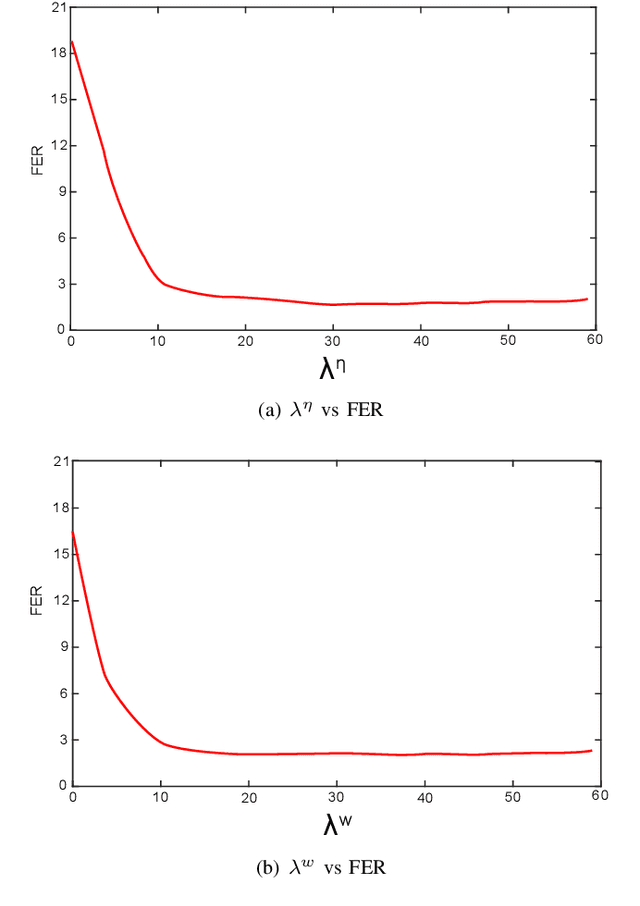
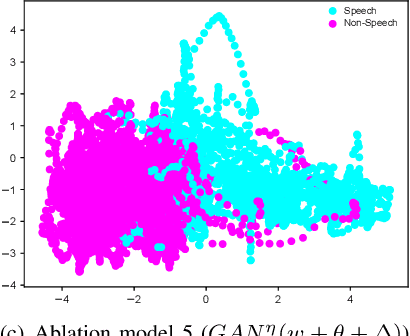

This paper presents a novel framework for Speech Activity Detection (SAD). Inspired by the recent success of multi-task learning approaches in the speech processing domain, we propose a novel joint learning framework for SAD. We utilise generative adversarial networks to automatically learn a loss function for joint prediction of the frame-wise speech/ non-speech classifications together with the next audio segment. In order to exploit the temporal relationships within the input signal, we propose a temporal discriminator which aims to ensure that the predicted signal is temporally consistent. We evaluate the proposed framework on multiple public benchmarks, including NIST OpenSAT' 17, AMI Meeting and HAVIC, where we demonstrate its capability to outperform state-of-the-art SAD approaches. Furthermore, our cross-database evaluations demonstrate the robustness of the proposed approach across different languages, accents, and acoustic environments.