 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Driven Fusion for Multi-Modal Emotion Recognition
Paper and Code
Oct 10, 2020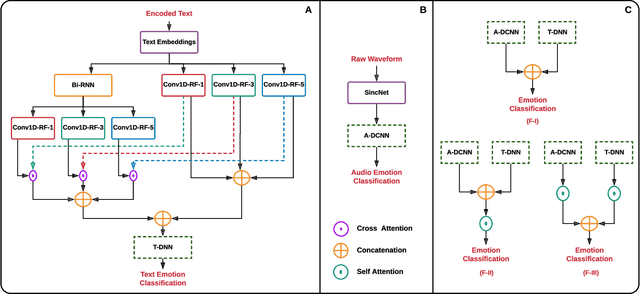

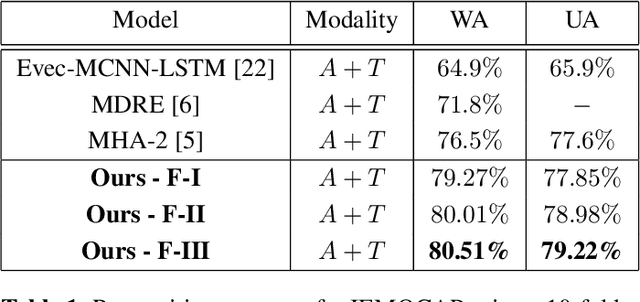
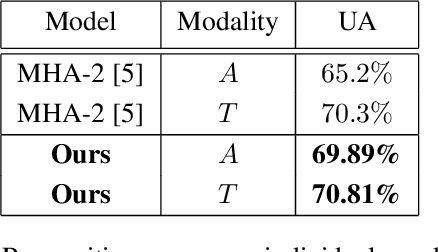
Deep learning has emerged as a powerful alternative to hand-crafted methods for emotion recognition on combined acoustic and text modalities. Baseline systems model emotion information in text and acoustic modes independently using Deep Convolutional Neural Networks (DCNN) and Recurrent Neural Networks (RNN), followed by applying attention, fusion, and classification. In this paper, we present a deep learning-based approach to exploit and fuse text and acoustic data for emotion classification. We utilize a SincNet layer, based on parameterized sinc functions with band-pass filters, to extract acoustic features from raw audio followed by a DCNN. This approach learns filter banks tuned for emotion recognition and provides more effective features compared to directly applying convolutions over the raw speech signal. For text processing, we use two branches (a DCNN and a Bi-direction RNN followed by a DCNN) in parallel where cross attention is introduced to infer the N-gram level correlations on hidden representations received from the Bi-RNN. Following existing state-of-the-art, we evaluate the performance of the proposed system on the IEMOCAP dataset. Experimental results indicate that the proposed system outperforms existing methods, achieving 3.5% improvement in weighted accuracy.