 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Based Attentive Fusion
Paper and Code
Jul 16, 2020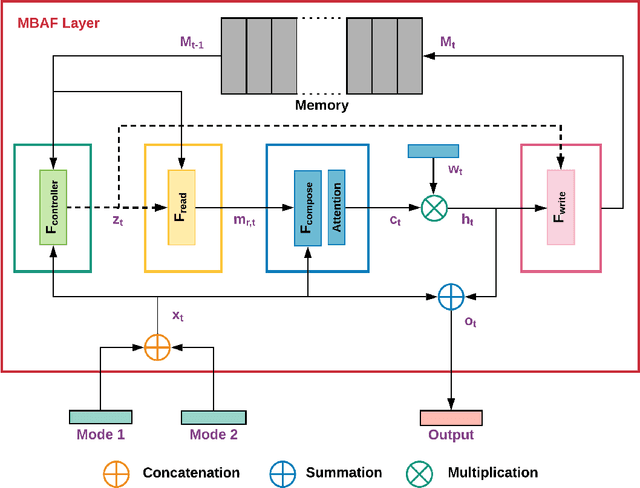
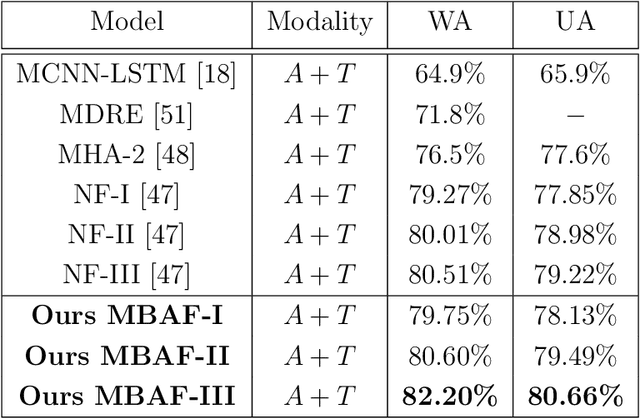
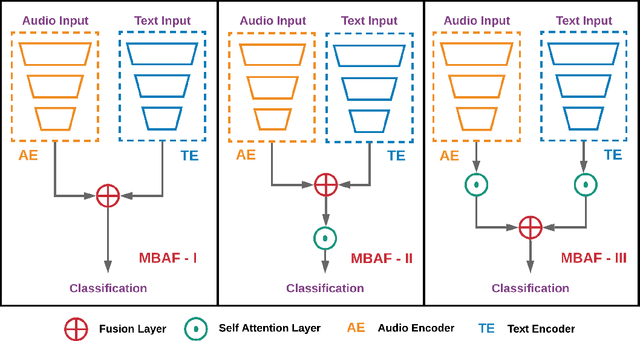
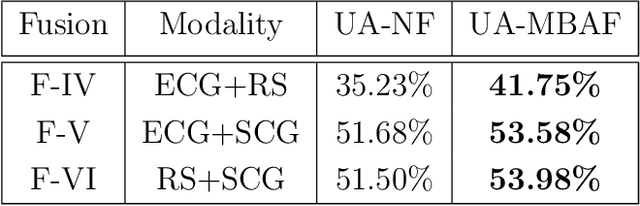
The use of multi-modal data for deep machine learning has shown promise when compared to uni-modal approaches, where fusion of multi-modal features has resulted in improved performance. However, most state-of-the-art methods use naive fusion which processes feature streams from a given time-step and ignores long-term dependencies within the data during fusion. In this paper, we present a novel Memory Based Attentive Fusion (MBAF) layer, which fuses modes by incorporating both the current features and long-term dependencies in the data, thus allowing the model to understand the relative importance of modes over time. We define an explicit memory block within the fusion layer which stores features containing long-term dependencies of the fused data. The inputs to our layer are fused through attentive composition and transformation, and the transformed features are combined with the input to generate the fused layer output. Following existing state-of-the-art methods, we have evaluated the performance and the generalizability of the proposed approach on the IEMOCAP and PhysioNet-CMEBS datasets with different modalities. In our experiments, we replace the naive fusion layer in benchmark networks with our proposed layer to enable a fair comparison. Experimental results indicate that MBAF layer can generalise across different modalities and networks to enhance the fusion and improve performance.