 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate or Fate? RLV$^\varepsilon$R: Reinforcement Learning with Verifiable Noisy Rewards
Jan 07, 2026Reinforcement learning with verifiable rewards (RLVR) is a simple but powerful paradigm for training LLMs: sample a completion, verify it, and update. In practice, however, the verifier is almost never clean--unit tests probe only limited corner cases; human and synthetic labels are imperfect; and LLM judges (e.g., RLAIF) are noisy and can be exploited--and this problem worsens on harder domains (especially coding) where tests are sparse and increasingly model-generated. We ask a pragmatic question: does the verification noise merely slow down the learning (rate), or can it flip the outcome (fate)? To address this, we develop an analytically tractable multi-armed bandit view of RLVR dynamics, instantiated with GRPO and validated in controlled experiments. Modeling false positives and false negatives and grouping completions into recurring reasoning modes yields a replicator-style (natural-selection) flow on the probability simplex. The dynamics decouples into within-correct-mode competition and a one-dimensional evolution for the mass on incorrect modes, whose drift is determined solely by Youden's index J=TPR-FPR. This yields a sharp phase transition: when J>0, the incorrect mass is driven toward extinction (learning); when J=0, the process is neutral; and when J<0, incorrect modes amplify until they dominate (anti-learning and collapse). In the learning regime J>0, noise primarily rescales convergence time ("rate, not fate"). Experiments on verifiable programming tasks under synthetic noise reproduce the predicted J=0 boundary. Beyond noise, the framework offers a general lens for analyzing RLVR stability, convergence, and algorithmic interventions.
Model-Free $μ$-Synthesis: A Nonsmooth Optimization Perspective
Feb 18, 2024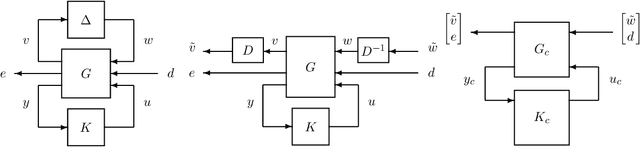

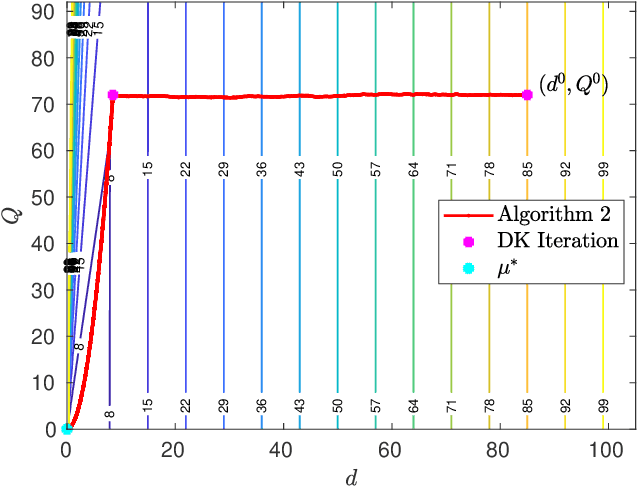
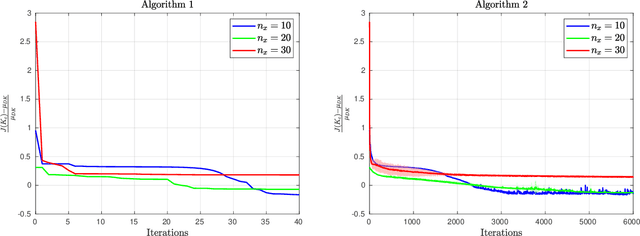
In this paper, we revisit model-free policy search on an important robust control benchmark, namely $\mu$-synthesis. In the general output-feedback setting, there do not exist convex formulations for this problem, and hence global optimality guarantees are not expected. Apkarian (2011) presented a nonconvex nonsmooth policy optimization approach for this problem, and achieved state-of-the-art design results via using subgradient-based policy search algorithms which generate update directions in a model-based manner. Despite the lack of convexity and global optimality guarantees, these subgradient-based policy search methods have led to impressive numerical results in practice. Built upon such a policy optimization persepctive, our paper extends these subgradient-based search methods to a model-free setting. Specifically, we examine the effectiveness of two model-free policy optimization strategies: the model-free non-derivative sampling method and the zeroth-order policy search with uniform smoothing. We performed an extensive numerical study to demonstrate that both methods consistently replicate the design outcomes achieved by their model-based counterparts. Additionally, we provide some theoretical justifications showing that convergence guarantees to stationary points can be established for our model-free $\mu$-synthesis under some assumptions related to the coerciveness of the cost function. Overall, our results demonstrate that derivative-free policy optimization offers a competitive and viable approach for solving general output-feedback $\mu$-synthesis problems in the model-free setting.
Revisiting PGD Attacks for Stability Analysis of Large-Scale Nonlinear Systems and Perception-Based Control
Jan 03, 2022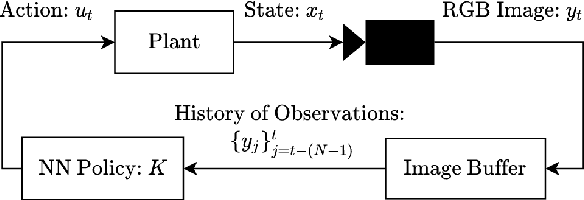
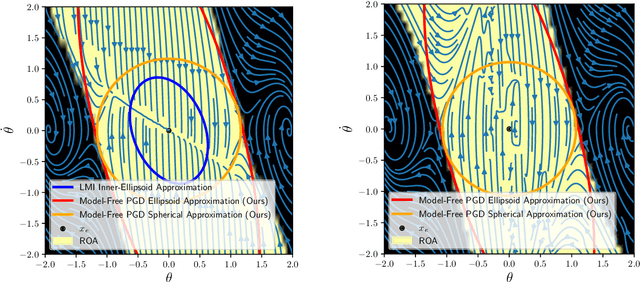
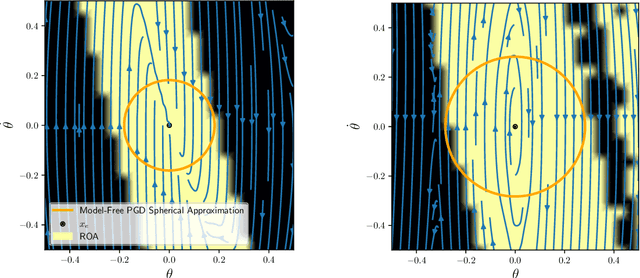
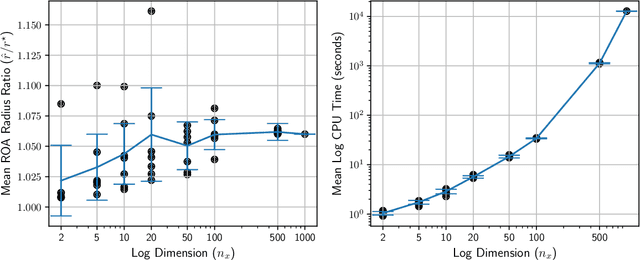
Many existing region-of-attraction (ROA) analysis tools find difficulty in addressing feedback systems with large-scale neural network (NN) policies and/or high-dimensional sensing modalities such as cameras. In this paper, we tailor the projected gradient descent (PGD) attack method developed in the adversarial learning community as a general-purpose ROA analysis tool for large-scale nonlinear systems and end-to-end perception-based control. We show that the ROA analysis can be approximated as a constrained maximization problem whose goal is to find the worst-case initial condition which shifts the terminal state the most. Then we present two PGD-based iterative methods which can be used to solve the resultant constrained maximization problem. Our analysis is not based on Lyapunov theory, and hence requires minimum information of the problem structures. In the model-based setting, we show that the PGD updates can be efficiently performed using back-propagation. In the model-free setting (which is more relevant to ROA analysis of perception-based control), we propose a finite-difference PGD estimate which is general and only requires a black-box simulator for generating the trajectories of the closed-loop system given any initial state. We demonstrate the scalability and generality of our analysis tool on several numerical examples with large-scale NN policies and high-dimensional image observations. We believe that our proposed analysis serves as a meaningful initial step toward further understanding of closed-loop stability of large-scale nonlinear systems and perception-based control.
Model-Free $μ$ Synthesis via Adversarial Reinforcement Learning
Nov 30, 2021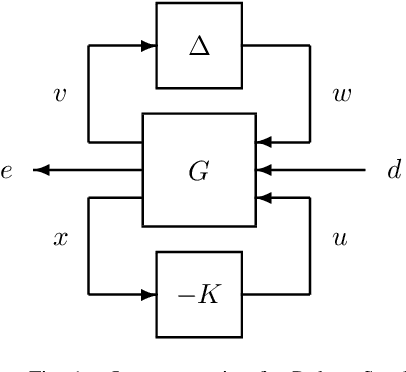
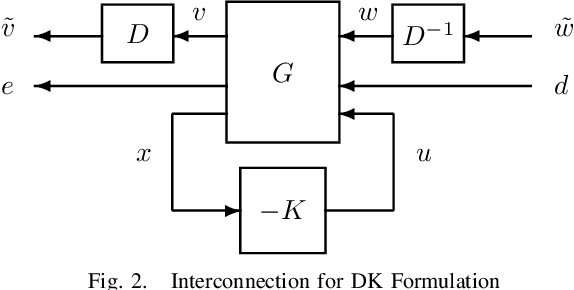
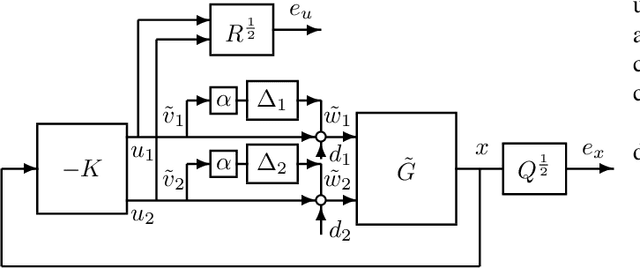
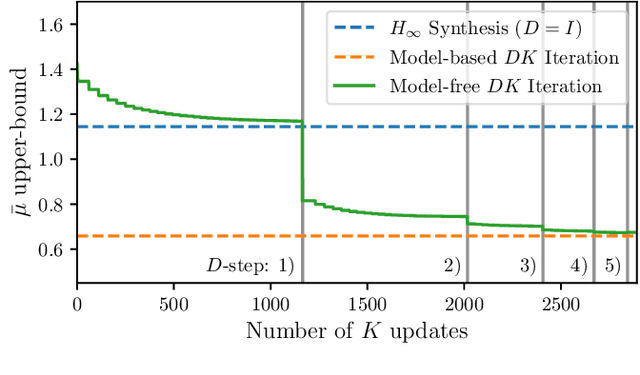
Motivated by the recent empirical success of policy-based reinforcement learning (RL), there has been a research trend studying the performance of policy-based RL methods on standard control benchmark problems. In this paper, we examine the effectiveness of policy-based RL methods on an important robust control problem, namely $\mu$ synthesis. We build a connection between robust adversarial RL and $\mu$ synthesis, and develop a model-free version of the well-known $DK$-iteration for solving state-feedback $\mu$ synthesis with static $D$-scaling. In the proposed algorithm, the $K$ step mimics the classical central path algorithm via incorporating a recently-developed double-loop adversarial RL method as a subroutine, and the $D$ step is based on model-free finite difference approximation. Extensive numerical study is also presented to demonstrate the utility of our proposed model-free algorithm. Our study sheds new light on the connections between adversarial RL and robust control.