 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free $μ$ Synthesis via Adversarial Reinforcement Learning
Paper and Code
Nov 30, 2021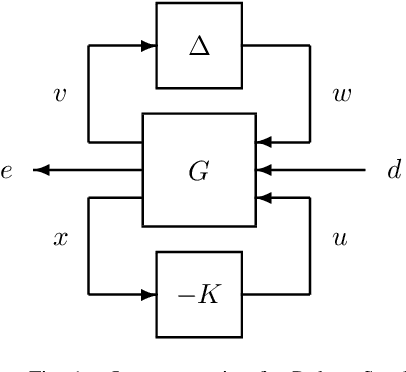
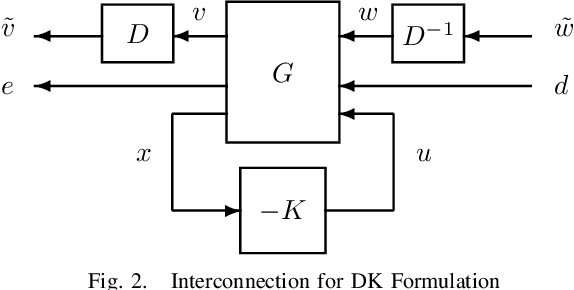
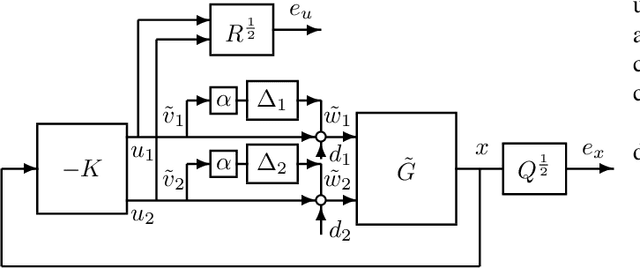
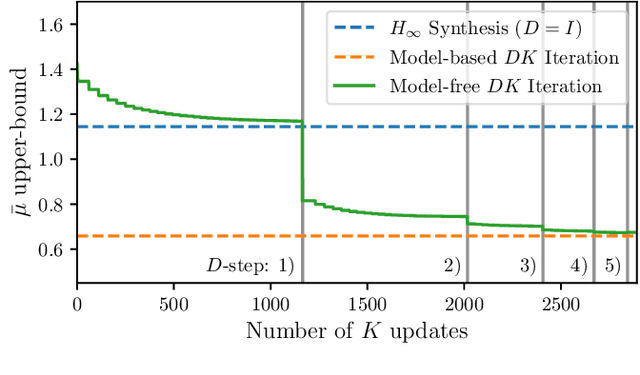
Motivated by the recent empirical success of policy-based reinforcement learning (RL), there has been a research trend studying the performance of policy-based RL methods on standard control benchmark problems. In this paper, we examine the effectiveness of policy-based RL methods on an important robust control problem, namely $\mu$ synthesis. We build a connection between robust adversarial RL and $\mu$ synthesis, and develop a model-free version of the well-known $DK$-iteration for solving state-feedback $\mu$ synthesis with static $D$-scaling. In the proposed algorithm, the $K$ step mimics the classical central path algorithm via incorporating a recently-developed double-loop adversarial RL method as a subroutine, and the $D$ step is based on model-free finite difference approximation. Extensive numerical study is also presented to demonstrate the utility of our proposed model-free algorithm. Our study sheds new light on the connections between adversarial RL and robust control.