 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegoCollab: A Common Representation Negotiation Approach for Heterogeneous Collaborative Perception
Oct 31, 2025Collaborative perception improves task performance by expanding the perception range through information sharing among agents. . Immutable heterogeneity poses a significant challenge in collaborative perception, as participating agents may employ different and fixed perception models. This leads to domain gaps in the intermediate features shared among agents, consequently degrading collaborative performance. Aligning the features of all agents to a common representation can eliminate domain gaps with low training cost. However, in existing methods, the common representation is designated as the representation of a specific agent, making it difficult for agents with significant domain discrepancies from this specific agent to achieve proper alignment. This paper proposes NegoCollab, a heterogeneous collaboration method based on the negotiated common representation. It introduces a negotiator during training to derive the common representation from the local representations of each modality's agent, effectively reducing the inherent domain gap with the various local representations. In NegoCollab, the mutual transformation of features between the local representation space and the common representation space is achieved by a pair of sender and receiver. To better align local representations to the common representation containing multimodal information, we introduce structural alignment loss and pragmatic alignment loss in addition to the distribution alignment loss to supervise the training. This enables the knowledge in the common representation to be fully distilled into the sender.
Cross-sectional imaging of speed-of-sound distribution using photoacoustic reversal beacons
Aug 26, 2024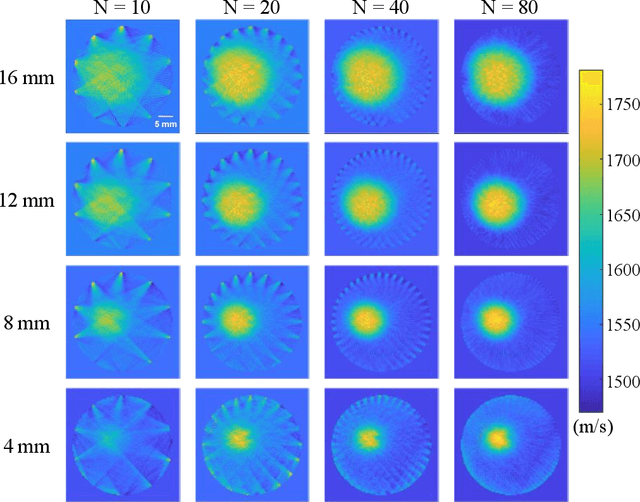
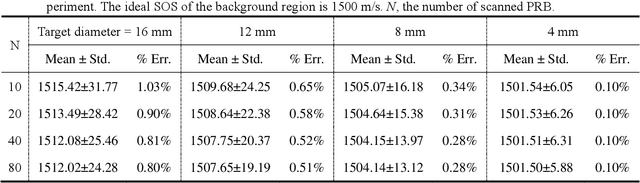
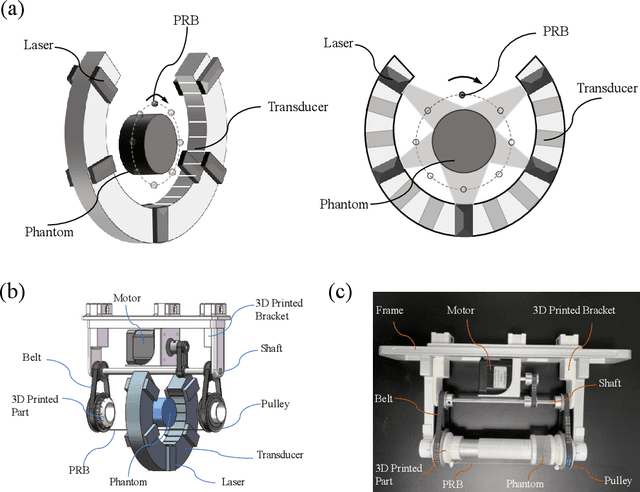
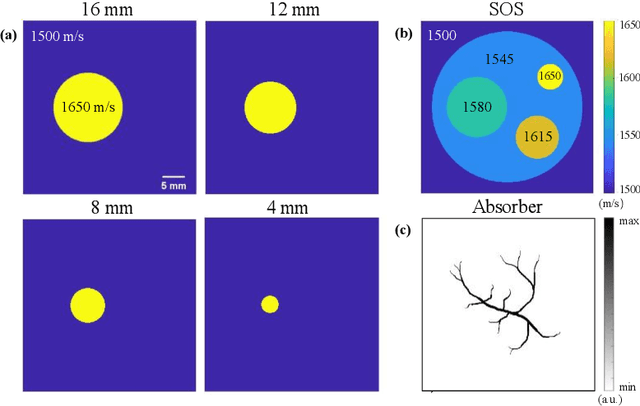
Photoacoustic tomography (PAT) enables non-invasive cross-sectional imaging of biological tissues, but it fails to map the spatial variation of speed-of-sound (SOS) within tissues. While SOS is intimately linked to density and elastic modulus of tissues, the imaging of SOS distri-bution serves as a complementary imaging modality to PAT. Moreover, an accurate SOS map can be leveraged to correct for PAT image degradation arising from acoustic heterogene-ities. Herein, we propose a novel approach for SOS reconstruction using only PAT imaging modality. Our method is based on photoacoustic reversal beacons (PRBs), which are small light-absorbing targets with strong photoacoustic contrast. We excite and scan a number of PRBs positioned at the periphery of the target, and the generated photoacoustic waves prop-agate through the target from various directions, thereby achieve spatial sampling of the internal SOS. We formulate a linear inverse model for pixel-wise SOS reconstruction and solve it with iterative optimization technique. We validate the feasibility of the proposed method through simulations, phantoms, and ex vivo biological tissue tests. Experimental results demonstrate that our approach can achieve accurate reconstruction of SOS distribu-tion. Leveraging the obtained SOS map, we further demonstrate significantly enhanced PAT image reconstruction with acoustic correction.
Segment-Anything Models Achieve Zero-shot Robustness in Autonomous Driving
Aug 19, 2024



Semantic segmentation is a significant perception task in autonomous driving. It suffers from the risks of adversarial examples. In the past few years, deep learning has gradually transitioned from convolutional neural network (CNN) models with a relatively small number of parameters to foundation models with a huge number of parameters. The segment-anything model (SAM) is a generalized image segmentation framework that is capable of handling various types of images and is able to recognize and segment arbitrary objects in an image without the need to train on a specific object. It is a unified model that can handle diverse downstream tasks, including semantic segmentation, object detection, and tracking. In the task of semantic segmentation for autonomous driving, it is significant to study the zero-shot adversarial robustness of SAM. Therefore, we deliver a systematic empirical study on the robustness of SAM without additional training. Based on the experimental results, the zero-shot adversarial robustness of the SAM under the black-box corruptions and white-box adversarial attacks is acceptable, even without the need for additional training. The finding of this study is insightful in that the gigantic model parameters and huge amounts of training data lead to the phenomenon of emergence, which builds a guarantee of adversarial robustness. SAM is a vision foundation model that can be regarded as an early prototype of an artificial general intelligence (AGI) pipeline. In such a pipeline, a unified model can handle diverse tasks. Therefore, this research not only inspects the impact of vision foundation models on safe autonomous driving but also provides a perspective on developing trustworthy AGI. The code is available at: https://github.com/momo1986/robust_sam_iv.