 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAAD-Face: A Massively Annotated Attribute Dataset for Face Images
Dec 02, 2020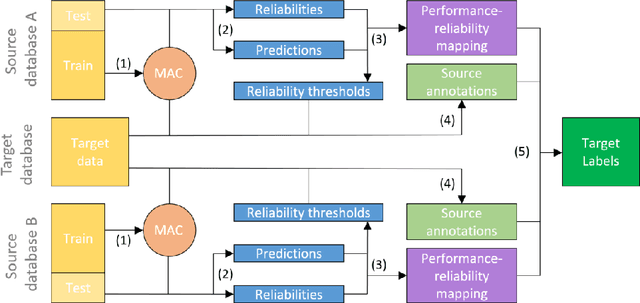
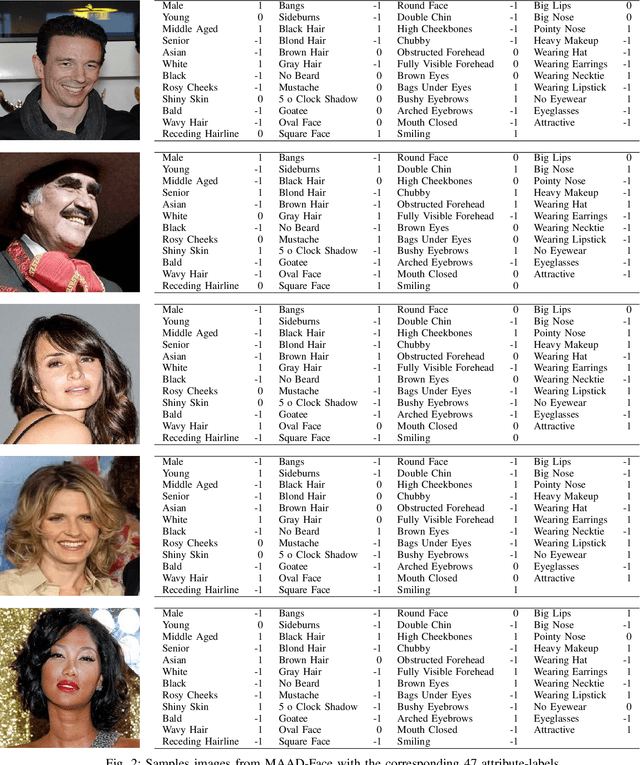
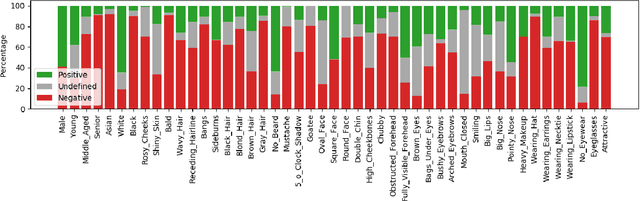
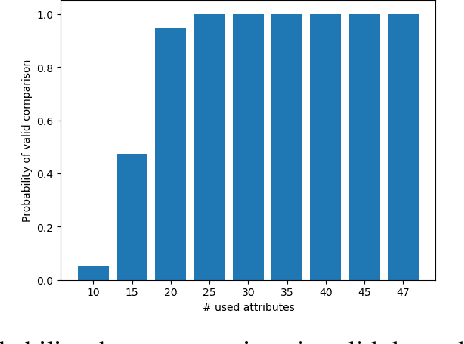
Soft-biometrics play an important role in face biometrics and related fields since these might lead to biased performances, threatens the user's privacy, or are valuable for commercial aspects. Current face databases are specifically constructed for the development of face recognition applications. Consequently, these databases contain large amount of face images but lack in the number of attribute annotations and the overall annotation correctness. In this work, we propose MAADFace, a new face annotations database that is characterized by the large number of its high-quality attribute annotations. MAADFace is build on the VGGFace2 database and thus, consists of 3.3M faces of over 9k individuals. Using a novel annotation transfer-pipeline that allows an accurate label-transfer from multiple source-datasets to a target-dataset, MAAD-Face consists of 123.9M attribute annotations of 47 different binary attributes. Consequently, it provides 15 and 137 times more attribute labels than CelebA and LFW. Our investigation on the annotation quality by three human evaluators demonstrated the superiority of the MAAD-Face annotations over existing databases. Additionally, we make use of the large amount of high-quality annotations from MAAD-Face to study the viability of soft-biometrics for recognition, providing insights about which attributes support genuine and imposter decisions. The MAAD-Face annotations dataset is publicly available.
Learning to Predict the 3D Layout of a Scene
Nov 19, 2020



While 2D object detection has improved significantly over the past, real world applications of computer vision often require an understanding of the 3D layout of a scene. Many recent approaches to 3D detection use LiDAR point clouds for prediction. We propose a method that only uses a single RGB image, thus enabling applications in devices or vehicles that do not have LiDAR sensors. By using an RGB image, we can leverage the maturity and success of recent 2D object detectors, by extending a 2D detector with a 3D detection head. In this paper we discuss different approaches and experiments, including both regression and classification methods, for designing this 3D detection head. Furthermore, we evaluate how subproblems and implementation details impact the overall prediction result. We use the KITTI dataset for training, which consists of street traffic scenes with class labels, 2D bounding boxes and 3D annotations with seven degrees of freedom. Our final architecture is based on Faster R-CNN. The outputs of the convolutional backbone are fixed sized feature maps for every region of interest. Fully connected layers within the network head then propose an object class and perform 2D bounding box regression. We extend the network head by a 3D detection head, which predicts every degree of freedom of a 3D bounding box via classification. We achieve a mean average precision of 47.3% for moderately difficult data, measured at a 3D intersection over union threshold of 70%, as required by the official KITTI benchmark; outperforming previous state-of-the-art single RGB only methods by a large margin.
Beyond Identity: What Information Is Stored in Biometric Face Templates?
Sep 21, 2020
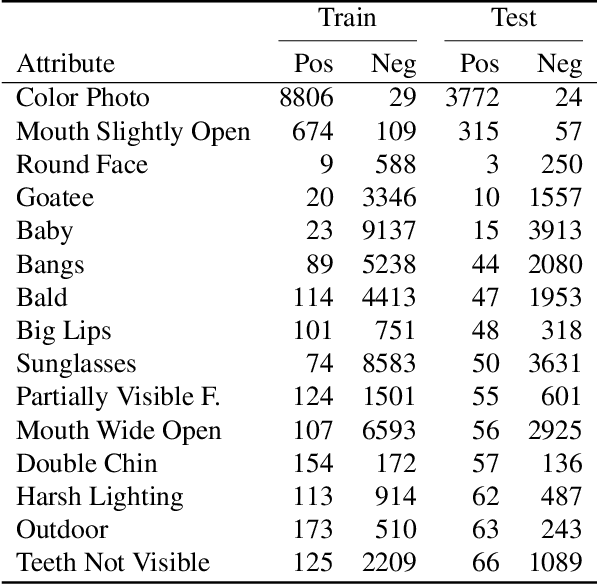
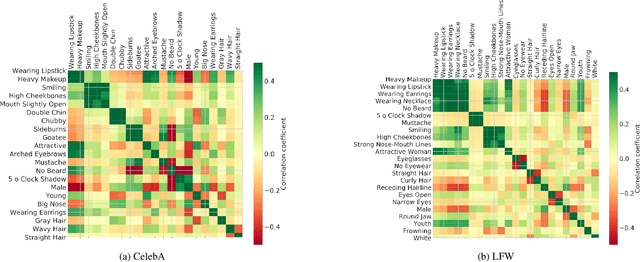
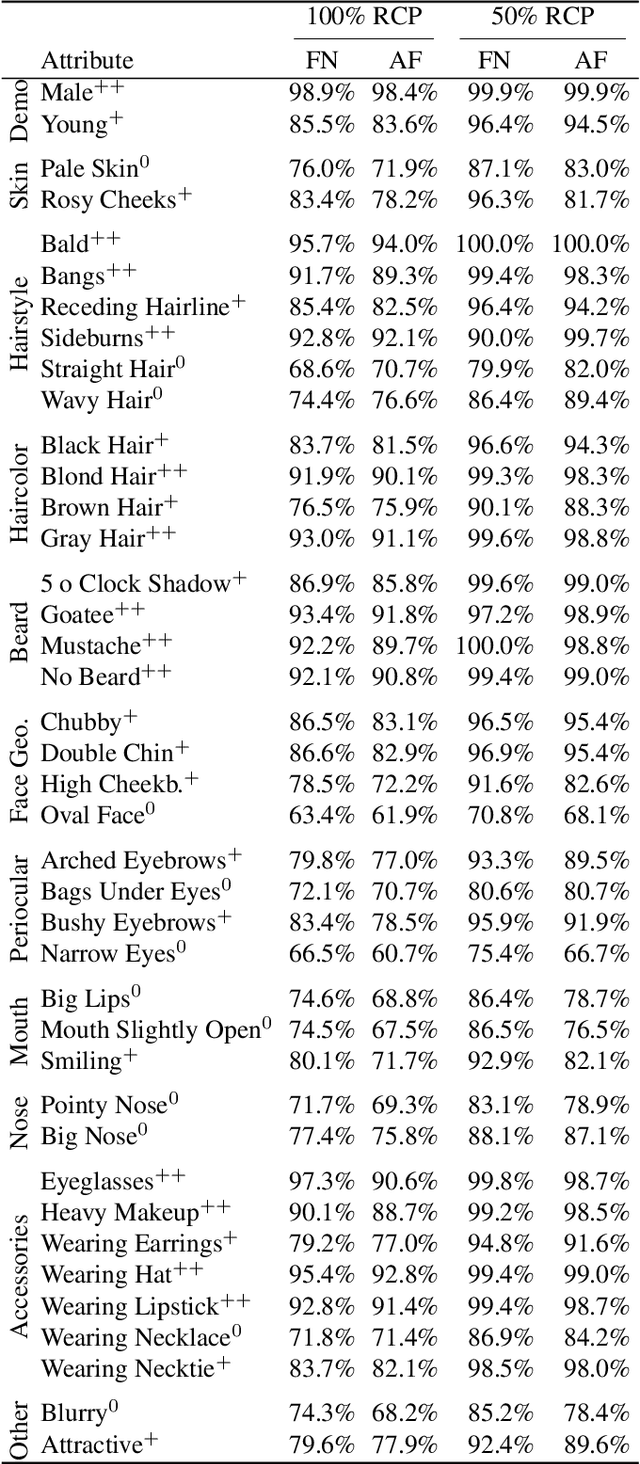
Deeply-learned face representations enable the success of current face recognition systems. Despite the ability of these representations to encode the identity of an individual, recent works have shown that more information is stored within, such as demographics, image characteristics, and social traits. This threatens the user's privacy, since for many applications these templates are expected to be solely used for recognition purposes. Knowing the encoded information in face templates helps to develop bias-mitigating and privacy-preserving face recognition technologies. This work aims to support the development of these two branches by analysing face templates regarding 113 attributes. Experiments were conducted on two publicly available face embeddings. For evaluating the predictability of the attributes, we trained a massive attribute classifier that is additionally able to accurately state its prediction confidence. This allows us to make more sophisticated statements about the attribute predictability. The results demonstrate that up to 74 attributes can be accurately predicted from face templates. Especially non-permanent attributes, such as age, hairstyles, haircolors, beards, and various accessories, found to be easily-predictable. Since face recognition systems aim to be robust against these variations, future research might build on this work to develop more understandable privacy preserving solutions and build robust and fair face templates.