 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAAD-Face: A Massively Annotated Attribute Dataset for Face Images
Paper and Code
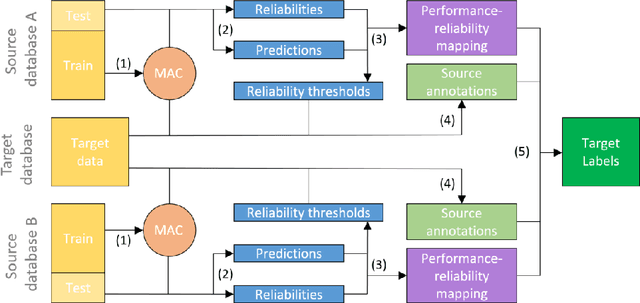
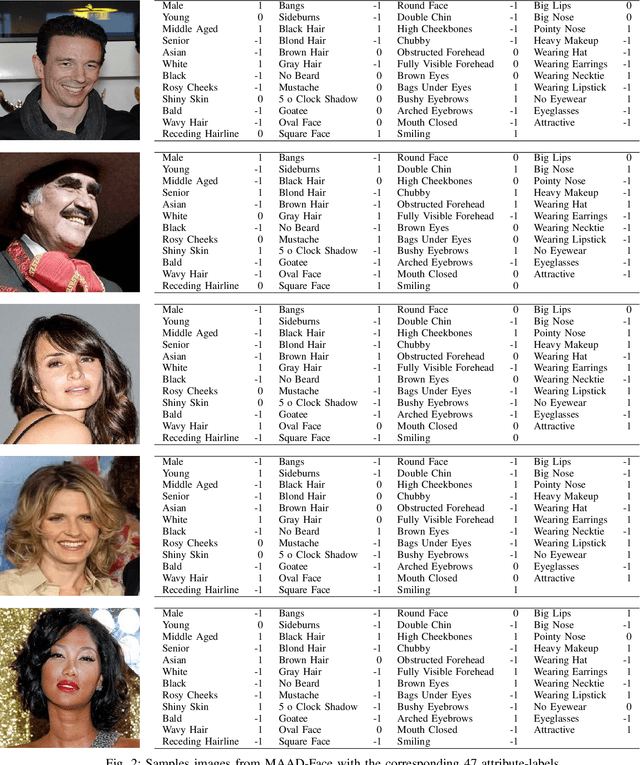
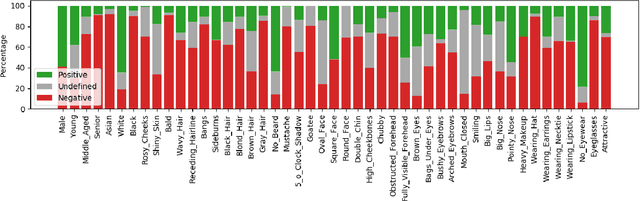
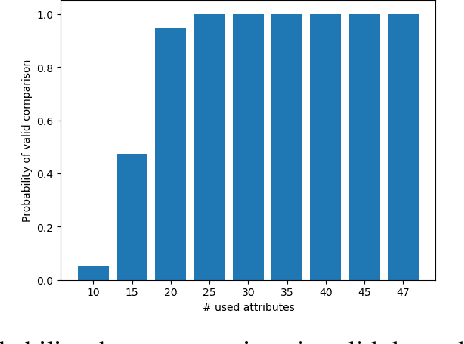
Soft-biometrics play an important role in face biometrics and related fields since these might lead to biased performances, threatens the user's privacy, or are valuable for commercial aspects. Current face databases are specifically constructed for the development of face recognition applications. Consequently, these databases contain large amount of face images but lack in the number of attribute annotations and the overall annotation correctness. In this work, we propose MAADFace, a new face annotations database that is characterized by the large number of its high-quality attribute annotations. MAADFace is build on the VGGFace2 database and thus, consists of 3.3M faces of over 9k individuals. Using a novel annotation transfer-pipeline that allows an accurate label-transfer from multiple source-datasets to a target-dataset, MAAD-Face consists of 123.9M attribute annotations of 47 different binary attributes. Consequently, it provides 15 and 137 times more attribute labels than CelebA and LFW. Our investigation on the annotation quality by three human evaluators demonstrated the superiority of the MAAD-Face annotations over existing databases. Additionally, we make use of the large amount of high-quality annotations from MAAD-Face to study the viability of soft-biometrics for recognition, providing insights about which attributes support genuine and imposter decisions. The MAAD-Face annotations dataset is publicly available.