 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Risks: Axiomatic Risk Attributions for Financial Models
Jun 07, 2025In recent years, machine learning models have achieved great success at the expense of highly complex black-box structures. By using axiomatic attribution methods, we can fairly allocate the contributions of each feature, thus allowing us to interpret the model predictions. In high-risk sectors such as finance, risk is just as important as mean predictions. Throughout this work, we address the following risk attribution problem: how to fairly allocate the risk given a model with data? We demonstrate with analysis and empirical examples that risk can be well allocated by extending the Shapley value framework.
* This article has been accepted for publication in Quantitative Finance, published by Taylor & Francis
FinML-Chain: A Blockchain-Integrated Dataset for Enhanced Financial Machine Learning
Nov 25, 2024
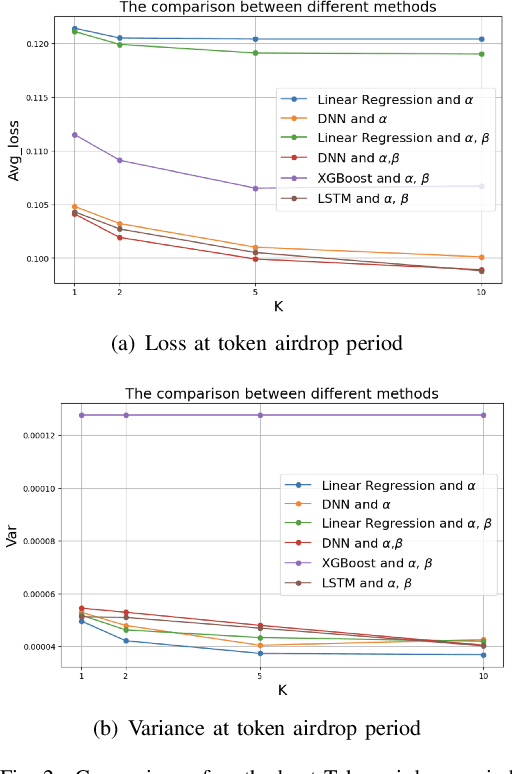
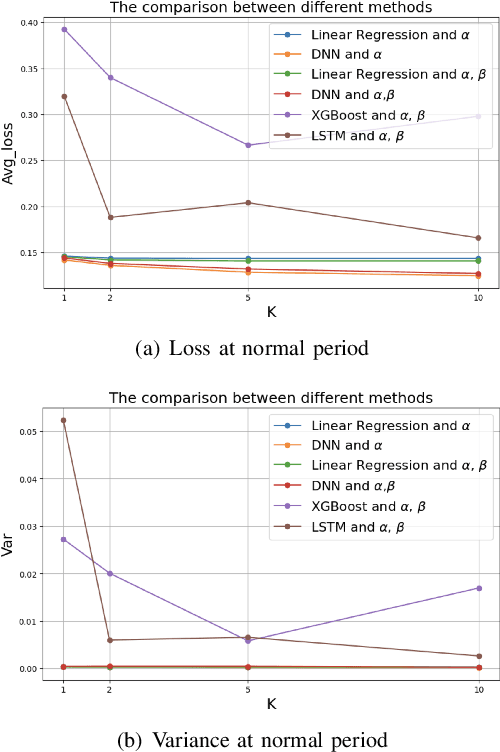

Machine learning is critical for innovation and efficiency in financial markets, offering predictive models and data-driven decision-making. However, challenges such as missing data, lack of transparency, untimely updates, insecurity, and incompatible data sources limit its effectiveness. Blockchain technology, with its transparency, immutability, and real-time updates, addresses these challenges. We present a framework for integrating high-frequency on-chain data with low-frequency off-chain data, providing a benchmark for addressing novel research questions in economic mechanism design. This framework generates modular, extensible datasets for analyzing economic mechanisms such as the Transaction Fee Mechanism, enabling multi-modal insights and fairness-driven evaluations. Using four machine learning techniques, including linear regression, deep neural networks, XGBoost, and LSTM models, we demonstrate the framework's ability to produce datasets that advance financial research and improve understanding of blockchain-driven systems. Our contributions include: (1) proposing a research scenario for the Transaction Fee Mechanism and demonstrating how the framework addresses previously unexplored questions in economic mechanism design; (2) providing a benchmark for financial machine learning by open-sourcing a sample dataset generated by the framework and the code for the pipeline, enabling continuous dataset expansion; and (3) promoting reproducibility, transparency, and collaboration by fully open-sourcing the framework and its outputs. This initiative supports researchers in extending our work and developing innovative financial machine-learning models, fostering advancements at the intersection of machine learning, blockchain, and economics.
Attribution Methods in Asset Pricing: Do They Account for Risk?
Jul 12, 2024Over the past few decades, machine learning models have been extremely successful. As a result of axiomatic attribution methods, feature contributions have been explained more clearly and rigorously. There are, however, few studies that have examined domain knowledge in conjunction with the axioms. In this study, we examine asset pricing in finance, a field closely related to risk management. Consequently, when applying machine learning models, we must ensure that the attribution methods reflect the underlying risks accurately. In this work, we present and study several axioms derived from asset pricing domain knowledge. It is shown that while Shapley value and Integrated Gradients preserve most axioms, neither can satisfy all axioms. Using extensive analytical and empirical examples, we demonstrate how attribution methods can reflect risks and when they should not be used.
Can I Trust the Explanations? Investigating Explainable Machine Learning Methods for Monotonic Models
Sep 23, 2023In recent years, explainable machine learning methods have been very successful. Despite their success, most explainable machine learning methods are applied to black-box models without any domain knowledge. By incorporating domain knowledge, science-informed machine learning models have demonstrated better generalization and interpretation. But do we obtain consistent scientific explanations if we apply explainable machine learning methods to science-informed machine learning models? This question is addressed in the context of monotonic models that exhibit three different types of monotonicity. To demonstrate monotonicity, we propose three axioms. Accordingly, this study shows that when only individual monotonicity is involved, the baseline Shapley value provides good explanations; however, when strong pairwise monotonicity is involved, the Integrated gradients method provides reasonable explanations on average.
How to address monotonicity for model risk management?
Apr 28, 2023

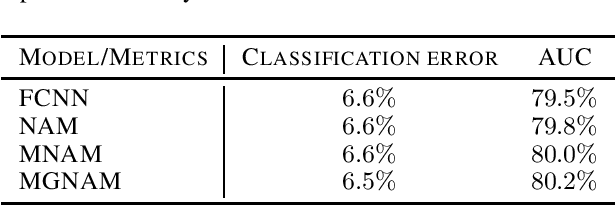

In this paper, we study the problem of establishing the accountability and fairness of transparent machine learning models through monotonicity. Although there have been numerous studies on individual monotonicity, pairwise monotonicity is often overlooked in the existing literature. This paper studies transparent neural networks in the presence of three types of monotonicity: individual monotonicity, weak pairwise monotonicity, and strong pairwise monotonicity. As a means of achieving monotonicity while maintaining transparency, we propose the monotonic groves of neural additive models. As a result of empirical examples, we demonstrate that monotonicity is often violated in practice and that monotonic groves of neural additive models are transparent, accountable, and fair.
Monotonicity for AI ethics and society: An empirical study of the monotonic neural additive model in criminology, education, health care, and finance
Jan 17, 2023Algorithm fairness in the application of artificial intelligence (AI) is essential for a better society. As the foundational axiom of social mechanisms, fairness consists of multiple facets. Although the machine learning (ML) community has focused on intersectionality as a matter of statistical parity, especially in discrimination issues, an emerging body of literature addresses another facet -- monotonicity. Based on domain expertise, monotonicity plays a vital role in numerous fairness-related areas, where violations could misguide human decisions and lead to disastrous consequences. In this paper, we first systematically evaluate the significance of applying monotonic neural additive models (MNAMs), which use a fairness-aware ML algorithm to enforce both individual and pairwise monotonicity principles, for the fairness of AI ethics and society. We have found, through a hybrid method of theoretical reasoning, simulation, and extensive empirical analysis, that considering monotonicity axioms is essential in all areas of fairness, including criminology, education, health care, and finance. Our research contributes to the interdisciplinary research at the interface of AI ethics, explainable AI (XAI), and human-computer interactions (HCIs). By evidencing the catastrophic consequences if monotonicity is not met, we address the significance of monotonicity requirements in AI applications. Furthermore, we demonstrate that MNAMs are an effective fairness-aware ML approach by imposing monotonicity restrictions integrating human intelligence.
Interpretable Selective Learning in Credit Risk
Sep 21, 2022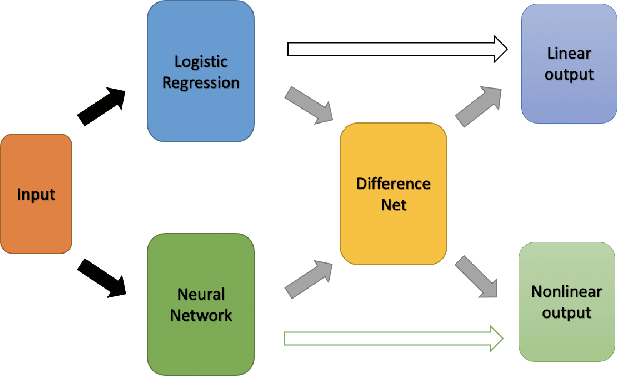

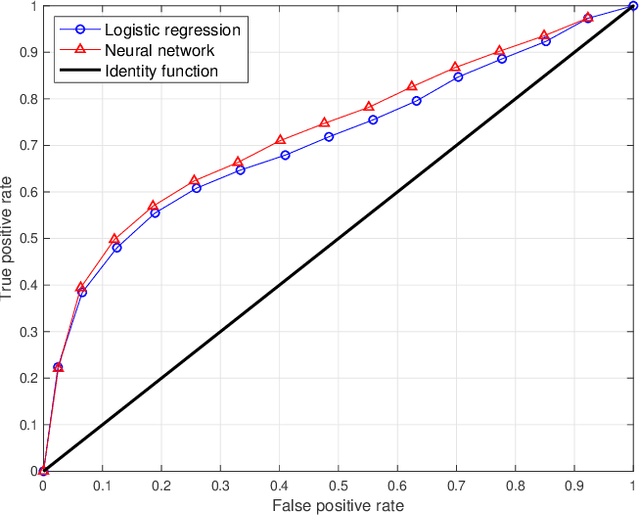

The forecasting of the credit default risk has been an important research field for several decades. Traditionally, logistic regression has been widely recognized as a solution due to its accuracy and interpretability. As a recent trend, researchers tend to use more complex and advanced machine learning methods to improve the accuracy of the prediction. Although certain non-linear machine learning methods have better predictive power, they are often considered to lack interpretability by financial regulators. Thus, they have not been widely applied in credit risk assessment. We introduce a neural network with the selective option to increase interpretability by distinguishing whether the datasets can be explained by the linear models or not. We find that, for most of the datasets, logistic regression will be sufficient, with reasonable accuracy; meanwhile, for some specific data portions, a shallow neural network model leads to much better accuracy without significantly sacrificing the interpretability.
Generalized Gloves of Neural Additive Models: Pursuing transparent and accurate machine learning models in finance
Sep 21, 2022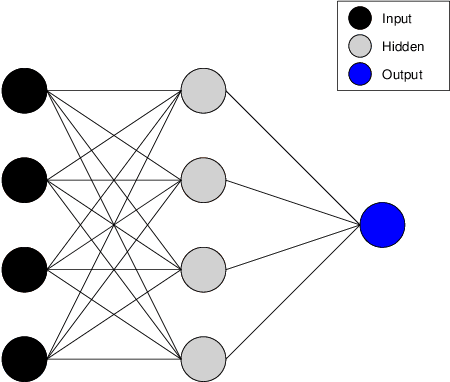
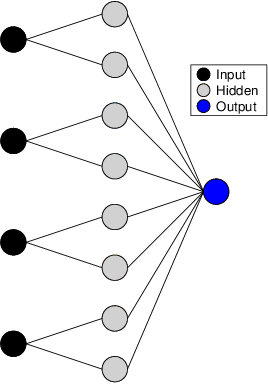
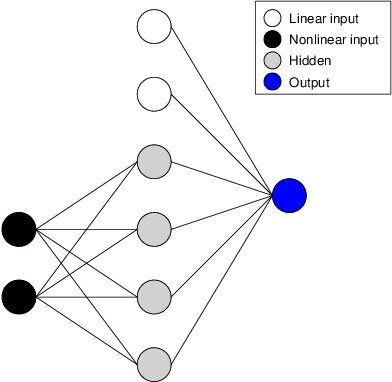
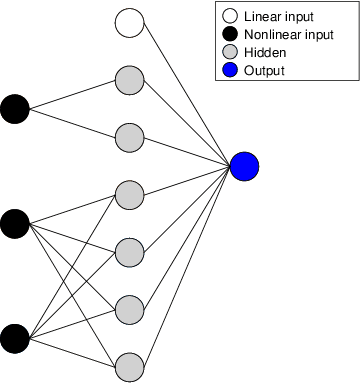
For many years, machine learning methods have been used in a wide range of fields, including computer vision and natural language processing. While machine learning methods have significantly improved model performance over traditional methods, their black-box structure makes it difficult for researchers to interpret results. For highly regulated financial industries, transparency, explainability, and fairness are equally, if not more, important than accuracy. Without meeting regulated requirements, even highly accurate machine learning methods are unlikely to be accepted. We address this issue by introducing a novel class of transparent and interpretable machine learning algorithms known as generalized gloves of neural additive models. The generalized gloves of neural additive models separate features into three categories: linear features, individual nonlinear features, and interacted nonlinear features. Additionally, interactions in the last category are only local. The linear and nonlinear components are distinguished by a stepwise selection algorithm, and interacted groups are carefully verified by applying additive separation criteria. Empirical results demonstrate that generalized gloves of neural additive models provide optimal accuracy with the simplest architecture, allowing for a highly accurate, transparent, and explainable approach to machine learning.
Monotonic Neural Additive Models: Pursuing Regulated Machine Learning Models for Credit Scoring
Sep 21, 2022
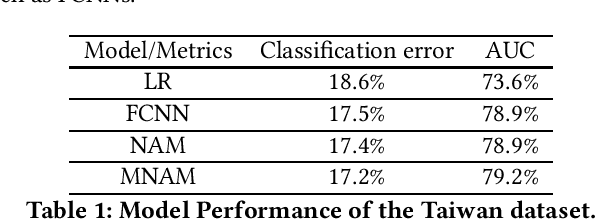
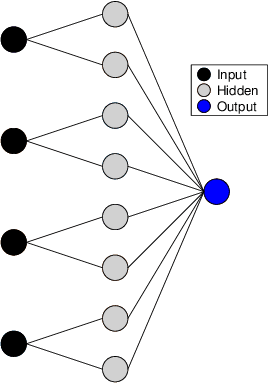
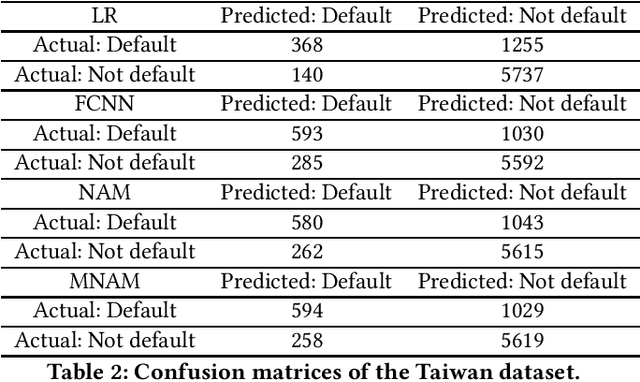
The forecasting of credit default risk has been an active research field for several decades. Historically, logistic regression has been used as a major tool due to its compliance with regulatory requirements: transparency, explainability, and fairness. In recent years, researchers have increasingly used complex and advanced machine learning methods to improve prediction accuracy. Even though a machine learning method could potentially improve the model accuracy, it complicates simple logistic regression, deteriorates explainability, and often violates fairness. In the absence of compliance with regulatory requirements, even highly accurate machine learning methods are unlikely to be accepted by companies for credit scoring. In this paper, we introduce a novel class of monotonic neural additive models, which meet regulatory requirements by simplifying neural network architecture and enforcing monotonicity. By utilizing the special architectural features of the neural additive model, the monotonic neural additive model penalizes monotonicity violations effectively. Consequently, the computational cost of training a monotonic neural additive model is similar to that of training a neural additive model, as a free lunch. We demonstrate through empirical results that our new model is as accurate as black-box fully-connected neural networks, providing a highly accurate and regulated machine learning method.
Two-stage Modeling for Prediction with Confidence
Sep 19, 2022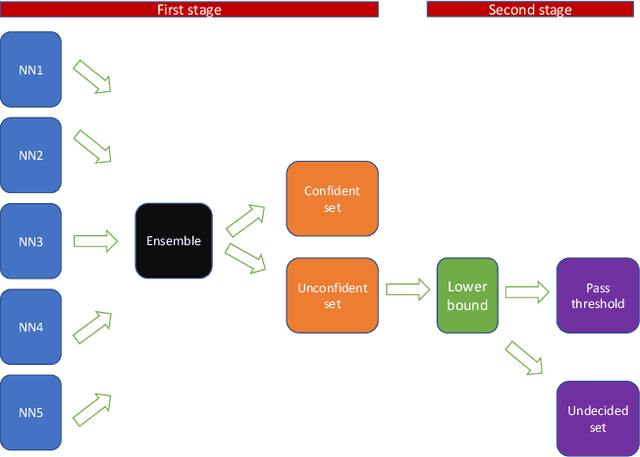
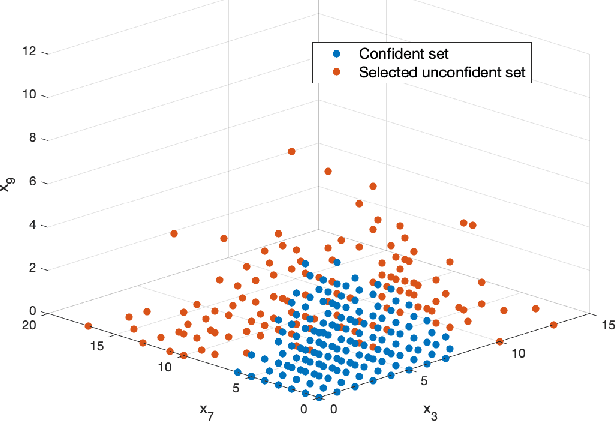
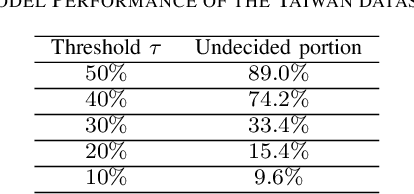
The use of neural networks has been very successful in a wide variety of applications. However, it has recently been observed that it is difficult to generalize the performance of neural networks under the condition of distributional shift. Several efforts have been made to identify potential out-of-distribution inputs. Although existing literature has made significant progress with regard to images and textual data, finance has been overlooked. The aim of this paper is to investigate the distribution shift in the credit scoring problem, one of the most important applications of finance. For the potential distribution shift problem, we propose a novel two-stage model. Using the out-of-distribution detection method, data is first separated into confident and unconfident sets. As a second step, we utilize the domain knowledge with a mean-variance optimization in order to provide reliable bounds for unconfident samples. Using empirical results, we demonstrate that our model offers reliable predictions for the vast majority of datasets. It is only a small portion of the dataset that is inherently difficult to judge, and we leave them to the judgment of human beings. Based on the two-stage model, highly confident predictions have been made and potential risks associated with the model have been significantly reduced.