 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Modeling for Prediction with Confidence
Paper and Code
Sep 19, 2022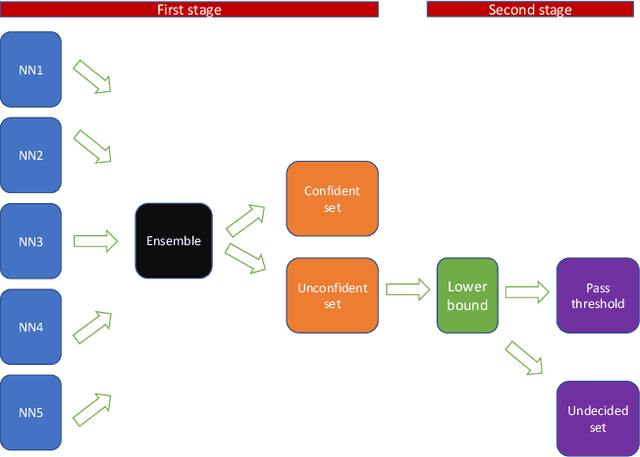
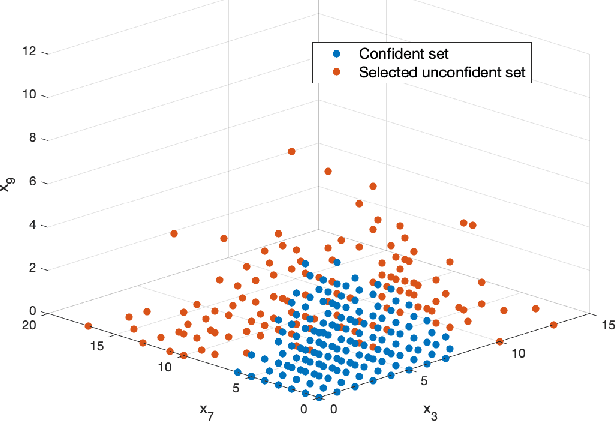
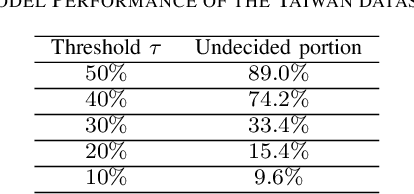
The use of neural networks has been very successful in a wide variety of applications. However, it has recently been observed that it is difficult to generalize the performance of neural networks under the condition of distributional shift. Several efforts have been made to identify potential out-of-distribution inputs. Although existing literature has made significant progress with regard to images and textual data, finance has been overlooked. The aim of this paper is to investigate the distribution shift in the credit scoring problem, one of the most important applications of finance. For the potential distribution shift problem, we propose a novel two-stage model. Using the out-of-distribution detection method, data is first separated into confident and unconfident sets. As a second step, we utilize the domain knowledge with a mean-variance optimization in order to provide reliable bounds for unconfident samples. Using empirical results, we demonstrate that our model offers reliable predictions for the vast majority of datasets. It is only a small portion of the dataset that is inherently difficult to judge, and we leave them to the judgment of human beings. Based on the two-stage model, highly confident predictions have been made and potential risks associated with the model have been significantly reduced.