 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Hashing with End-to-End Binary Deep Neural Network
Oct 27, 2018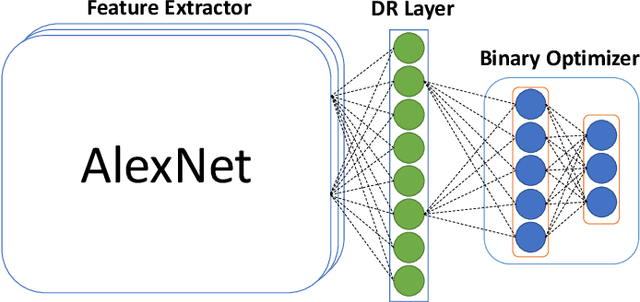
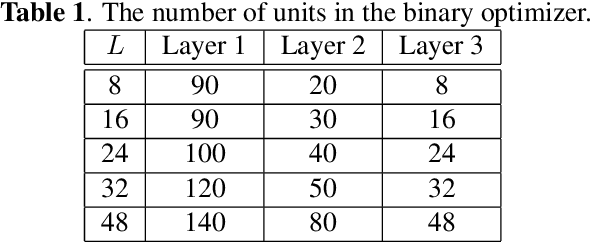
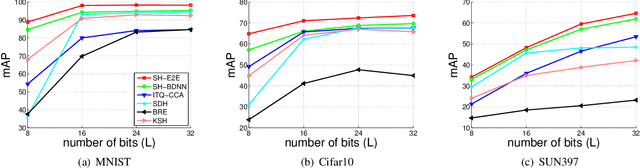
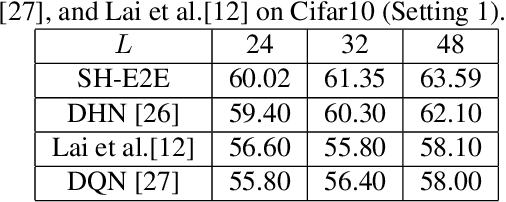
Image hashing is a popular technique applied to large scale content-based visual retrieval due to its compact and efficient binary codes. Our work proposes a new end-to-end deep network architecture for supervised hashing which directly learns binary codes from input images and maintains good properties over binary codes such as similarity preservation, independence, and balancing. Furthermore, we also propose a new learning scheme that can cope with the binary constrained loss function. The proposed algorithm not only is scalable for learning over large-scale datasets but also outperforms state-of-the-art supervised hashing methods, which are illustrated throughout extensive experiments from various image retrieval benchmarks.
From Selective Deep Convolutional Features to Compact Binary Representations for Image Retrieval
Jul 20, 2018

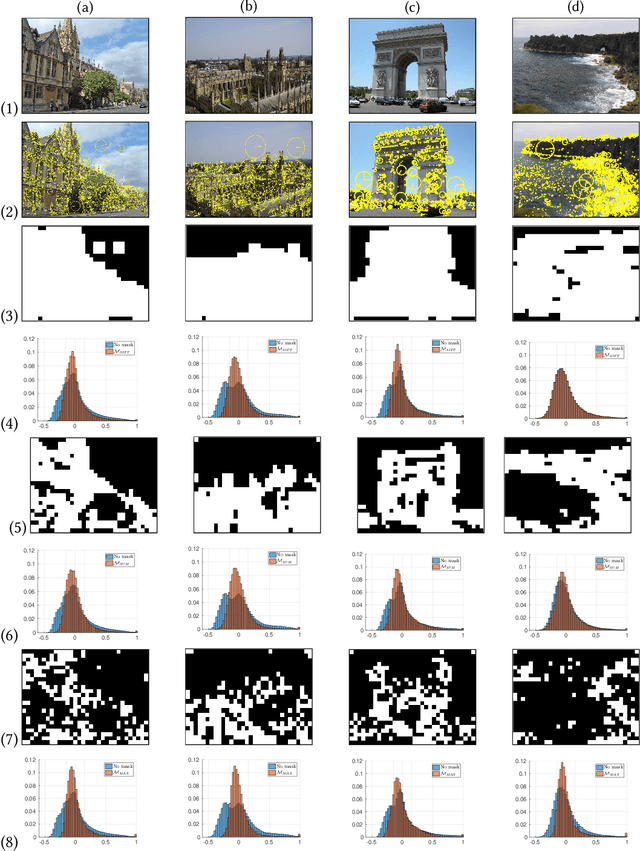

In the large-scale image retrieval task, the two most important requirements are the discriminability of image representations and the efficiency in computation and storage of representations. Regarding the former requirement, Convolutional Neural Network (CNN) is proven to be a very powerful tool to extract highly discriminative local descriptors for effective image search. Additionally, in order to further improve the discriminative power of the descriptors, recent works adopt fine-tuned strategies. In this paper, taking a different approach, we propose a novel, computationally efficient, and competitive framework. Specifically, we firstly propose various strategies to compute masks, namely SIFT-mask, SUM-mask, and MAX-mask, to select a representative subset of local convolutional features and eliminate redundant features. Our in-depth analyses demonstrate that proposed masking schemes are effective to address the burstiness drawback and improve retrieval accuracy. Secondly, we propose to employ recent embedding and aggregating methods which can significantly boost the feature discriminability. Regarding the computation and storage efficiency, we include a hashing module to produce very compact binary image representations. Extensive experiments on six image retrieval benchmarks demonstrate that our proposed framework achieves the state-of-the-art retrieval performances.
On-device Scalable Image-based Localization
Feb 10, 2018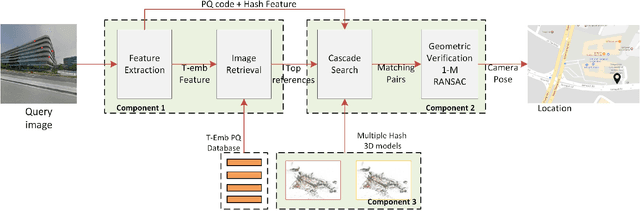

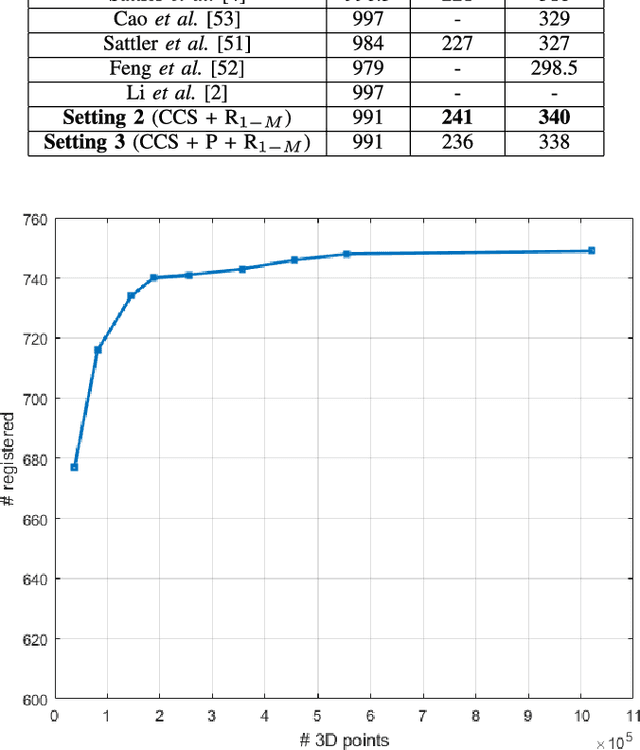

We present the scalable design of an entire on-device system for large-scale urban localization. The proposed design integrates compact image retrieval and 2D-3D correspondence search to estimate the camera pose in a city region of extensive coverage. Our design is GPS agnostic and does not require the network connection. The system explores the use of an abundant dataset: Google Street View (GSV). In order to overcome the resource constraints of mobile devices, we carefully optimize the system design at every stage: we use state-of-the-art image retrieval to quickly locate candidate regions and limit candidate 3D points; we propose a new hashing-based approach for fast computation of 2D-3D correspondences and new one-many RANSAC for accurate pose estimation. The experiments are conducted on benchmark datasets for 2D-3D correspondence search and on a database of over 227K Google Street View (GSV) images for the overall system. Results show that our 2D-3D correspondence search achieves state-of-the-art performance on some benchmark datasets and our system can accurately and quickly localize mobile images; the median error is less than 4 meters and the processing time is averagely less than 10s on a typical mobile device.
Compact Hash Code Learning with Binary Deep Neural Network
Feb 06, 2018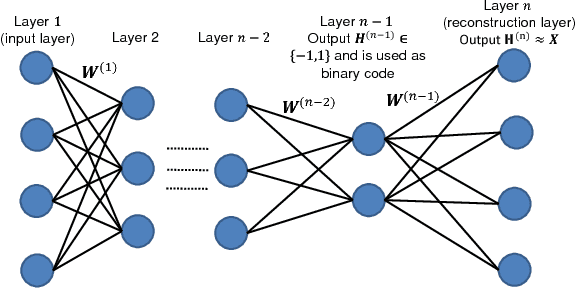
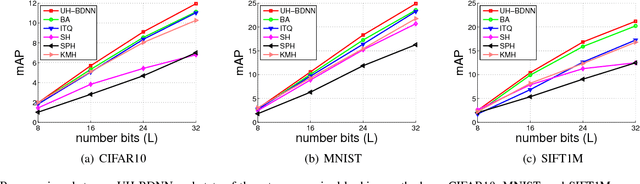
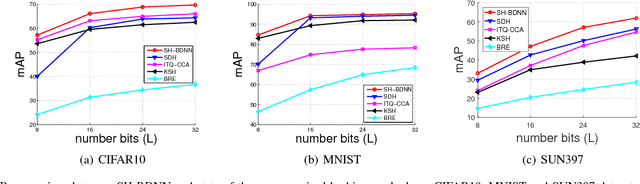
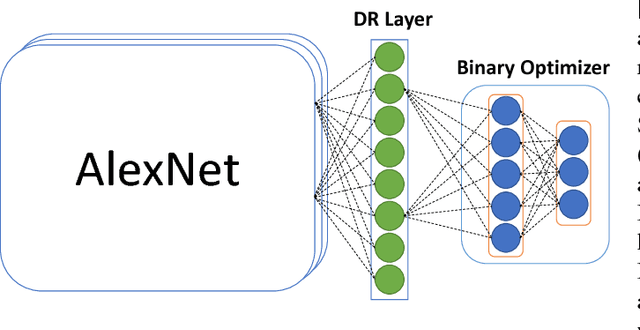
In this work, we firstly propose deep network models and learning algorithms for learning binary hash codes given image representations under both unsupervised and supervised manners. Then, by leveraging the powerful capacity of convolutional neural networks, we propose an end-to-end architecture which jointly learns to extract visual features and produce binary hash codes. Our novel network designs constrain one hidden layer to directly output the binary codes. This addresses a challenging issue in some previous works: optimizing nonsmooth objective functions due to binarization. Additionally, we incorporate independence and balance properties in the direct and strict forms into the learning schemes. Furthermore, we also include similarity preserving property in our objective functions. Our resulting optimizations involving these binary, independence, and balance constraints are difficult to solve. We propose to attack them with alternating optimization and careful relaxation. Experimental results on the benchmark datasets show that our proposed methods compare favorably with the state of the art.
Selective Deep Convolutional Features for Image Retrieval
Nov 27, 2017
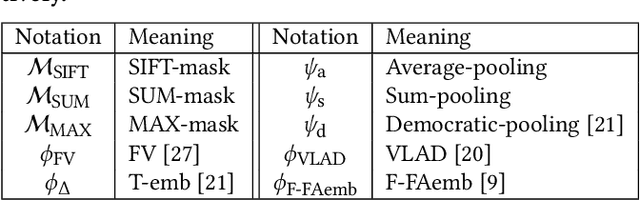


Convolutional Neural Network (CNN) is a very powerful approach to extract discriminative local descriptors for effective image search. Recent work adopts fine-tuned strategies to further improve the discriminative power of the descriptors. Taking a different approach, in this paper, we propose a novel framework to achieve competitive retrieval performance. Firstly, we propose various masking schemes, namely SIFT-mask, SUM-mask, and MAX-mask, to select a representative subset of local convolutional features and remove a large number of redundant features. We demonstrate that this can effectively address the burstiness issue and improve retrieval accuracy. Secondly, we propose to employ recent embedding and aggregating methods to further enhance feature discriminability. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art retrieval accuracy.
Enhance Feature Discrimination for Unsupervised Hashing
Jul 04, 2017
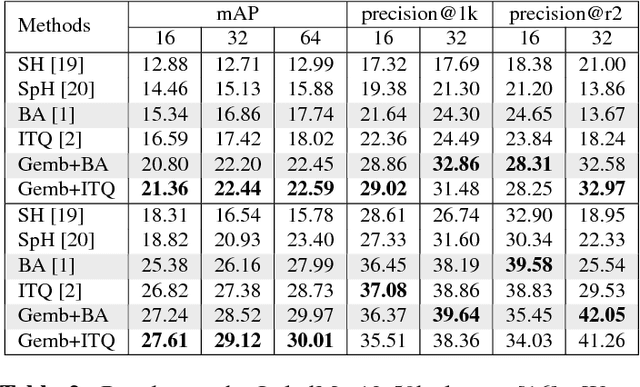
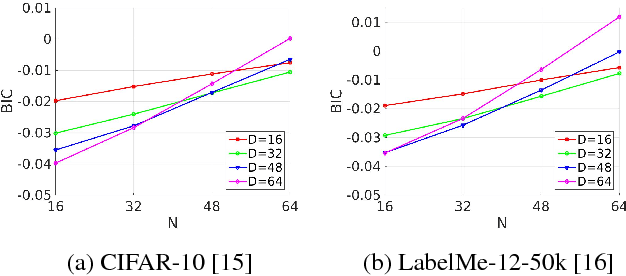
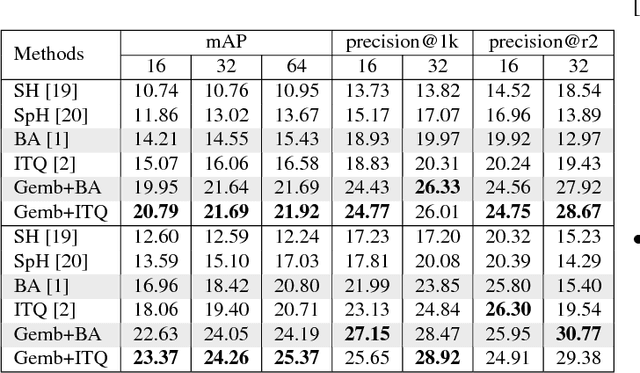
We introduce a novel approach to improve unsupervised hashing. Specifically, we propose a very efficient embedding method: Gaussian Mixture Model embedding (Gemb). The proposed method, using Gaussian Mixture Model, embeds feature vector into a low-dimensional vector and, simultaneously, enhances the discriminative property of features before passing them into hashing. Our experiment shows that the proposed method boosts the hashing performance of many state-of-the-art, e.g. Binary Autoencoder (BA) [1], Iterative Quantization (ITQ) [2], in standard evaluation metrics for the three main benchmark datasets.
Simultaneous Feature Aggregating and Hashing for Large-scale Image Search
Apr 04, 2017
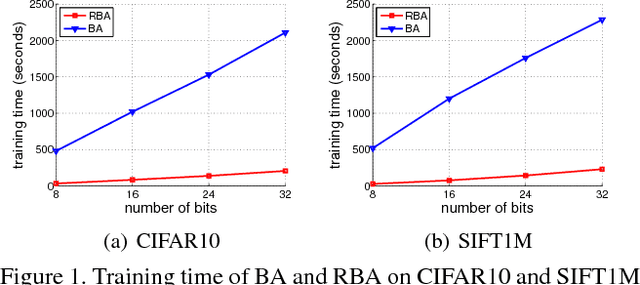
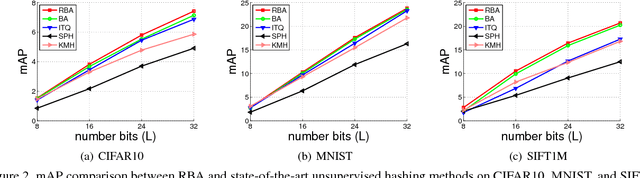
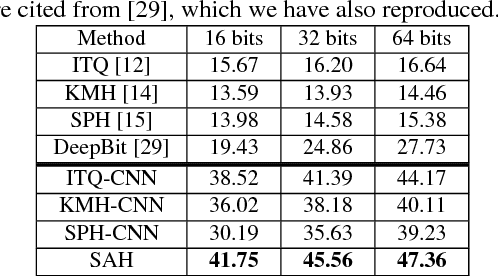
In most state-of-the-art hashing-based visual search systems, local image descriptors of an image are first aggregated as a single feature vector. This feature vector is then subjected to a hashing function that produces a binary hash code. In previous work, the aggregating and the hashing processes are designed independently. In this paper, we propose a novel framework where feature aggregating and hashing are designed simultaneously and optimized jointly. Specifically, our joint optimization produces aggregated representations that can be better reconstructed by some binary codes. This leads to more discriminative binary hash codes and improved retrieval accuracy. In addition, we also propose a fast version of the recently-proposed Binary Autoencoder to be used in our proposed framework. We perform extensive retrieval experiments on several benchmark datasets with both SIFT and convolutional features. Our results suggest that the proposed framework achieves significant improvements over the state of the art.