 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
What Have We Achieved on Text Summarization?
Oct 09, 2020
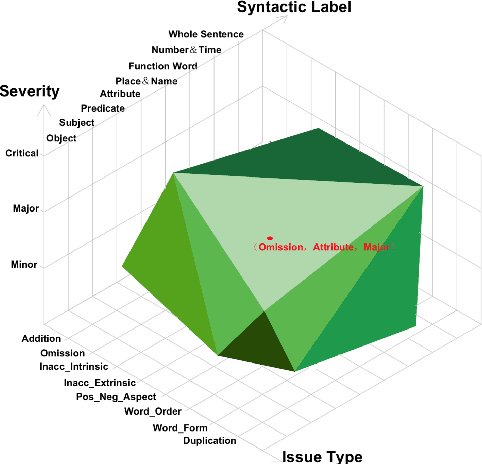

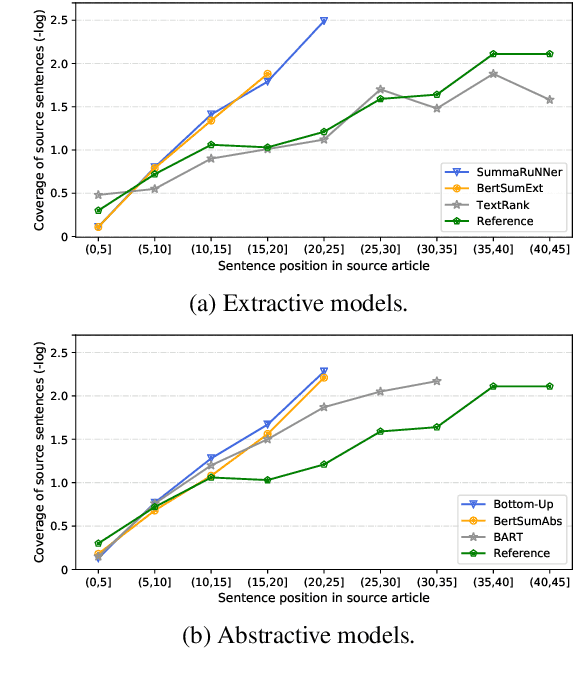
Deep learning has led to significant improvement in text summarization with various methods investigated and improved ROUGE scores reported over the years. However, gaps still exist between summaries produced by automatic summarizers and human professionals. Aiming to gain more understanding of summarization systems with respect to their strengths and limits on a fine-grained syntactic and semantic level, we consult the Multidimensional Quality Metric(MQM) and quantify 8 major sources of errors on 10 representative summarization models manually. Primarily, we find that 1) under similar settings, extractive summarizers are in general better than their abstractive counterparts thanks to strength in faithfulness and factual-consistency; 2) milestone techniques such as copy, coverage and hybrid extractive/abstractive methods do bring specific improvements but also demonstrate limitations; 3) pre-training techniques, and in particular sequence-to-sequence pre-training, are highly effective for improving text summarization, with BART giving the best results.
LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning
Jul 16, 2020



Machine reading is a fundamental task for testing the capability of natural language understanding, which is closely related to human cognition in many aspects. With the rising of deep learning techniques, algorithmic models rival human performances on simple QA, and thus increasingly challenging machine reading datasets have been proposed. Though various challenges such as evidence integration and commonsense knowledge have been integrated, one of the fundamental capabilities in human reading, namely logical reasoning, is not fully investigated. We build a comprehensive dataset, named LogiQA, which is sourced from expert-written questions for testing human Logical reasoning. It consists of 8,678 QA instances, covering multiple types of deductive reasoning. Results show that state-of-the-art neural models perform by far worse than human ceiling. Our dataset can also serve as a benchmark for reinvestigating logical AI under the deep learning NLP setting. The dataset is freely available at https://github.com/lgw863/LogiQA-dataset
Evaluating Commonsense in Pre-trained Language Models
Nov 27, 2019
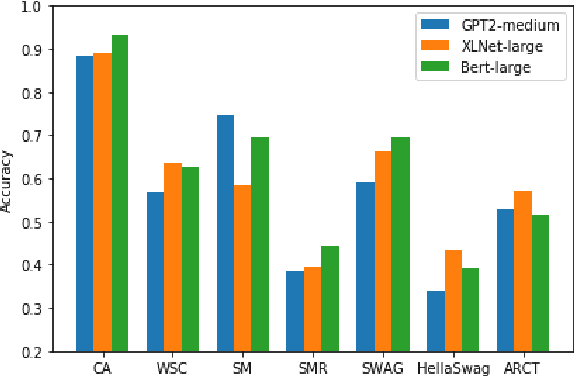


Contextualized representations trained over large raw text data have given remarkable improvements for NLP tasks including question answering and reading comprehension. There have been works showing that syntactic, semantic and word sense knowledge are contained in such representations, which explains why they benefit such tasks. However, relatively little work has been done investigating commonsense knowledge contained in contextualized representations, which is crucial for human question answering and reading comprehension. We study the commonsense ability of GPT, BERT, XLNet, and RoBERTa by testing them on seven challenging benchmarks, finding that language modeling and its variants are effective objectives for promoting models' commonsense ability while bi-directional context and larger training set are bonuses. We additionally find that current models do poorly on tasks require more necessary inference steps. Finally, we test the robustness of models by making dual test cases, which are correlated so that the correct prediction of one sample should lead to correct prediction of the other. Interestingly, the models show confusion on these test cases, which suggests that they learn commonsense at the surface rather than the deep level. We release a test set, named CATs publicly, for future research.