 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Have We Achieved on Text Summarization?
Paper and Code

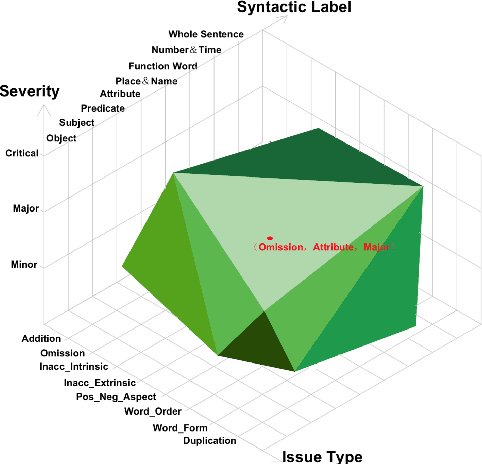

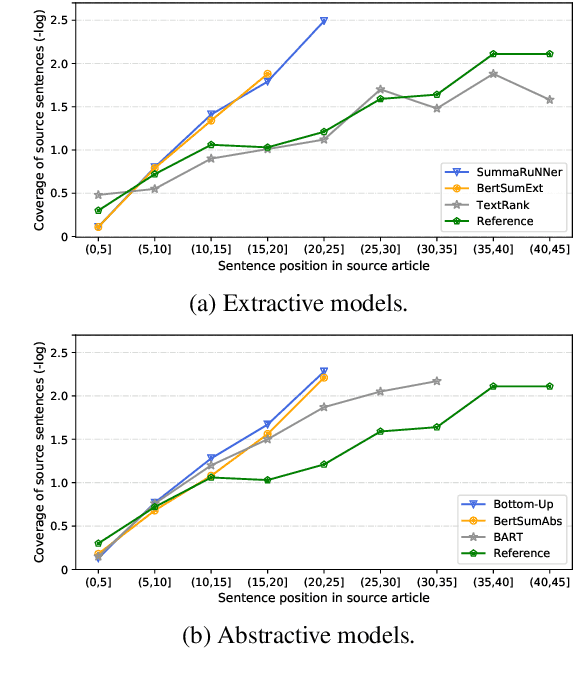
Deep learning has led to significant improvement in text summarization with various methods investigated and improved ROUGE scores reported over the years. However, gaps still exist between summaries produced by automatic summarizers and human professionals. Aiming to gain more understanding of summarization systems with respect to their strengths and limits on a fine-grained syntactic and semantic level, we consult the Multidimensional Quality Metric(MQM) and quantify 8 major sources of errors on 10 representative summarization models manually. Primarily, we find that 1) under similar settings, extractive summarizers are in general better than their abstractive counterparts thanks to strength in faithfulness and factual-consistency; 2) milestone techniques such as copy, coverage and hybrid extractive/abstractive methods do bring specific improvements but also demonstrate limitations; 3) pre-training techniques, and in particular sequence-to-sequence pre-training, are highly effective for improving text summarization, with BART giving the best results.