 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerson Re-Identification by Semantic Region Representation and Topology Constraint
Aug 20, 2018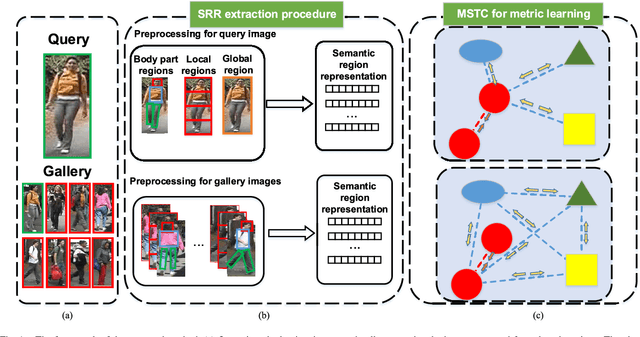



Person re-identification is a popular research topic which aims at matching the specific person in a multi-camera network automatically. Feature representation and metric learning are two important issues for person re-identification. In this paper, we propose a novel person re-identification method, which consists of a reliable representation called Semantic Region Representation (SRR), and an effective metric learning with Mapping Space Topology Constraint (MSTC). The SRR integrates semantic representations to achieve effective similarity comparison between the corresponding regions via parsing the body into multiple parts, which focuses on the foreground context against the background interference. To learn a discriminant metric, the MSTC is proposed to take into account the topological relationship among all samples in the feature space. It considers two-fold constraints: the distribution of positive pairs should be more compact than the average distribution of negative pairs with regard to the same probe, while the average distance between different classes should be larger than that between same classes. These two aspects cooperate to maintain the compactness of the intra-class as well as the sparsity of the inter-class. Extensive experiments conducted on five challenging person re-identification datasets, VIPeR, SYSU-sReID, QUML GRID, CUHK03, and Market-1501, show that the proposed method achieves competitive performance with the state-of-the-art approaches.
An Iterative Co-Saliency Framework for RGBD Images
Nov 04, 2017
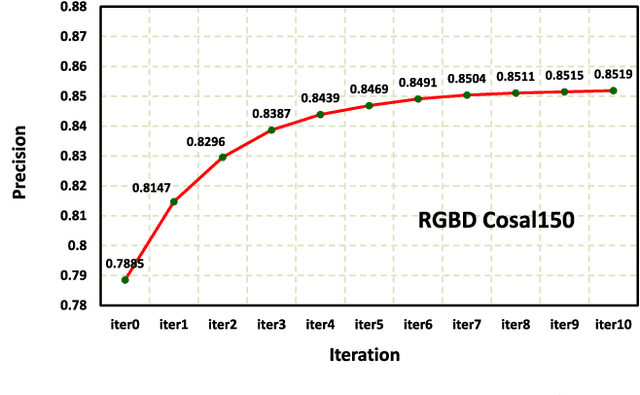
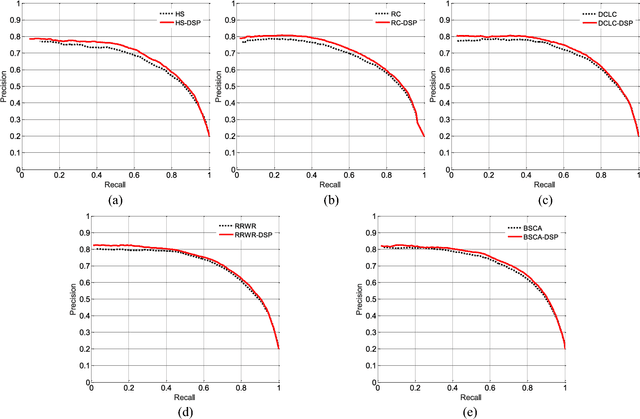
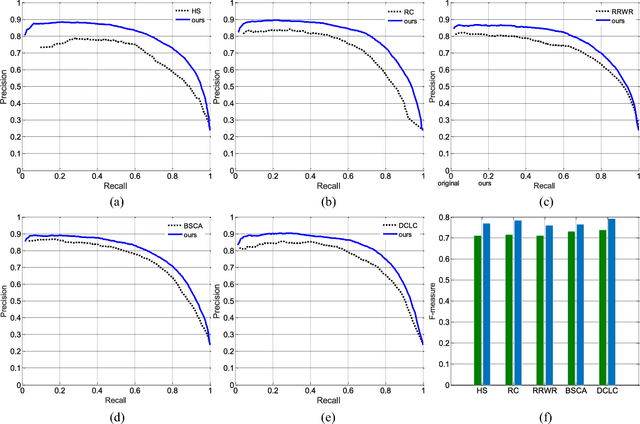
As a newly emerging and significant topic in computer vision community, co-saliency detection aims at discovering the common salient objects in multiple related images. The existing methods often generate the co-saliency map through a direct forward pipeline which is based on the designed cues or initialization, but lack the refinement-cycle scheme. Moreover, they mainly focus on RGB image and ignore the depth information for RGBD images. In this paper, we propose an iterative RGBD co-saliency framework, which utilizes the existing single saliency maps as the initialization, and generates the final RGBD cosaliency map by using a refinement-cycle model. Three schemes are employed in the proposed RGBD co-saliency framework, which include the addition scheme, deletion scheme, and iteration scheme. The addition scheme is used to highlight the salient regions based on intra-image depth propagation and saliency propagation, while the deletion scheme filters the saliency regions and removes the non-common salient regions based on interimage constraint. The iteration scheme is proposed to obtain more homogeneous and consistent co-saliency map. Furthermore, a novel descriptor, named depth shape prior, is proposed in the addition scheme to introduce the depth information to enhance identification of co-salient objects. The proposed method can effectively exploit any existing 2D saliency model to work well in RGBD co-saliency scenarios. The experiments on two RGBD cosaliency datasets demonstrate the effectiveness of our proposed framework.
Saliency Detection for Stereoscopic Images Based on Depth Confidence Analysis and Multiple Cues Fusion
Oct 14, 2017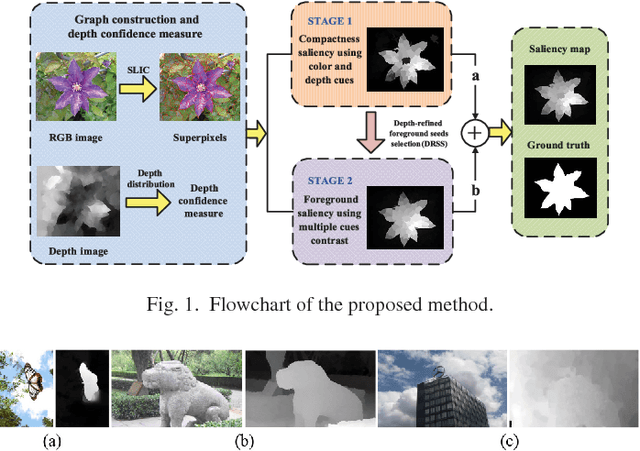
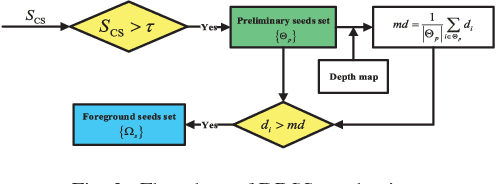
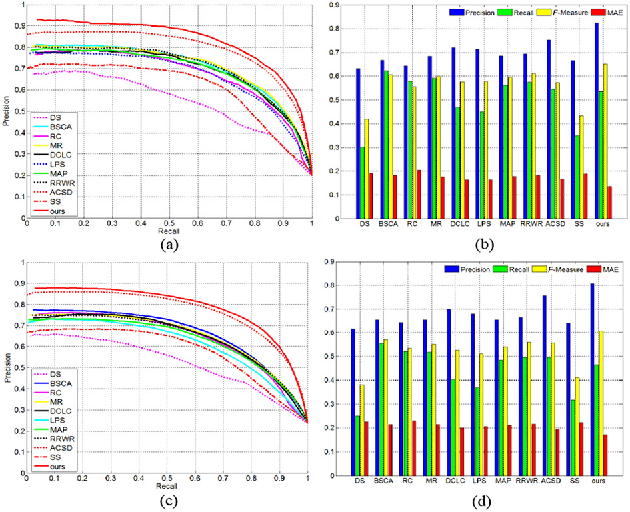
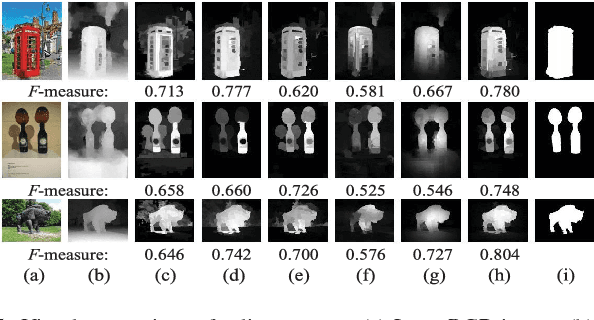
Stereoscopic perception is an important part of human visual system that allows the brain to perceive depth. However, depth information has not been well explored in existing saliency detection models. In this letter, a novel saliency detection method for stereoscopic images is proposed. Firstly, we propose a measure to evaluate the reliability of depth map, and use it to reduce the influence of poor depth map on saliency detection. Then, the input image is represented as a graph, and the depth information is introduced into graph construction. After that, a new definition of compactness using color and depth cues is put forward to compute the compactness saliency map. In order to compensate the detection errors of compactness saliency when the salient regions have similar appearances with background, foreground saliency map is calculated based on depth-refined foreground seeds selection mechanism and multiple cues contrast. Finally, these two saliency maps are integrated into a final saliency map through weighted-sum method according to their importance. Experiments on two publicly available stereo datasets demonstrate that the proposed method performs better than other 10 state-of-the-art approaches.
Co-saliency Detection for RGBD Images Based on Multi-constraint Feature Matching and Cross Label Propagation
Oct 14, 2017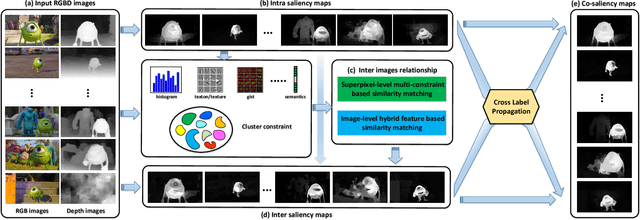


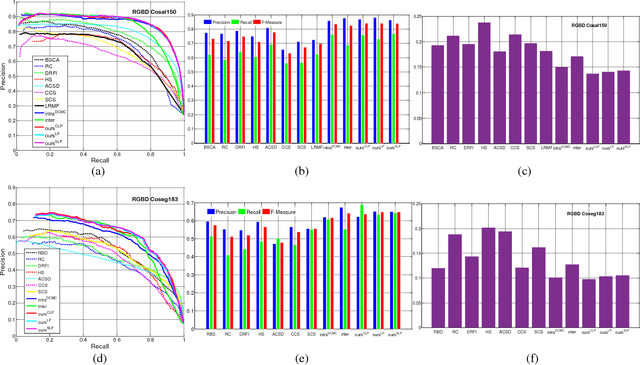
Co-saliency detection aims at extracting the common salient regions from an image group containing two or more relevant images. It is a newly emerging topic in computer vision community. Different from the most existing co-saliency methods focusing on RGB images, this paper proposes a novel co-saliency detection model for RGBD images, which utilizes the depth information to enhance identification of co-saliency. First, the intra saliency map for each image is generated by the single image saliency model, while the inter saliency map is calculated based on the multi-constraint feature matching, which represents the constraint relationship among multiple images. Then, the optimization scheme, namely Cross Label Propagation (CLP), is used to refine the intra and inter saliency maps in a cross way. Finally, all the original and optimized saliency maps are integrated to generate the final co-saliency result. The proposed method introduces the depth information and multi-constraint feature matching to improve the performance of co-saliency detection. Moreover, the proposed method can effectively exploit any existing single image saliency model to work well in co-saliency scenarios. Experiments on two RGBD co-saliency datasets demonstrate the effectiveness of our proposed model.