 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Defense: Adversarial, Traceable, and Invisible Robust Watermarking against Face Swapping
Oct 25, 2023



The malicious applications of deep forgery, represented by face swapping, have introduced security threats such as misinformation dissemination and identity fraud. While some research has proposed the use of robust watermarking methods to trace the copyright of facial images for post-event traceability, these methods cannot effectively prevent the generation of forgeries at the source and curb their dissemination. To address this problem, we propose a novel comprehensive active defense mechanism that combines traceability and adversariality, called Dual Defense. Dual Defense invisibly embeds a single robust watermark within the target face to actively respond to sudden cases of malicious face swapping. It disrupts the output of the face swapping model while maintaining the integrity of watermark information throughout the entire dissemination process. This allows for watermark extraction at any stage of image tracking for traceability. Specifically, we introduce a watermark embedding network based on original-domain feature impersonation attack. This network learns robust adversarial features of target facial images and embeds watermarks, seeking a well-balanced trade-off between watermark invisibility, adversariality, and traceability through perceptual adversarial encoding strategies. Extensive experiments demonstrate that Dual Defense achieves optimal overall defense success rates and exhibits promising universality in anti-face swapping tasks and dataset generalization ability. It maintains impressive adversariality and traceability in both original and robust settings, surpassing current forgery defense methods that possess only one of these capabilities, including CMUA-Watermark, Anti-Forgery, FakeTagger, or PGD methods.
Feature Extraction Matters More: Universal Deepfake Disruption through Attacking Ensemble Feature Extractors
Mar 01, 2023



Adversarial example is a rising way of protecting facial privacy security from deepfake modification. To prevent massive facial images from being illegally modified by various deepfake models, it is essential to design a universal deepfake disruptor. However, existing works treat deepfake disruption as an End-to-End process, ignoring the functional difference between feature extraction and image reconstruction, which makes it difficult to generate a cross-model universal disruptor. In this work, we propose a novel Feature-Output ensemble UNiversal Disruptor (FOUND) against deepfake networks, which explores a new opinion that considers attacking feature extractors as the more critical and general task in deepfake disruption. We conduct an effective two-stage disruption process. We first disrupt multi-model feature extractors through multi-feature aggregation and individual-feature maintenance, and then develop a gradient-ensemble algorithm to enhance the disruption effect by simplifying the complex optimization problem of disrupting multiple End-to-End models. Extensive experiments demonstrate that FOUND can significantly boost the disruption effect against ensemble deepfake benchmark models. Besides, our method can fast obtain a cross-attribute, cross-image, and cross-model universal deepfake disruptor with only a few training images, surpassing state-of-the-art universal disruptors in both success rate and efficiency.
Detection Defense Against Adversarial Attacks with Saliency Map
Sep 06, 2020
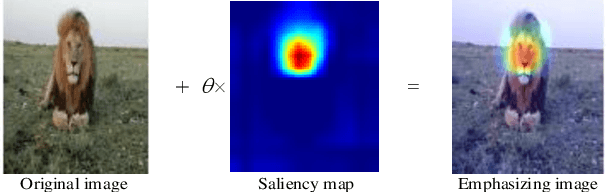
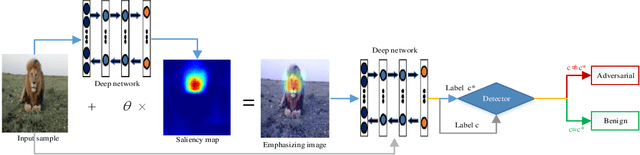

It is well established that neural networks are vulnerable to adversarial examples, which are almost imperceptible on human vision and can cause the deep models misbehave. Such phenomenon may lead to severely inestimable consequences in the safety and security critical applications. Existing defenses are trend to harden the robustness of models against adversarial attacks, e.g., adversarial training technology. However, these are usually intractable to implement due to the high cost of re-training and the cumbersome operations of altering the model architecture or parameters. In this paper, we discuss the saliency map method from the view of enhancing model interpretability, it is similar to introducing the mechanism of the attention to the model, so as to comprehend the progress of object identification by the deep networks. We then propose a novel method combined with additional noises and utilize the inconsistency strategy to detect adversarial examples. Our experimental results of some representative adversarial attacks on common datasets including ImageNet and popular models show that our method can detect all the attacks with high detection success rate effectively. We compare it with the existing state-of-the-art technique, and the experiments indicate that our method is more general.