 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection Defense Against Adversarial Attacks with Saliency Map
Sep 06, 2020
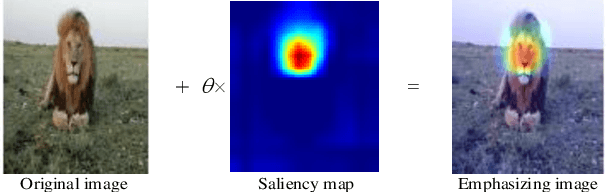
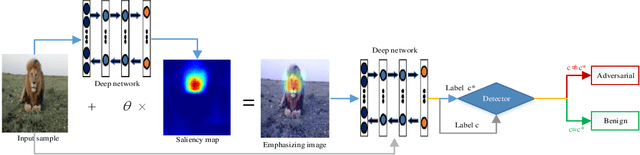

It is well established that neural networks are vulnerable to adversarial examples, which are almost imperceptible on human vision and can cause the deep models misbehave. Such phenomenon may lead to severely inestimable consequences in the safety and security critical applications. Existing defenses are trend to harden the robustness of models against adversarial attacks, e.g., adversarial training technology. However, these are usually intractable to implement due to the high cost of re-training and the cumbersome operations of altering the model architecture or parameters. In this paper, we discuss the saliency map method from the view of enhancing model interpretability, it is similar to introducing the mechanism of the attention to the model, so as to comprehend the progress of object identification by the deep networks. We then propose a novel method combined with additional noises and utilize the inconsistency strategy to detect adversarial examples. Our experimental results of some representative adversarial attacks on common datasets including ImageNet and popular models show that our method can detect all the attacks with high detection success rate effectively. We compare it with the existing state-of-the-art technique, and the experiments indicate that our method is more general.