 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Subsampling in Submodular Maximization
Apr 06, 2021
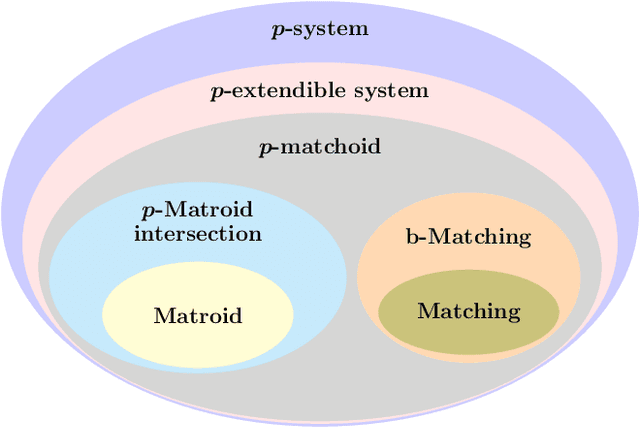

We propose subsampling as a unified algorithmic technique for submodular maximization in centralized and online settings. The idea is simple: independently sample elements from the ground set, and use simple combinatorial techniques (such as greedy or local search) on these sampled elements. We show that this approach leads to optimal/state-of-the-art results despite being much simpler than existing methods. In the usual offline setting, we present SampleGreedy, which obtains a $(p + 2 + o(1))$-approximation for maximizing a submodular function subject to a $p$-extendible system using $O(n + nk/p)$ evaluation and feasibility queries, where $k$ is the size of the largest feasible set. The approximation ratio improves to $p+1$ and $p$ for monotone submodular and linear objectives, respectively. In the streaming setting, we present SampleStreaming, which obtains a $(4p +2 - o(1))$-approximation for maximizing a submodular function subject to a $p$-matchoid using $O(k)$ memory and $O(km/p)$ evaluation and feasibility queries per element, where $m$ is the number of matroids defining the $p$-matchoid. The approximation ratio improves to $4p$ for monotone submodular objectives. We empirically demonstrate the effectiveness of our algorithms on video summarization, location summarization, and movie recommendation tasks.
Simultaneous Greedys: A Swiss Army Knife for Constrained Submodular Maximization
Sep 29, 2020
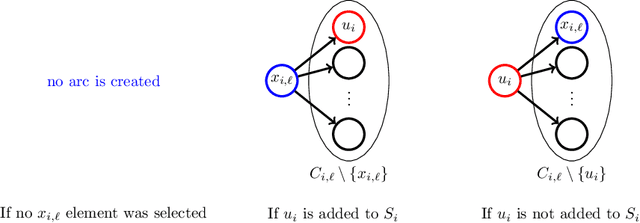
In this paper, we present SimultaneousGreedys, a deterministic algorithm for constrained submodular maximization. At a high level, the algorithm maintains $\ell$ solutions and greedily updates them in a simultaneous fashion, rather than a sequential one. SimultaneousGreedys achieves the tightest known approximation guarantees for both $k$-extendible systems and the more general $k$-systems, which are $(k+1)^2/k = k + \mathcal{O}(1)$ and $(1 + \sqrt{k+2})^2 = k + \mathcal{O}(\sqrt{k})$, respectively. This is in contrast to previous algorithms, which are designed to provide tight approximation guarantees in one setting, but not both. Furthermore, these approximation guarantees further improve to $k+1$ when the objective is monotone. We demonstrate that the algorithm may be modified to run in nearly linear time with an arbitrarily small loss in the approximation. This leads to the first nearly linear time algorithm for submodular maximization over $k$-extendible systems and $k$-systems. Finally, the technique is flexible enough to incorporate the intersection of $m$ additional knapsack constraints, while retaining similar approximation guarantees, which are roughly $k + 2m + \mathcal{O}(\sqrt{k+m})$ for $k$-systems and $k+2m + \mathcal{O}(\sqrt{m})$ for $k$-extendible systems. To complement our algorithmic contributions, we provide a hardness result which states that no algorithm making polynomially many queries to the value and independence oracles can achieve an approximation better than $k + 1/2 + \varepsilon$.
Submodular Maximization Beyond Non-negativity: Guarantees, Fast Algorithms, and Applications
Apr 19, 2019
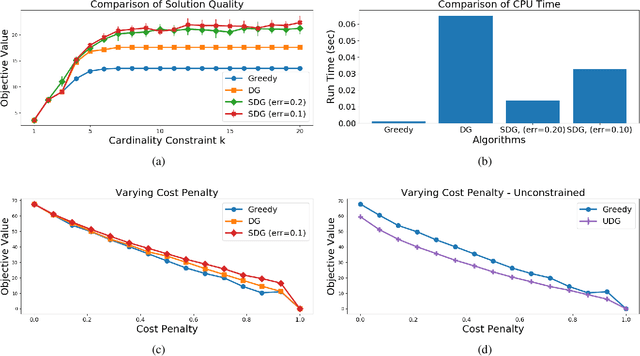
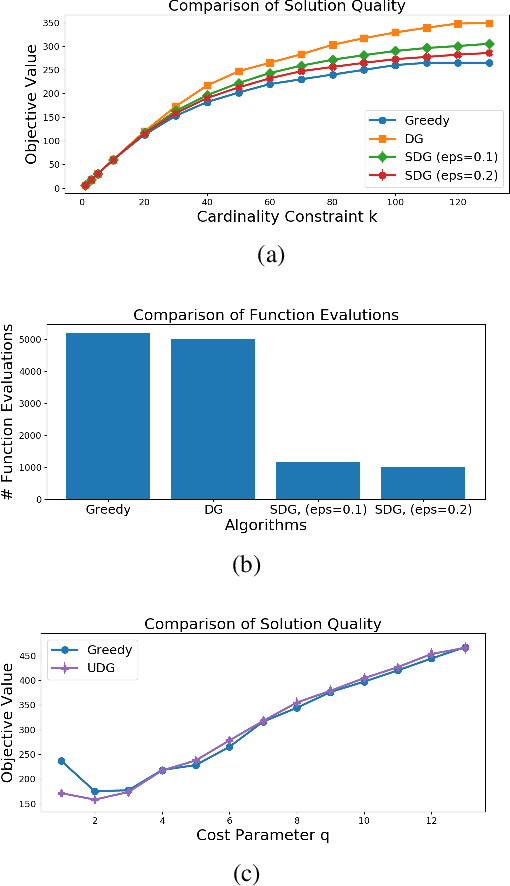
It is generally believed that submodular functions -- and the more general class of $\gamma$-weakly submodular functions -- may only be optimized under the non-negativity assumption $f(S) \geq 0$. In this paper, we show that once the function is expressed as the difference $f = g - c$, where $g$ is monotone, non-negative, and $\gamma$-weakly submodular and $c$ is non-negative modular, then strong approximation guarantees may be obtained. We present an algorithm for maximizing $g - c$ under a $k$-cardinality constraint which produces a random feasible set $S$ such that $\mathbb{E} \left[ g(S) - c(S) \right] \geq (1 - e^{-\gamma} - \epsilon) g(OPT) - c(OPT)$, whose running time is $O (\frac{n}{\epsilon} \log^2 \frac{1}{\epsilon})$, i.e., independent of $k$. We extend these results to the unconstrained setting by describing an algorithm with the same approximation guarantees and faster $O(\frac{n}{\epsilon} \log\frac{1}{\epsilon})$ runtime. The main techniques underlying our algorithms are two-fold: the use of a surrogate objective which varies the relative importance between $g$ and $c$ throughout the algorithm, and a geometric sweep over possible $\gamma$ values. Our algorithmic guarantees are complemented by a hardness result showing that no polynomial-time algorithm which accesses $g$ through a value oracle can do better. We empirically demonstrate the success of our algorithms by applying them to experimental design on the Boston Housing dataset and directed vertex cover on the Email EU dataset.
Projection-Free Online Optimization with Stochastic Gradient: From Convexity to Submodularity
Jun 14, 2018
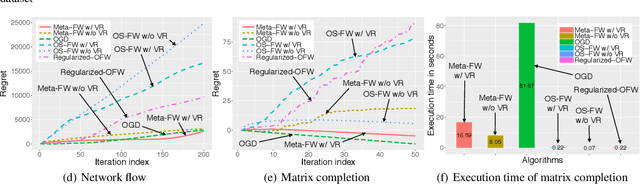
Online optimization has been a successful framework for solving large-scale problems under computational constraints and partial information. Current methods for online convex optimization require either a projection or exact gradient computation at each step, both of which can be prohibitively expensive for large-scale applications. At the same time, there is a growing trend of non-convex optimization in machine learning community and a need for online methods. Continuous DR-submodular functions, which exhibit a natural diminishing returns condition, have recently been proposed as a broad class of non-convex functions which may be efficiently optimized. Although online methods have been introduced, they suffer from similar problems. In this work, we propose Meta-Frank-Wolfe, the first online projection-free algorithm that uses stochastic gradient estimates. The algorithm relies on a careful sampling of gradients in each round and achieves the optimal $O( \sqrt{T})$ adversarial regret bounds for convex and continuous submodular optimization. We also propose One-Shot Frank-Wolfe, a simpler algorithm which requires only a single stochastic gradient estimate in each round and achieves an $O(T^{2/3})$ stochastic regret bound for convex and continuous submodular optimization. We apply our methods to develop a novel "lifting" framework for the online discrete submodular maximization and also see that they outperform current state-of-the-art techniques on various experiments.
Greed is Good: Near-Optimal Submodular Maximization via Greedy Optimization
Apr 05, 2017
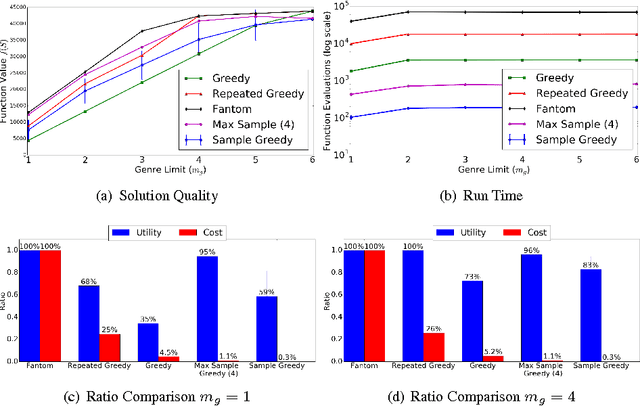

It is known that greedy methods perform well for maximizing monotone submodular functions. At the same time, such methods perform poorly in the face of non-monotonicity. In this paper, we show - arguably, surprisingly - that invoking the classical greedy algorithm $O(\sqrt{k})$-times leads to the (currently) fastest deterministic algorithm, called Repeated Greedy, for maximizing a general submodular function subject to $k$-independent system constraints. Repeated Greedy achieves $(1 + O(1/\sqrt{k}))k$ approximation using $O(nr\sqrt{k})$ function evaluations (here, $n$ and $r$ denote the size of the ground set and the maximum size of a feasible solution, respectively). We then show that by a careful sampling procedure, we can run the greedy algorithm only once and obtain the (currently) fastest randomized algorithm, called Sample Greedy, for maximizing a submodular function subject to $k$-extendible system constraints (a subclass of $k$-independent system constrains). Sample Greedy achieves $(k + 3)$-approximation with only $O(nr/k)$ function evaluations. Finally, we derive an almost matching lower bound, and show that no polynomial time algorithm can have an approximation ratio smaller than $ k + 1/2 - \varepsilon$. To further support our theoretical results, we compare the performance of Repeated Greedy and Sample Greedy with prior art in a concrete application (movie recommendation). We consistently observe that while Sample Greedy achieves practically the same utility as the best baseline, it performs at least two orders of magnitude faster.